 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlow Policy Gradients for Robot Control
Feb 02, 2026Likelihood-based policy gradient methods are the dominant approach for training robot control policies from rewards. These methods rely on differentiable action likelihoods, which constrain policy outputs to simple distributions like Gaussians. In this work, we show how flow matching policy gradients -- a recent framework that bypasses likelihood computation -- can be made effective for training and fine-tuning more expressive policies in challenging robot control settings. We introduce an improved objective that enables success in legged locomotion, humanoid motion tracking, and manipulation tasks, as well as robust sim-to-real transfer on two humanoid robots. We then present ablations and analysis on training dynamics. Results show how policies can exploit the flow representation for exploration when training from scratch, as well as improved fine-tuning robustness over baselines.
Phase-Rotated Symbol Spreading for Scalable Rydberg Atomic-MIMO Detection
Jan 25, 2026Multiple-input multiple-output (MIMO) systems using Rydberg atomic (RA) receivers face significant scalability challenges in signal detection due to their nonlinear signal models. This letter proposes phase-rotated symbol spreading (PRSS), which transmits each symbol across two consecutive time slots with an optimal π/2 phase offset. PRSS enables reconstruction of an effective linear signal model while maintaining spectral efficiency and facilitating the use of conventional RF-MIMO detection algorithms. Simulation results demonstrate that PRSS achieves greater than 2.5 dB and 10 dB bit error rate improvements compared to current single-transmission methods when employing optimal exhaustive search and low-complexity sub-optimal detection methods, respectively.
Coordinated Humanoid Manipulation with Choice Policies
Dec 31, 2025Humanoid robots hold great promise for operating in human-centric environments, yet achieving robust whole-body coordination across the head, hands, and legs remains a major challenge. We present a system that combines a modular teleoperation interface with a scalable learning framework to address this problem. Our teleoperation design decomposes humanoid control into intuitive submodules, which include hand-eye coordination, grasp primitives, arm end-effector tracking, and locomotion. This modularity allows us to collect high-quality demonstrations efficiently. Building on this, we introduce Choice Policy, an imitation learning approach that generates multiple candidate actions and learns to score them. This architecture enables both fast inference and effective modeling of multimodal behaviors. We validate our approach on two real-world tasks: dishwasher loading and whole-body loco-manipulation for whiteboard wiping. Experiments show that Choice Policy significantly outperforms diffusion policies and standard behavior cloning. Furthermore, our results indicate that hand-eye coordination is critical for success in long-horizon tasks. Our work demonstrates a practical path toward scalable data collection and learning for coordinated humanoid manipulation in unstructured environments.
CUPID: Pose-Grounded Generative 3D Reconstruction from a Single Image
Oct 23, 2025This work proposes a new generation-based 3D reconstruction method, named Cupid, that accurately infers the camera pose, 3D shape, and texture of an object from a single 2D image. Cupid casts 3D reconstruction as a conditional sampling process from a learned distribution of 3D objects, and it jointly generates voxels and pixel-voxel correspondences, enabling robust pose and shape estimation under a unified generative framework. By representing both input camera poses and 3D shape as a distribution in a shared 3D latent space, Cupid adopts a two-stage flow matching pipeline: (1) a coarse stage that produces initial 3D geometry with associated 2D projections for pose recovery; and (2) a refinement stage that integrates pose-aligned image features to enhance structural fidelity and appearance details. Extensive experiments demonstrate Cupid outperforms leading 3D reconstruction methods with an over 3 dB PSNR gain and an over 10% Chamfer Distance reduction, while matching monocular estimators on pose accuracy and delivering superior visual fidelity over baseline 3D generative models. For an immersive view of the 3D results generated by Cupid, please visit cupid3d.github.io.
On the Edge of Memorization in Diffusion Models
Aug 25, 2025When do diffusion models reproduce their training data, and when are they able to generate samples beyond it? A practically relevant theoretical understanding of this interplay between memorization and generalization may significantly impact real-world deployments of diffusion models with respect to issues such as copyright infringement and data privacy. In this work, to disentangle the different factors that influence memorization and generalization in practical diffusion models, we introduce a scientific and mathematical "laboratory" for investigating these phenomena in diffusion models trained on fully synthetic or natural image-like structured data. Within this setting, we hypothesize that the memorization or generalization behavior of an underparameterized trained model is determined by the difference in training loss between an associated memorizing model and a generalizing model. To probe this hypothesis, we theoretically characterize a crossover point wherein the weighted training loss of a fully generalizing model becomes greater than that of an underparameterized memorizing model at a critical value of model (under)parameterization. We then demonstrate via carefully-designed experiments that the location of this crossover predicts a phase transition in diffusion models trained via gradient descent, validating our hypothesis. Ultimately, our theory enables us to analytically predict the model size at which memorization becomes predominant. Our work provides an analytically tractable and practically meaningful setting for future theoretical and empirical investigations. Code for our experiments is available at https://github.com/DruvPai/diffusion_mem_gen.
