 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDCM: Simulated Densifying and Compensatory Modeling Fusion for Radar-Vision 3-D Object Detection in Internet of Vehicles
Jan 29, 20263-D object detection based on 4-D radar-vision is an important part in Internet of Vehicles (IoV). However, there are two challenges which need to be faced. First, the 4-D radar point clouds are sparse, leading to poor 3-D representation. Second, vision datas exhibit representation degradation under low-light, long distance detection and dense occlusion scenes, which provides unreliable texture information during fusion stage. To address these issues, a framework named SDCM is proposed, which contains Simulated Densifying and Compensatory Modeling Fusion for radar-vision 3-D object detection in IoV. Firstly, considering point generation based on Gaussian simulation of key points obtained from 3-D Kernel Density Estimation (3-D KDE), and outline generation based on curvature simulation, Simulated Densifying (SimDen) module is designed to generate dense radar point clouds. Secondly, considering that radar data could provide more real time information than vision data, due to the all-weather property of 4-D radar. Radar Compensatory Mapping (RCM) module is designed to reduce the affects of vision datas' representation degradation. Thirdly, considering that feature tensor difference values contain the effective information of every modality, which could be extracted and modeled for heterogeneity reduction and modalities interaction, Mamba Modeling Interactive Fusion (MMIF) module is designed for reducing heterogeneous and achieving interactive Fusion. Experiment results on the VoD, TJ4DRadSet and Astyx HiRes 2019 dataset show that SDCM achieves best performance with lower parameter quantity and faster inference speed. Our code will be available.
Bandwidth-Efficient Adaptive Mixture-of-Experts via Low-Rank Compensation
Dec 18, 2025



Mixture-of-Experts (MoE) models scale capacity via sparse activation but stress memory and bandwidth. Offloading alleviates GPU memory by fetching experts on demand, yet token-level routing causes irregular transfers that make inference I/O-bound. Static uniform quantization reduces traffic but degrades accuracy under aggressive compression by ignoring expert heterogeneity. We present Bandwidth-Efficient Adaptive Mixture-of-Experts via Low-Rank Compensation, which performs router-guided precision restoration using precomputed low-rank compensators. At inference time, our method transfers compact low-rank factors with Top-n (n<k) experts per token and applies compensation to them, keeping others low-bit. Integrated with offloading on GPU and GPU-NDP systems, our method delivers a superior bandwidth-accuracy trade-off and improved throughput.
Topology-Agnostic Animal Motion Generation from Text Prompt
Dec 11, 2025Motion generation is fundamental to computer animation and widely used across entertainment, robotics, and virtual environments. While recent methods achieve impressive results, most rely on fixed skeletal templates, which prevent them from generalizing to skeletons with different or perturbed topologies. We address the core limitation of current motion generation methods - the combined lack of large-scale heterogeneous animal motion data and unified generative frameworks capable of jointly modeling arbitrary skeletal topologies and textual conditions. To this end, we introduce OmniZoo, a large-scale animal motion dataset spanning 140 species and 32,979 sequences, enriched with multimodal annotations. Building on OmniZoo, we propose a generalized autoregressive motion generation framework capable of producing text-driven motions for arbitrary skeletal topologies. Central to our model is a Topology-aware Skeleton Embedding Module that encodes geometric and structural properties of any skeleton into a shared token space, enabling seamless fusion with textual semantics. Given a text prompt and a target skeleton, our method generates temporally coherent, physically plausible, and semantically aligned motions, and further enables cross-species motion style transfer.
