 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-as-a-qualitative-judge: automating error analysis in natural language generation
Jun 10, 2025Prompting large language models (LLMs) to evaluate generated text, known as LLM-as-a-judge, has become a standard evaluation approach in natural language generation (NLG), but is primarily used as a quantitative tool, i.e. with numerical scores as main outputs. In this work, we propose LLM-as-a-qualitative-judge, an LLM-based evaluation approach with the main output being a structured report of common issue types in the NLG system outputs. Our approach is targeted at providing developers with meaningful insights on what improvements can be done to a given NLG system and consists of two main steps, namely open-ended per-instance issue analysis and clustering of the discovered issues using an intuitive cumulative algorithm. We also introduce a strategy for evaluating the proposed approach, coupled with ~300 annotations of issues in instances from 12 NLG datasets. Our results show that LLM-as-a-qualitative-judge correctly recognizes instance-specific issues in 2/3 cases and is capable of producing error type reports resembling the reports composed by human annotators. Our code and data are publicly available at https://github.com/tunde-ajayi/llm-as-a-qualitative-judge.
Please Translate Again: Two Simple Experiments on Whether Human-Like Reasoning Helps Translation
Jun 05, 2025
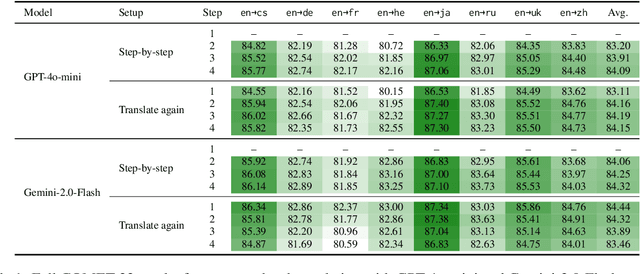


Large Language Models (LLMs) demonstrate strong reasoning capabilities for many tasks, often by explicitly decomposing the task via Chain-of-Thought (CoT) reasoning. Recent work on LLM-based translation designs hand-crafted prompts to decompose translation, or trains models to incorporate intermediate steps.~\textit{Translating Step-by-step}~\citep{briakou2024translating}, for instance, introduces a multi-step prompt with decomposition and refinement of translation with LLMs, which achieved state-of-the-art results on WMT24. In this work, we scrutinise this strategy's effectiveness. Empirically, we find no clear evidence that performance gains stem from explicitly decomposing the translation process, at least for the models on test; and we show that simply prompting LLMs to ``translate again'' yields even better results than human-like step-by-step prompting. Our analysis does not rule out the role of reasoning, but instead invites future work exploring the factors for CoT's effectiveness in the context of translation.
Masks and Mimicry: Strategic Obfuscation and Impersonation Attacks on Authorship Verification
Mar 24, 2025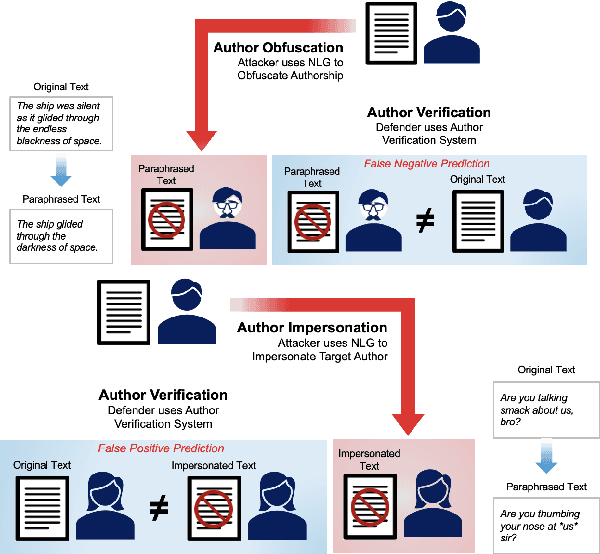

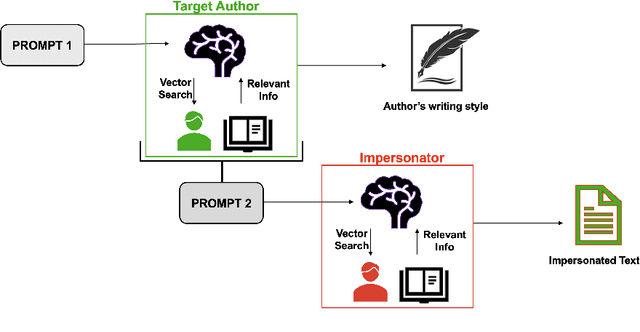
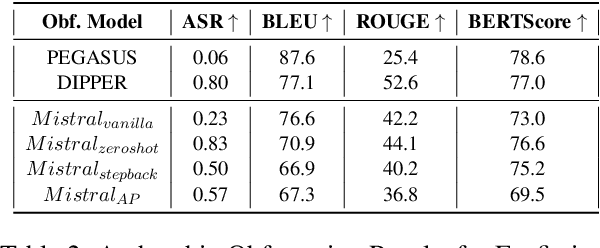
The increasing use of Artificial Intelligence (AI) technologies, such as Large Language Models (LLMs) has led to nontrivial improvements in various tasks, including accurate authorship identification of documents. However, while LLMs improve such defense techniques, they also simultaneously provide a vehicle for malicious actors to launch new attack vectors. To combat this security risk, we evaluate the adversarial robustness of authorship models (specifically an authorship verification model) to potent LLM-based attacks. These attacks include untargeted methods - \textit{authorship obfuscation} and targeted methods - \textit{authorship impersonation}. For both attacks, the objective is to mask or mimic the writing style of an author while preserving the original texts' semantics, respectively. Thus, we perturb an accurate authorship verification model, and achieve maximum attack success rates of 92\% and 78\% for both obfuscation and impersonation attacks, respectively.
Can LLMs Really Learn to Translate a Low-Resource Language from One Grammar Book?
Sep 27, 2024Extremely low-resource (XLR) languages lack substantial corpora for training NLP models, motivating the use of all available resources such as dictionaries and grammar books. Machine Translation from One Book (Tanzer et al., 2024) suggests prompting long-context LLMs with one grammar book enables English-Kalamang translation, an unseen XLR language - a noteworthy case of linguistic knowledge helping an NLP task. We investigate whether the book's grammatical explanations or its parallel examples are most effective for learning XLR translation, finding almost all improvement stems from the parallel examples. Further, we find similar results for Nepali, a seen low-resource language, and achieve performance comparable to an LLM with a grammar book by simply fine-tuning an encoder-decoder translation model. We then investigate where grammar books help by testing two linguistic tasks, grammaticality judgment and gloss prediction, and we explore what kind of grammatical knowledge helps by introducing a typological feature prompt that achieves leading results on these more relevant tasks. We thus emphasise the importance of task-appropriate data for XLR languages: parallel examples for translation, and grammatical data for linguistic tasks. As we find no evidence that long-context LLMs can make effective use of grammatical explanations for XLR translation, we suggest data collection for multilingual XLR tasks such as translation is best focused on parallel data over linguistic description.