Deep Learning-Based Rate-Adaptive CSI Feedback for Wideband XL-MIMO Systems in the Near-Field Domain
Aug 01, 2025Accurate and efficient channel state information (CSI) feedback is crucial for unlocking the substantial spectral efficiency gains of extremely large-scale MIMO (XL-MIMO) systems in future 6G networks. However, the combination of near-field spherical wave propagation and frequency-dependent beam split effects in wideband scenarios poses significant challenges for CSI representation and compression. This paper proposes WideNLNet-CA, a rate-adaptive deep learning framework designed to enable efficient CSI feedback in wideband near-field XL-MIMO systems. WideNLNet-CA introduces a lightweight encoder-decoder architecture with multi-stage downsampling and upsampling, incorporating computationally efficient residual blocks to capture complex multi-scale channel features with reduced overhead. A novel compression ratio adaptive module with feature importance estimation is introduced to dynamically modulate feature selection based on target compression ratios, enabling flexible adaptation across a wide range of feedback rates using a single model. Evaluation results demonstrate that WideNLNet-CA consistently outperforms existing compressive sensing and deep learning-based works across various compression ratios and bandwidths, while maintaining fast inference and low model storage requirements.
Viser: Imperative, Web-based 3D Visualization in Python
Jul 30, 2025We present Viser, a 3D visualization library for computer vision and robotics. Viser aims to bring easy and extensible 3D visualization to Python: we provide a comprehensive set of 3D scene and 2D GUI primitives, which can be used independently with minimal setup or composed to build specialized interfaces. This technical report describes Viser's features, interface, and implementation. Key design choices include an imperative-style API and a web-based viewer, which improve compatibility with modern programming patterns and workflows.
LightCom: A Generative AI-Augmented Framework for QoE-Oriented Communications
Jul 23, 2025Data-intensive and immersive applications, such as virtual reality, impose stringent quality of experience (QoE) requirements that challenge traditional quality of service (QoS)-driven communication systems. This paper presents LightCom, a lightweight encoding and generative AI (GenAI)-augmented decoding framework, designed for QoE-oriented communications under low signal-to-noise ratio (SNR) conditions. LightCom simplifies transmitter design by applying basic low-pass filtering for source coding and minimal channel coding, significantly reducing processing complexity and energy consumption. At the receiver, GenAI models reconstruct high-fidelity content from highly compressed and degraded signals by leveraging generative priors to infer semantic and structural information beyond traditional decoding capabilities. The key design principles are analyzed, along with the sufficiency and error-resilience of the source representation. We also develop importance-aware power allocation strategies to enhance QoE and extend perceived coverage. Simulation results demonstrate that LightCom achieves up to a $14$ dB improvement in robustness and a $9$ dB gain in perceived coverage, outperforming traditional QoS-driven systems relying on sophisticated source and channel coding. This paradigm shift moves communication systems towards human-centric QoE metrics rather than bit-level fidelity, paving the way for more efficient and resilient wireless networks.
Leveraging Bi-Directional Channel Reciprocity for Robust Ultra-Low-Rate Implicit CSI Feedback with Deep Learning
Jul 16, 2025



Deep learning-based implicit channel state information (CSI) feedback has been introduced to enhance spectral efficiency in massive MIMO systems. Existing methods often show performance degradation in ultra-low-rate scenarios and inadaptability across diverse environments. In this paper, we propose Dual-ImRUNet, an efficient uplink-assisted deep implicit CSI feedback framework incorporating two novel plug-in preprocessing modules to achieve ultra-low feedback rates while maintaining high environmental robustness. First, a novel bi-directional correlation enhancement module is proposed to strengthen the correlation between uplink and downlink CSI eigenvector matrices. This module projects highly correlated uplink and downlink channel matrices into their respective eigenspaces, effectively reducing redundancy for ultra-low-rate feedback. Second, an innovative input format alignment module is designed to maintain consistent data distributions at both encoder and decoder sides without extra transmission overhead, thereby enhancing robustness against environmental variations. Finally, we develop an efficient transformer-based implicit CSI feedback network to exploit angular-delay domain sparsity and bi-directional correlation for ultra-low-rate CSI compression. Simulation results demonstrate successful reduction of the feedback overhead by 85% compared with the state-of-the-art method and robustness against unseen environments.
