 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlfa: Attentive Low-Rank Filter Adaptation for Structure-Aware Cross-Domain Personalized Gaze Estimation
Mar 09, 2026Pre-trained gaze models learn to identify useful patterns commonly found across users, but subtle user-specific variations (i.e., eyelid shape or facial structure) can degrade model performance. Test-time personalization (TTP) adapts pre-trained models to these user-specific domain shifts using only a few unlabeled samples. Efficient fine-tuning is critical in performing this domain adaptation: data and computation resources can be limited-especially for on-device customization. While popular parameter-efficient fine-tuning (PEFT) methods address adaptation costs by updating only a small set of weights, they may not be taking full advantage of structures encoded in pre-trained filters. To more effectively leverage existing structures learned during pre-training, we reframe personalization as a process to reweight existing features rather than learning entirely new ones. We present Attentive Low-Rank Filter Adaptation (Alfa) to adapt gaze models by reweighting semantic patterns in pre-trained filters. With Alfa, singular value decomposition (SVD) extracts dominant spatial components that capture eye and facial characteristics across users. Via an attention mechanism, we need only a few unlabeled samples to adjust and reweight pre-trained structures, selectively amplifying those relevant to a target user. Alfa achieves the lowest average gaze errors across four cross-dataset gaze benchmarks, outperforming existing TTP methods and low-rank adaptation (LoRA)-based variants. We also show that Alfa's attentive low-rank methods can be applied to applications beyond vision, such as diffusion-based language models.
MDM: Manhattan Distance Mapping of DNN Weights for Parasitic-Resistance-Resilient Memristive Crossbars
Nov 06, 2025



Manhattan Distance Mapping (MDM) is a post-training deep neural network (DNN) weight mapping technique for memristive bit-sliced compute-in-memory (CIM) crossbars that reduces parasitic resistance (PR) nonidealities. PR limits crossbar efficiency by mapping DNN matrices into small crossbar tiles, reducing CIM-based speedup. Each crossbar executes one tile, requiring digital synchronization before the next layer. At this granularity, designers either deploy many small crossbars in parallel or reuse a few sequentially-both increasing analog-to-digital conversions, latency, I/O pressure, and chip area. MDM alleviates PR effects by optimizing active-memristor placement. Exploiting bit-level structured sparsity, it feeds activations from the denser low-order side and reorders rows according to the Manhattan distance, relocating active cells toward regions less affected by PR and thus lowering the nonideality factor (NF). Applied to DNN models on ImageNet-1k, MDM reduces NF by up to 46% and improves accuracy under analog distortion by an average of 3.6% in ResNets. Overall, it provides a lightweight, spatially informed method for scaling CIM DNN accelerators.
PQS (Prune, Quantize, and Sort): Low-Bitwidth Accumulation of Dot Products in Neural Network Computations
Apr 12, 2025We present PQS, which uses three techniques together - Prune, Quantize, and Sort - to achieve low-bitwidth accumulation of dot products in neural network computations. In conventional quantized (e.g., 8-bit) dot products, partial results are accumulated into wide (e.g., 32-bit) accumulators to avoid overflows when accumulating intermediate partial sums. However, such wide accumulators increase memory bandwidth usage and reduce energy efficiency. We show that iterative N:M pruning in floating point followed by quantization to 8 (or fewer) bits, and accumulation of partial products in a sorted order ("small to large") allows for accurate, compressed models with short dot product lengths that do not require wide accumulators. We design, analyze, and implement the PQS algorithm to eliminate accumulation overflows at inference time for several neural networks. Our method offers a 2.5x reduction in accumulator bitwidth while achieving model accuracy on par with floating-point baselines for multiple image classification tasks.