Uni-MoE-2.0-Omni: Scaling Language-Centric Omnimodal Large Model with Advanced MoE, Training and Data
Nov 16, 2025We present Uni-MoE 2.0 from the Lychee family. As a fully open-source omnimodal large model (OLM), it substantially advances Lychee's Uni-MoE series in language-centric multimodal understanding, reasoning, and generating. Based on the Qwen2.5-7B dense architecture, we build Uni-MoE-2.0-Omni from scratch through three core contributions: dynamic-capacity Mixture-of-Experts (MoE) design, a progressive training strategy enhanced with an iterative reinforcement strategy, and a carefully curated multimodal data matching technique. It is capable of omnimodal understanding, as well as generating images, text, and speech. Architecturally, our new MoE framework balances computational efficiency and capability for 10 cross-modal inputs using shared, routed, and null experts, while our Omni-Modality 3D RoPE ensures spatio-temporal cross-modality alignment in the self-attention layer. For training, following cross-modal pretraining, we use a progressive supervised fine-tuning strategy that activates modality-specific experts and is enhanced by balanced data composition and an iterative GSPO-DPO method to stabilise RL training and improve reasoning. Data-wise, the base model, trained on approximately 75B tokens of open-source multimodal data, is equipped with special speech and image generation tokens, allowing it to learn these generative tasks by conditioning its outputs on linguistic cues. Extensive evaluation across 85 benchmarks demonstrates that our model achieves SOTA or highly competitive performance against leading OLMs, surpassing Qwen2.5-Omni (trained with 1.2T tokens) on over 50 of 76 benchmarks. Key strengths include video understanding (+7% avg. of 8), omnimodallity understanding (+7% avg. of 4), and audiovisual reasoning (+4%). It also advances long-form speech processing (reducing WER by 4.2%) and leads in low-level image processing and controllable generation across 5 metrics.
DEPF: A UAV Multispectral Object Detector with Dual-Domain Enhancement and Priority-Guided Mamba Fusion
Sep 09, 2025Multispectral remote sensing object detection is one of the important application of unmanned aerial vehicle (UAV). However, it faces three challenges. Firstly, the low-light remote sensing images reduce the complementarity during multi-modality fusion. Secondly, the local small target modeling is interfered with redundant information in the fusion stage easily. Thirdly, due to the quadratic computational complexity, it is hard to apply the transformer-based methods on the UAV platform. To address these limitations, motivated by Mamba with linear complexity, a UAV multispectral object detector with dual-domain enhancement and priority-guided mamba fusion (DEPF) is proposed. Firstly, to enhance low-light remote sensing images, Dual-Domain Enhancement Module (DDE) is designed, which contains Cross-Scale Wavelet Mamba (CSWM) and Fourier Details Recovery block (FDR). CSWM applies cross-scale mamba scanning for the low-frequency components to enhance the global brightness of images, while FDR constructs spectrum recovery network to enhance the frequency spectra features for recovering the texture-details. Secondly, to enhance local target modeling and reduce the impact of redundant information during fusion, Priority-Guided Mamba Fusion Module (PGMF) is designed. PGMF introduces the concept of priority scanning, which starts from local targets features according to the priority scores obtained from modality difference. Experiments on DroneVehicle dataset and VEDAI dataset reports that, DEPF performs well on object detection, comparing with state-of-the-art methods. Our code is available in the supplementary material.