Squeeze the Soaked Sponge: Efficient Off-policy Reinforcement Finetuning for Large Language Model
Jul 09, 2025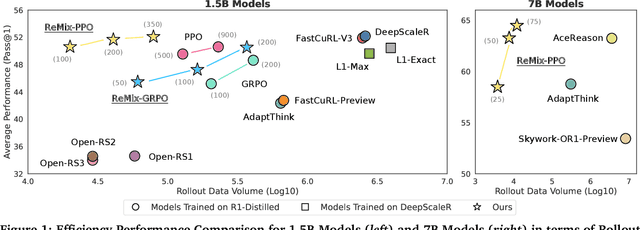
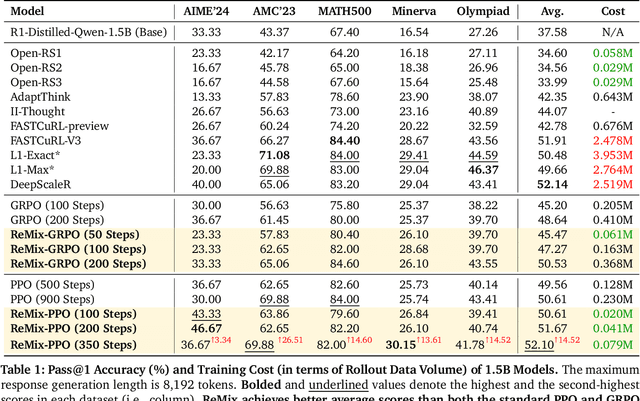
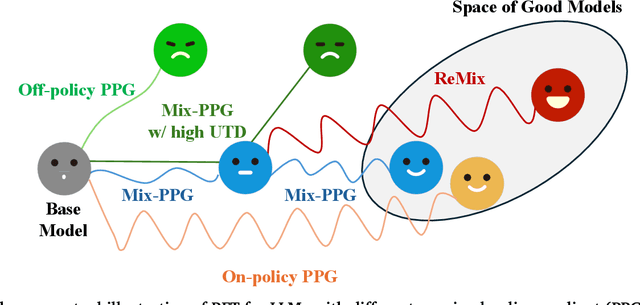
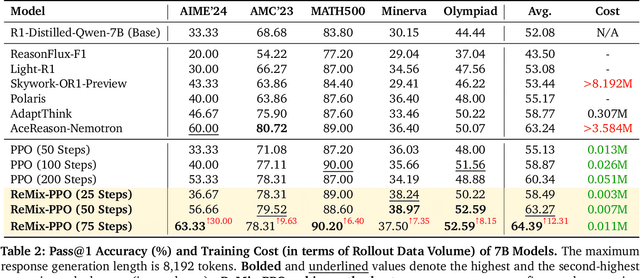
Reinforcement Learning (RL) has demonstrated its potential to improve the reasoning ability of Large Language Models (LLMs). One major limitation of most existing Reinforcement Finetuning (RFT) methods is that they are on-policy RL in nature, i.e., data generated during the past learning process is not fully utilized. This inevitably comes at a significant cost of compute and time, posing a stringent bottleneck on continuing economic and efficient scaling. To this end, we launch the renaissance of off-policy RL and propose Reincarnating Mix-policy Proximal Policy Gradient (ReMix), a general approach to enable on-policy RFT methods like PPO and GRPO to leverage off-policy data. ReMix consists of three major components: (1) Mix-policy proximal policy gradient with an increased Update-To-Data (UTD) ratio for efficient training; (2) KL-Convex policy constraint to balance the trade-off between stability and flexibility; (3) Policy reincarnation to achieve a seamless transition from efficient early-stage learning to steady asymptotic improvement. In our experiments, we train a series of ReMix models upon PPO, GRPO and 1.5B, 7B base models. ReMix shows an average Pass@1 accuracy of 52.10% (for 1.5B model) with 0.079M response rollouts, 350 training steps and achieves 63.27%/64.39% (for 7B model) with 0.007M/0.011M response rollouts, 50/75 training steps, on five math reasoning benchmarks (i.e., AIME'24, AMC'23, Minerva, OlympiadBench, and MATH500). Compared with 15 recent advanced models, ReMix shows SOTA-level performance with an over 30x to 450x reduction in training cost in terms of rollout data volume. In addition, we reveal insightful findings via multifaceted analysis, including the implicit preference for shorter responses due to the Whipping Effect of off-policy discrepancy, the collapse mode of self-reflection behavior under the presence of severe off-policyness, etc.