 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEMA Runtime Framework: Minimizing External Memory Accesses for TinyML on Microcontrollers
Paper and Code
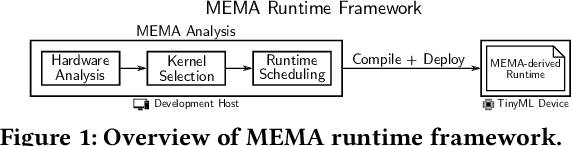


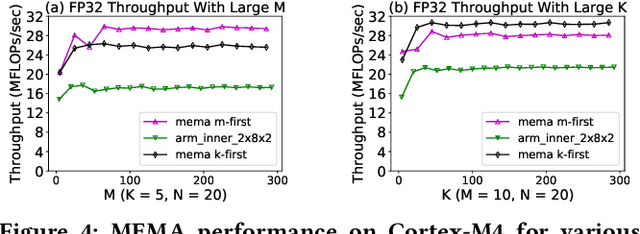
We present the MEMA framework for the easy and quick derivation of efficient inference runtimes that minimize external memory accesses for matrix multiplication on TinyML systems. The framework accounts for hardware resource constraints and problem sizes in analytically determining optimized schedules and kernels that minimize memory accesses. MEMA provides a solution to a well-known problem in the current practice, that is, optimal schedules tend to be found only through a time consuming and heuristic search of a large scheduling space. We compare the performance of runtimes derived from MEMA to existing state-of-the-art libraries on ARM-based TinyML systems. For example, for neural network benchmarks on the ARM Cortex-M4, we achieve up to a 1.8x speedup and 44% energy reduction over CMSIS-NN.