AdaGAT: Adaptive Guidance Adversarial Training for the Robustness of Deep Neural Networks
Aug 24, 2025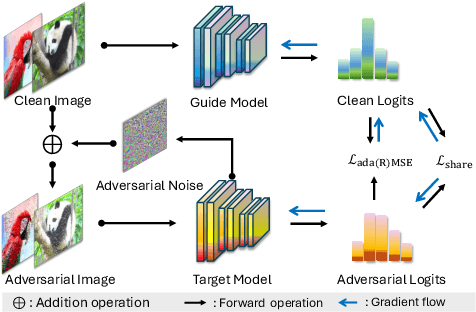
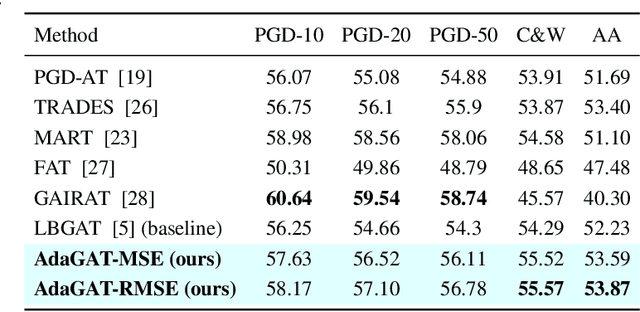
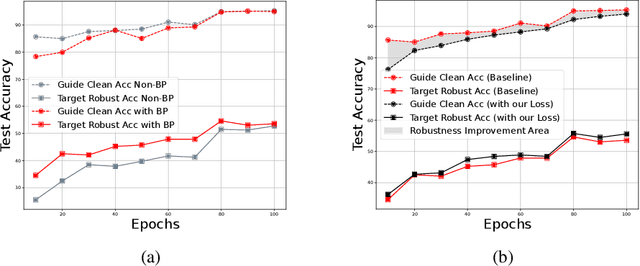
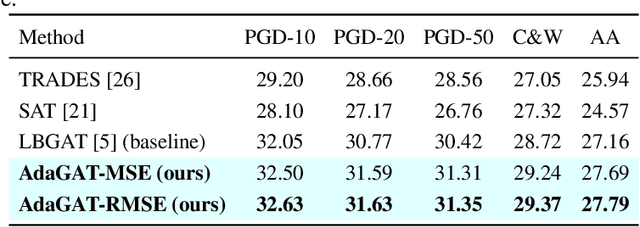
Adversarial distillation (AD) is a knowledge distillation technique that facilitates the transfer of robustness from teacher deep neural network (DNN) models to lightweight target (student) DNN models, enabling the target models to perform better than only training the student model independently. Some previous works focus on using a small, learnable teacher (guide) model to improve the robustness of a student model. Since a learnable guide model starts learning from scratch, maintaining its optimal state for effective knowledge transfer during co-training is challenging. Therefore, we propose a novel Adaptive Guidance Adversarial Training (AdaGAT) method. Our method, AdaGAT, dynamically adjusts the training state of the guide model to install robustness to the target model. Specifically, we develop two separate loss functions as part of the AdaGAT method, allowing the guide model to participate more actively in backpropagation to achieve its optimal state. We evaluated our approach via extensive experiments on three datasets: CIFAR-10, CIFAR-100, and TinyImageNet, using the WideResNet-34-10 model as the target model. Our observations reveal that appropriately adjusting the guide model within a certain accuracy range enhances the target model's robustness across various adversarial attacks compared to a variety of baseline models.
Deep Learning-Based Rate-Adaptive CSI Feedback for Wideband XL-MIMO Systems in the Near-Field Domain
Aug 01, 2025Accurate and efficient channel state information (CSI) feedback is crucial for unlocking the substantial spectral efficiency gains of extremely large-scale MIMO (XL-MIMO) systems in future 6G networks. However, the combination of near-field spherical wave propagation and frequency-dependent beam split effects in wideband scenarios poses significant challenges for CSI representation and compression. This paper proposes WideNLNet-CA, a rate-adaptive deep learning framework designed to enable efficient CSI feedback in wideband near-field XL-MIMO systems. WideNLNet-CA introduces a lightweight encoder-decoder architecture with multi-stage downsampling and upsampling, incorporating computationally efficient residual blocks to capture complex multi-scale channel features with reduced overhead. A novel compression ratio adaptive module with feature importance estimation is introduced to dynamically modulate feature selection based on target compression ratios, enabling flexible adaptation across a wide range of feedback rates using a single model. Evaluation results demonstrate that WideNLNet-CA consistently outperforms existing compressive sensing and deep learning-based works across various compression ratios and bandwidths, while maintaining fast inference and low model storage requirements.