MGS: Markov Greedy Sums for Accurate Low-Bitwidth Floating-Point Accumulation
Apr 12, 2025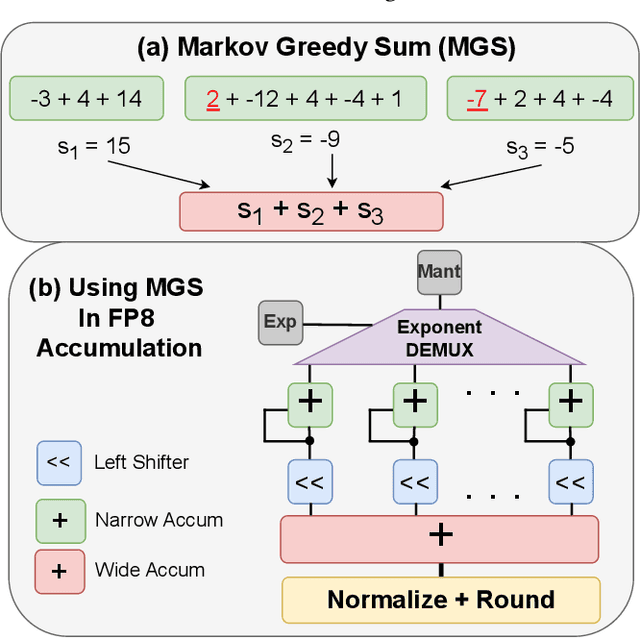

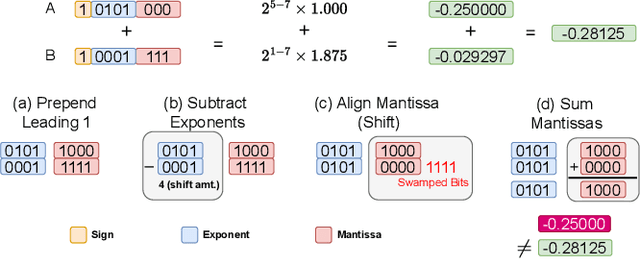
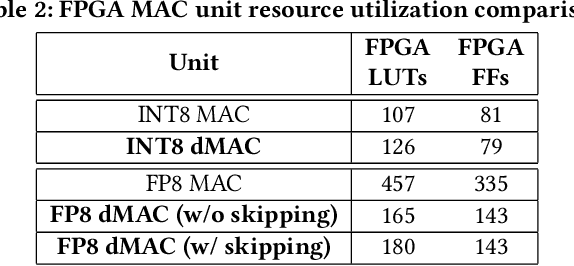
We offer a novel approach, MGS (Markov Greedy Sums), to improve the accuracy of low-bitwidth floating-point dot products in neural network computations. In conventional 32-bit floating-point summation, adding values with different exponents may lead to loss of precision in the mantissa of the smaller term, which is right-shifted to align with the larger term's exponent. Such shifting (a.k.a. 'swamping') is a significant source of numerical errors in accumulation when implementing low-bitwidth dot products (e.g., 8-bit floating point) as the mantissa has a small number of bits. We avoid most swamping errors by arranging the terms in dot product summation based on their exponents and summing the mantissas without overflowing the low-bitwidth accumulator. We design, analyze, and implement the algorithm to minimize 8-bit floating point error at inference time for several neural networks. In contrast to traditional sequential summation, our method has significantly lowered numerical errors, achieving classification accuracy on par with high-precision floating-point baselines for multiple image classification tasks. Our dMAC hardware units can reduce power consumption by up to 34.1\% relative to conventional MAC units.
ElaLoRA: Elastic & Learnable Low-Rank Adaptation for Efficient Model Fine-Tuning
Mar 31, 2025Low-Rank Adaptation (LoRA) has become a widely adopted technique for fine-tuning large-scale pre-trained models with minimal parameter updates. However, existing methods rely on fixed ranks or focus solely on either rank pruning or expansion, failing to adapt ranks dynamically to match the importance of different layers during training. In this work, we propose ElaLoRA, an adaptive low-rank adaptation framework that dynamically prunes and expands ranks based on gradient-derived importance scores. To the best of our knowledge, ElaLoRA is the first method that enables both rank pruning and expansion during fine-tuning. Experiments across multiple benchmarks demonstrate that ElaLoRA consistently outperforms existing PEFT methods across different parameter budgets. Furthermore, our studies validate that layers receiving higher rank allocations contribute more significantly to model performance, providing theoretical justification for our adaptive strategy. By introducing a principled and adaptive rank allocation mechanism, ElaLoRA offers a scalable and efficient fine-tuning solution, particularly suited for resource-constrained environments.
