 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasks and Mimicry: Strategic Obfuscation and Impersonation Attacks on Authorship Verification
Mar 24, 2025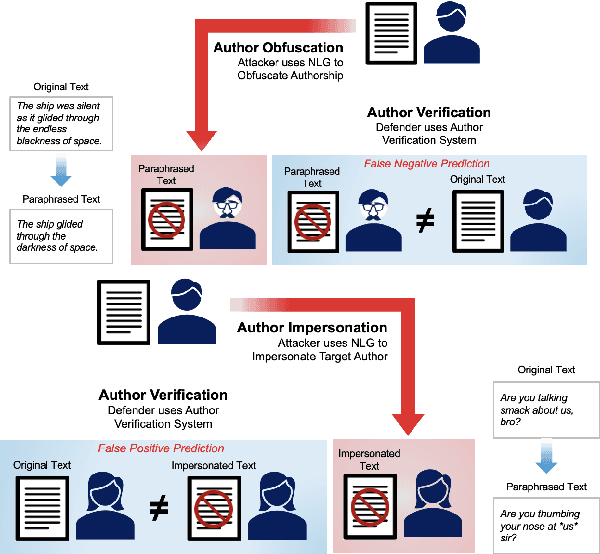

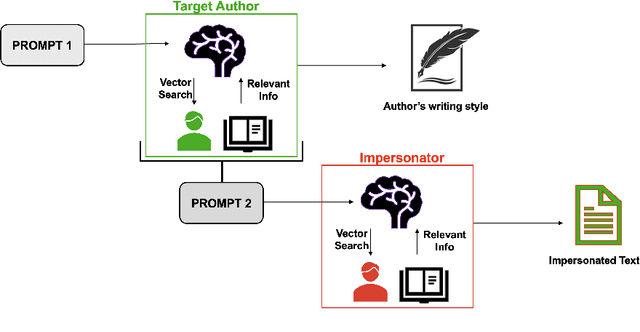
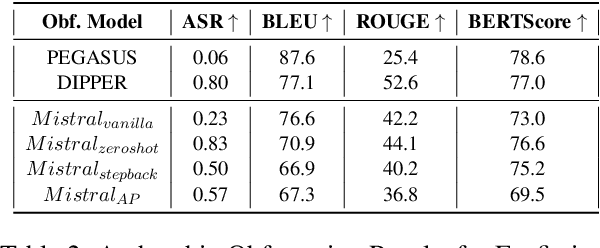
The increasing use of Artificial Intelligence (AI) technologies, such as Large Language Models (LLMs) has led to nontrivial improvements in various tasks, including accurate authorship identification of documents. However, while LLMs improve such defense techniques, they also simultaneously provide a vehicle for malicious actors to launch new attack vectors. To combat this security risk, we evaluate the adversarial robustness of authorship models (specifically an authorship verification model) to potent LLM-based attacks. These attacks include untargeted methods - \textit{authorship obfuscation} and targeted methods - \textit{authorship impersonation}. For both attacks, the objective is to mask or mimic the writing style of an author while preserving the original texts' semantics, respectively. Thus, we perturb an accurate authorship verification model, and achieve maximum attack success rates of 92\% and 78\% for both obfuscation and impersonation attacks, respectively.
How Deep Neural Networks Can Improve Emotion Recognition on Video Data
Jan 10, 2017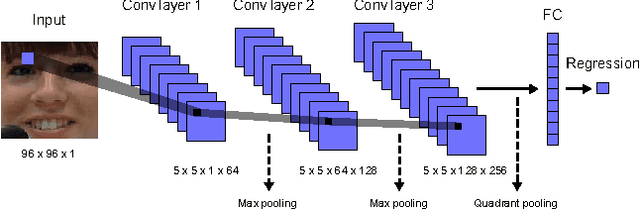
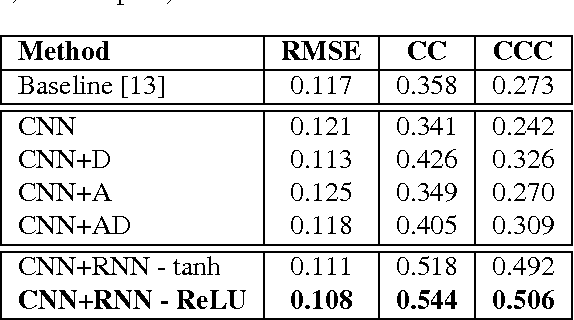
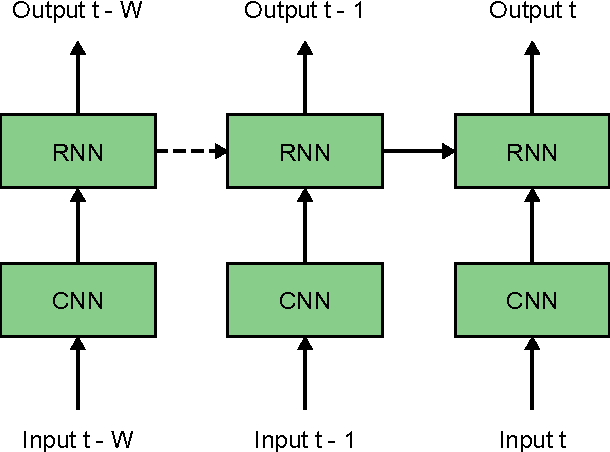
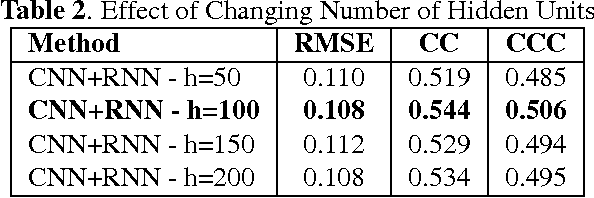
We consider the task of dimensional emotion recognition on video data using deep learning. While several previous methods have shown the benefits of training temporal neural network models such as recurrent neural networks (RNNs) on hand-crafted features, few works have considered combining convolutional neural networks (CNNs) with RNNs. In this work, we present a system that performs emotion recognition on video data using both CNNs and RNNs, and we also analyze how much each neural network component contributes to the system's overall performance. We present our findings on videos from the Audio/Visual+Emotion Challenge (AV+EC2015). In our experiments, we analyze the effects of several hyperparameters on overall performance while also achieving superior performance to the baseline and other competing methods.