 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Deep Neural Networks Can Improve Emotion Recognition on Video Data
Jan 10, 2017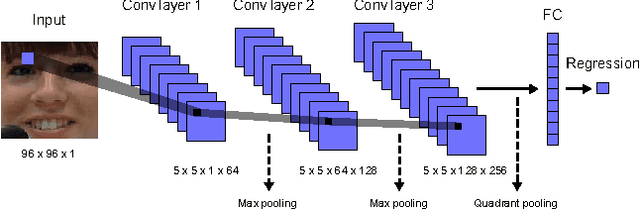
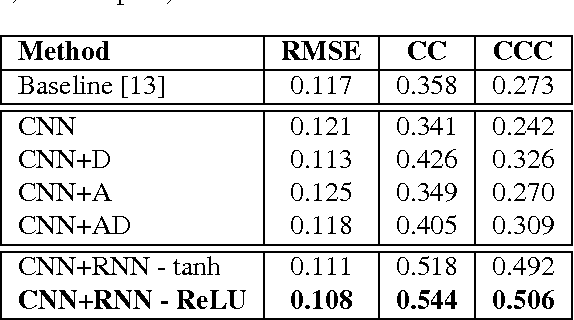
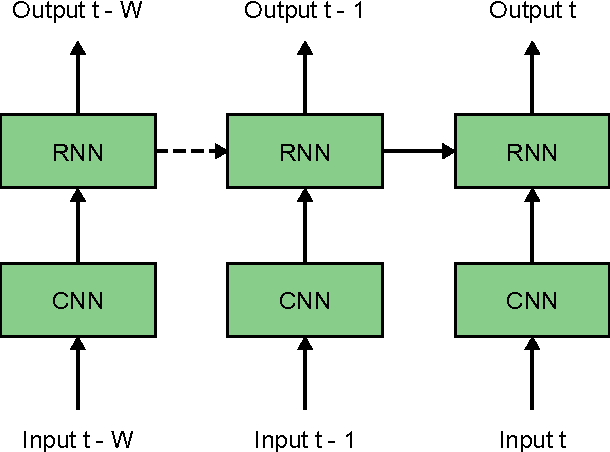
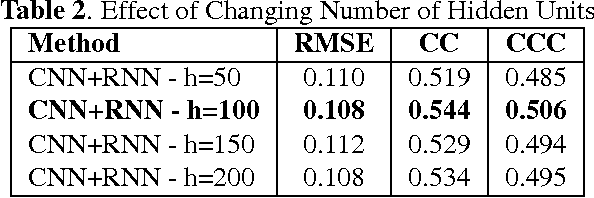
We consider the task of dimensional emotion recognition on video data using deep learning. While several previous methods have shown the benefits of training temporal neural network models such as recurrent neural networks (RNNs) on hand-crafted features, few works have considered combining convolutional neural networks (CNNs) with RNNs. In this work, we present a system that performs emotion recognition on video data using both CNNs and RNNs, and we also analyze how much each neural network component contributes to the system's overall performance. We present our findings on videos from the Audio/Visual+Emotion Challenge (AV+EC2015). In our experiments, we analyze the effects of several hyperparameters on overall performance while also achieving superior performance to the baseline and other competing methods.
Multimodal Sparse Coding for Event Detection
May 17, 2016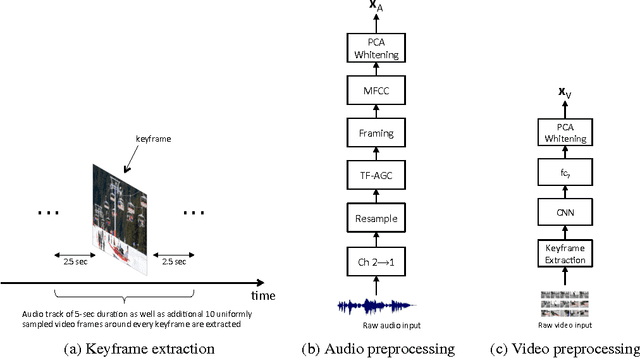
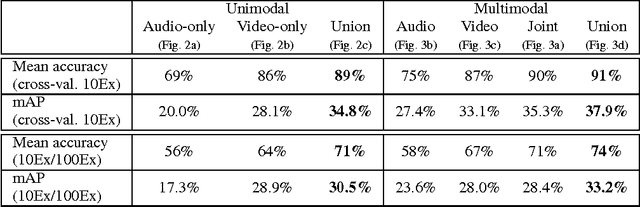
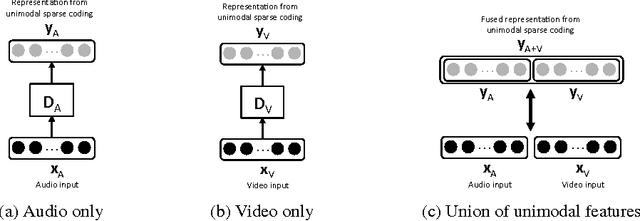
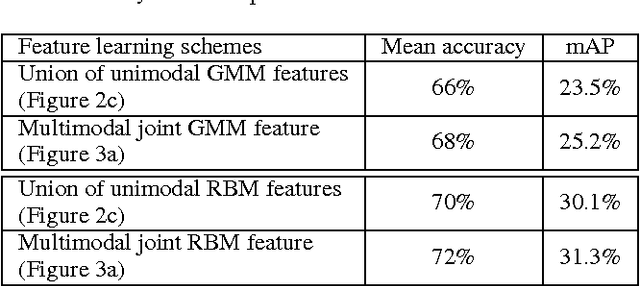
Unsupervised feature learning methods have proven effective for classification tasks based on a single modality. We present multimodal sparse coding for learning feature representations shared across multiple modalities. The shared representations are applied to multimedia event detection (MED) and evaluated in comparison to unimodal counterparts, as well as other feature learning methods such as GMM supervectors and sparse RBM. We report the cross-validated classification accuracy and mean average precision of the MED system trained on features learned from our unimodal and multimodal settings for a subset of the TRECVID MED 2014 dataset.