GazeGen: Gaze-Driven User Interaction for Visual Content Generation
Nov 07, 2024

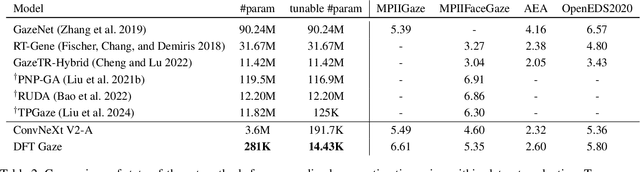
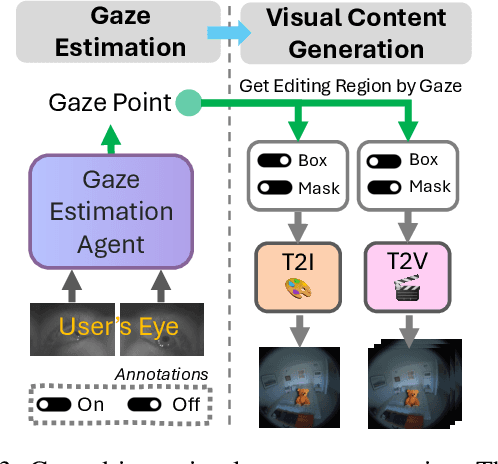
We present GazeGen, a user interaction system that generates visual content (images and videos) for locations indicated by the user's eye gaze. GazeGen allows intuitive manipulation of visual content by targeting regions of interest with gaze. Using advanced techniques in object detection and generative AI, GazeGen performs gaze-controlled image adding/deleting, repositioning, and surface material changes of image objects, and converts static images into videos. Central to GazeGen is the DFT Gaze (Distilled and Fine-Tuned Gaze) agent, an ultra-lightweight model with only 281K parameters, performing accurate real-time gaze predictions tailored to individual users' eyes on small edge devices. GazeGen is the first system to combine visual content generation with real-time gaze estimation, made possible exclusively by DFT Gaze. This real-time gaze estimation enables various visual content generation tasks, all controlled by the user's gaze. The input for DFT Gaze is the user's eye images, while the inputs for visual content generation are the user's view and the predicted gaze point from DFT Gaze. To achieve efficient gaze predictions, we derive the small model from a large model (10x larger) via novel knowledge distillation and personal adaptation techniques. We integrate knowledge distillation with a masked autoencoder, developing a compact yet powerful gaze estimation model. This model is further fine-tuned with Adapters, enabling highly accurate and personalized gaze predictions with minimal user input. DFT Gaze ensures low-latency and precise gaze tracking, supporting a wide range of gaze-driven tasks. We validate the performance of DFT Gaze on AEA and OpenEDS2020 benchmarks, demonstrating low angular gaze error and low latency on the edge device (Raspberry Pi 4). Furthermore, we describe applications of GazeGen, illustrating its versatility and effectiveness in various usage scenarios.
Efficient Reprogramming of Memristive Crossbars for DNNs: Weight Sorting and Bit Stucking
Oct 29, 2024



We introduce a novel approach to reduce the number of times required for reprogramming memristors on bit-sliced compute-in-memory crossbars for deep neural networks (DNNs). Our idea addresses the limited non-volatile memory endurance, which restrict the number of times they can be reprogrammed. To reduce reprogramming demands, we employ two techniques: (1) we organize weights into sorted sections to schedule reprogramming of similar crossbars, maximizing memristor state reuse, and (2) we reprogram only a fraction of randomly selected memristors in low-order columns, leveraging their bit-level distribution and recognizing their relatively small impact on model accuracy. We evaluate our approach for state-of-the-art models on the ImageNet-1K dataset. We demonstrate a substantial reduction in crossbar reprogramming by 3.7x for ResNet-50 and 21x for ViT-Base, while maintaining model accuracy within a 1% margin.