MyGO: Make your Goals Obvious, Avoiding Semantic Confusion in Prostate Cancer Lesion Region Segmentation
Jul 23, 2025Early diagnosis and accurate identification of lesion location and progression in prostate cancer (PCa) are critical for assisting clinicians in formulating effective treatment strategies. However, due to the high semantic homogeneity between lesion and non-lesion areas, existing medical image segmentation methods often struggle to accurately comprehend lesion semantics, resulting in the problem of semantic confusion. To address this challenge, we propose a novel Pixel Anchor Module, which guides the model to discover a sparse set of feature anchors that serve to capture and interpret global contextual information. This mechanism enhances the model's nonlinear representation capacity and improves segmentation accuracy within lesion regions. Moreover, we design a self-attention-based Top_k selection strategy to further refine the identification of these feature anchors, and incorporate a focal loss function to mitigate class imbalance, thereby facilitating more precise semantic interpretation across diverse regions. Our method achieves state-of-the-art performance on the PI-CAI dataset, demonstrating 69.73% IoU and 74.32% Dice scores, and significantly improving prostate cancer lesion detection.
Leveraging Bi-Directional Channel Reciprocity for Robust Ultra-Low-Rate Implicit CSI Feedback with Deep Learning
Jul 16, 2025



Deep learning-based implicit channel state information (CSI) feedback has been introduced to enhance spectral efficiency in massive MIMO systems. Existing methods often show performance degradation in ultra-low-rate scenarios and inadaptability across diverse environments. In this paper, we propose Dual-ImRUNet, an efficient uplink-assisted deep implicit CSI feedback framework incorporating two novel plug-in preprocessing modules to achieve ultra-low feedback rates while maintaining high environmental robustness. First, a novel bi-directional correlation enhancement module is proposed to strengthen the correlation between uplink and downlink CSI eigenvector matrices. This module projects highly correlated uplink and downlink channel matrices into their respective eigenspaces, effectively reducing redundancy for ultra-low-rate feedback. Second, an innovative input format alignment module is designed to maintain consistent data distributions at both encoder and decoder sides without extra transmission overhead, thereby enhancing robustness against environmental variations. Finally, we develop an efficient transformer-based implicit CSI feedback network to exploit angular-delay domain sparsity and bi-directional correlation for ultra-low-rate CSI compression. Simulation results demonstrate successful reduction of the feedback overhead by 85% compared with the state-of-the-art method and robustness against unseen environments.
KaLM-Embedding-V2: Superior Training Techniques and Data Inspire A Versatile Embedding Model
Jun 26, 2025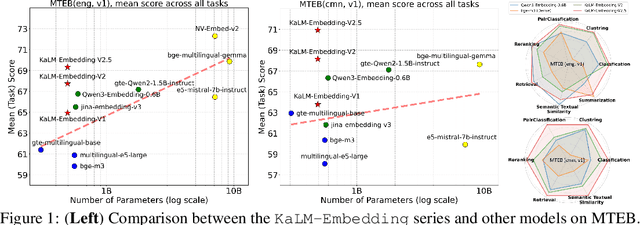


In this paper, we propose KaLM-Embedding-V2, a versatile and compact embedding model, which achieves impressive performance in general-purpose text embedding tasks by leveraging superior training techniques and data. Our key innovations include: (1) To better align the architecture with representation learning, we remove the causal attention mask and adopt a fully bidirectional transformer with simple yet effective mean-pooling to produce fixed-length embeddings; (2) We employ a multi-stage training pipeline: (i) pre-training on large-scale weakly supervised open-source corpora; (ii) fine-tuning on high-quality retrieval and non-retrieval datasets; and (iii) model-soup parameter averaging for robust generalization. Besides, we introduce a focal-style reweighting mechanism that concentrates learning on difficult samples and an online hard-negative mixing strategy to continuously enrich hard negatives without expensive offline mining; (3) We collect over 20 categories of data for pre-training and 100 categories of data for fine-tuning, to boost both the performance and generalization of the embedding model. Extensive evaluations on the Massive Text Embedding Benchmark (MTEB) Chinese and English show that our model significantly outperforms others of comparable size, and competes with 3x, 14x, 18x, and 26x larger embedding models, setting a new standard for a versatile and compact embedding model with less than 1B parameters.