 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElaLoRA: Elastic & Learnable Low-Rank Adaptation for Efficient Model Fine-Tuning
Mar 31, 2025Low-Rank Adaptation (LoRA) has become a widely adopted technique for fine-tuning large-scale pre-trained models with minimal parameter updates. However, existing methods rely on fixed ranks or focus solely on either rank pruning or expansion, failing to adapt ranks dynamically to match the importance of different layers during training. In this work, we propose ElaLoRA, an adaptive low-rank adaptation framework that dynamically prunes and expands ranks based on gradient-derived importance scores. To the best of our knowledge, ElaLoRA is the first method that enables both rank pruning and expansion during fine-tuning. Experiments across multiple benchmarks demonstrate that ElaLoRA consistently outperforms existing PEFT methods across different parameter budgets. Furthermore, our studies validate that layers receiving higher rank allocations contribute more significantly to model performance, providing theoretical justification for our adaptive strategy. By introducing a principled and adaptive rank allocation mechanism, ElaLoRA offers a scalable and efficient fine-tuning solution, particularly suited for resource-constrained environments.
Rosko: Row Skipping Outer Products for Sparse Matrix Multiplication Kernels
Jul 08, 2023



We propose Rosko -- row skipping outer products -- for deriving sparse matrix multiplication (SpMM) kernels in reducing computation and memory access requirements of deep neural networks (DNNs). Rosko allows skipping of entire row computations during program execution with low sparsity-management overheads. We analytically derive sparse CPU kernels that adapt to given hardware characteristics to effectively utilize processor cores and minimize data movement without the need for auto-tuning or search space exploration. Rosko can be integrated with other outer product scheduling methods, allowing them to leverage row skipping by using Rosko's packing format to skip unnecessary computation. Rosko kernels outperform existing auto-tuning and search-based solutions as well as state-of-the-art vendor-optimized libraries on real hardware across a variety of neural network workloads. For matrices with sparsities ranging from 65% to 99.8% typically found in machine learning, Rosko kernels achieve up to a 6.5x runtime reduction on Intel and ARM CPUs.
MEMA Runtime Framework: Minimizing External Memory Accesses for TinyML on Microcontrollers
Apr 12, 2023


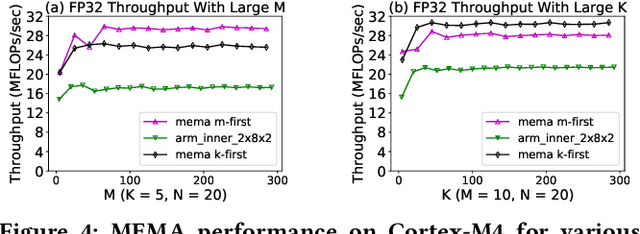
We present the MEMA framework for the easy and quick derivation of efficient inference runtimes that minimize external memory accesses for matrix multiplication on TinyML systems. The framework accounts for hardware resource constraints and problem sizes in analytically determining optimized schedules and kernels that minimize memory accesses. MEMA provides a solution to a well-known problem in the current practice, that is, optimal schedules tend to be found only through a time consuming and heuristic search of a large scheduling space. We compare the performance of runtimes derived from MEMA to existing state-of-the-art libraries on ARM-based TinyML systems. For example, for neural network benchmarks on the ARM Cortex-M4, we achieve up to a 1.8x speedup and 44% energy reduction over CMSIS-NN.