Sorted Weight Sectioning for Energy-Efficient Unstructured Sparse DNNs on Compute-in-Memory Crossbars
Oct 15, 2024



We introduce $\textit{sorted weight sectioning}$ (SWS): a weight allocation algorithm that places sorted deep neural network (DNN) weight sections on bit-sliced compute-in-memory (CIM) crossbars to reduce analog-to-digital converter (ADC) energy consumption. Data conversions are the most energy-intensive process in crossbar operation. SWS effectively reduces this cost leveraging (1) small weights and (2) zero weights (weight sparsity). DNN weights follow bell-shaped distributions, with most weights near zero. Using SWS, we only need low-order crossbar columns for sections with low-magnitude weights. This reduces the quantity and resolution of ADCs used, exponentially decreasing ADC energy costs without significantly degrading DNN accuracy. Unstructured sparsification further sharpens the weight distribution with small accuracy loss. However, it presents challenges in hardware tracking of zeros: we cannot switch zero rows to other layer weights in unsorted crossbars without index matching. SWS efficiently addresses unstructured sparse models using offline remapping of zeros into earlier sections, which reveals full sparsity potential and maximizes energy efficiency. Our method reduces ADC energy use by 89.5% on unstructured sparse BERT models. Overall, this paper introduces a novel algorithm to promote energy-efficient CIM crossbars for unstructured sparse DNN workloads.
DeepMachining: Online Prediction of Machining Errors of Lathe Machines
Mar 28, 2024



We describe DeepMachining, a deep learning-based AI system for online prediction of machining errors of lathe machine operations. We have built and evaluated DeepMachining based on manufacturing data from factories. Specifically, we first pretrain a deep learning model for a given lathe machine's operations to learn the salient features of machining states. Then, we fine-tune the pretrained model to adapt to specific machining tasks. We demonstrate that DeepMachining achieves high prediction accuracy for multiple tasks that involve different workpieces and cutting tools. To the best of our knowledge, this work is one of the first factory experiments using pre-trained deep-learning models to predict machining errors of lathe machines.
Gen4Gen: Generative Data Pipeline for Generative Multi-Concept Composition
Feb 23, 2024Recent text-to-image diffusion models are able to learn and synthesize images containing novel, personalized concepts (e.g., their own pets or specific items) with just a few examples for training. This paper tackles two interconnected issues within this realm of personalizing text-to-image diffusion models. First, current personalization techniques fail to reliably extend to multiple concepts -- we hypothesize this to be due to the mismatch between complex scenes and simple text descriptions in the pre-training dataset (e.g., LAION). Second, given an image containing multiple personalized concepts, there lacks a holistic metric that evaluates performance on not just the degree of resemblance of personalized concepts, but also whether all concepts are present in the image and whether the image accurately reflects the overall text description. To address these issues, we introduce Gen4Gen, a semi-automated dataset creation pipeline utilizing generative models to combine personalized concepts into complex compositions along with text-descriptions. Using this, we create a dataset called MyCanvas, that can be used to benchmark the task of multi-concept personalization. In addition, we design a comprehensive metric comprising two scores (CP-CLIP and TI-CLIP) for better quantifying the performance of multi-concept, personalized text-to-image diffusion methods. We provide a simple baseline built on top of Custom Diffusion with empirical prompting strategies for future researchers to evaluate on MyCanvas. We show that by improving data quality and prompting strategies, we can significantly increase multi-concept personalized image generation quality, without requiring any modifications to model architecture or training algorithms.