 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChartE$^{3}$: A Comprehensive Benchmark for End-to-End Chart Editing
Jan 29, 2026Charts are a fundamental visualization format for structured data analysis. Enabling end-to-end chart editing according to user intent is of great practical value, yet remains challenging due to the need for both fine-grained control and global structural consistency. Most existing approaches adopt pipeline-based designs, where natural language or code serves as an intermediate representation, limiting their ability to faithfully execute complex edits. We introduce ChartE$^{3}$, an End-to-End Chart Editing benchmark that directly evaluates models without relying on intermediate natural language programs or code-level supervision. ChartE$^{3}$ focuses on two complementary editing dimensions: local editing, which involves fine-grained appearance changes such as font or color adjustments, and global editing, which requires holistic, data-centric transformations including data filtering and trend line addition. ChartE$^{3}$ contains over 1,200 high-quality samples constructed via a well-designed data pipeline with human curation. Each sample is provided as a triplet of a chart image, its underlying code, and a multimodal editing instruction, enabling evaluation from both objective and subjective perspectives. Extensive benchmarking of state-of-the-art multimodal large language models reveals substantial performance gaps, particularly on global editing tasks, highlighting critical limitations in current end-to-end chart editing capabilities.
RouteMoA: Dynamic Routing without Pre-Inference Boosts Efficient Mixture-of-Agents
Jan 26, 2026Mixture-of-Agents (MoA) improves LLM performance through layered collaboration, but its dense topology raises costs and latency. Existing methods employ LLM judges to filter responses, yet still require all models to perform inference before judging, failing to cut costs effectively. They also lack model selection criteria and struggle with large model pools, where full inference is costly and can exceed context limits. To address this, we propose RouteMoA, an efficient mixture-of-agents framework with dynamic routing. It employs a lightweight scorer to perform initial screening by predicting coarse-grained performance from the query, narrowing candidates to a high-potential subset without inference. A mixture of judges then refines these scores through lightweight self- and cross-assessment based on existing model outputs, providing posterior correction without additional inference. Finally, a model ranking mechanism selects models by balancing performance, cost, and latency. RouteMoA outperforms MoA across varying tasks and model pool sizes, reducing cost by 89.8% and latency by 63.6% in the large-scale model pool.
LexSemBridge: Fine-Grained Dense Representation Enhancement through Token-Aware Embedding Augmentation
Aug 25, 2025As queries in retrieval-augmented generation (RAG) pipelines powered by large language models (LLMs) become increasingly complex and diverse, dense retrieval models have demonstrated strong performance in semantic matching. Nevertheless, they often struggle with fine-grained retrieval tasks, where precise keyword alignment and span-level localization are required, even in cases with high lexical overlap that would intuitively suggest easier retrieval. To systematically evaluate this limitation, we introduce two targeted tasks, keyword retrieval and part-of-passage retrieval, designed to simulate practical fine-grained scenarios. Motivated by these observations, we propose LexSemBridge, a unified framework that enhances dense query representations through fine-grained, input-aware vector modulation. LexSemBridge constructs latent enhancement vectors from input tokens using three paradigms: Statistical (SLR), Learned (LLR), and Contextual (CLR), and integrates them with dense embeddings via element-wise interaction. Theoretically, we show that this modulation preserves the semantic direction while selectively amplifying discriminative dimensions. LexSemBridge operates as a plug-in without modifying the backbone encoder and naturally extends to both text and vision modalities. Extensive experiments across semantic and fine-grained retrieval tasks validate the effectiveness and generality of our approach. All code and models are publicly available at https://github.com/Jasaxion/LexSemBridge/
KaLM-Embedding-V2: Superior Training Techniques and Data Inspire A Versatile Embedding Model
Jun 26, 2025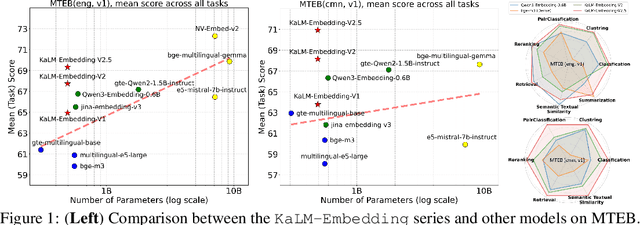
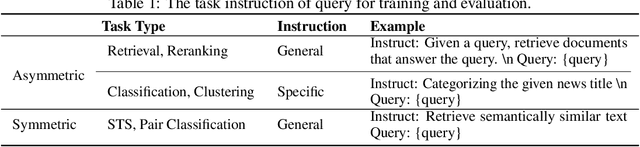


In this paper, we propose KaLM-Embedding-V2, a versatile and compact embedding model, which achieves impressive performance in general-purpose text embedding tasks by leveraging superior training techniques and data. Our key innovations include: (1) To better align the architecture with representation learning, we remove the causal attention mask and adopt a fully bidirectional transformer with simple yet effective mean-pooling to produce fixed-length embeddings; (2) We employ a multi-stage training pipeline: (i) pre-training on large-scale weakly supervised open-source corpora; (ii) fine-tuning on high-quality retrieval and non-retrieval datasets; and (iii) model-soup parameter averaging for robust generalization. Besides, we introduce a focal-style reweighting mechanism that concentrates learning on difficult samples and an online hard-negative mixing strategy to continuously enrich hard negatives without expensive offline mining; (3) We collect over 20 categories of data for pre-training and 100 categories of data for fine-tuning, to boost both the performance and generalization of the embedding model. Extensive evaluations on the Massive Text Embedding Benchmark (MTEB) Chinese and English show that our model significantly outperforms others of comparable size, and competes with 3x, 14x, 18x, and 26x larger embedding models, setting a new standard for a versatile and compact embedding model with less than 1B parameters.
DAST: Context-Aware Compression in LLMs via Dynamic Allocation of Soft Tokens
Feb 17, 2025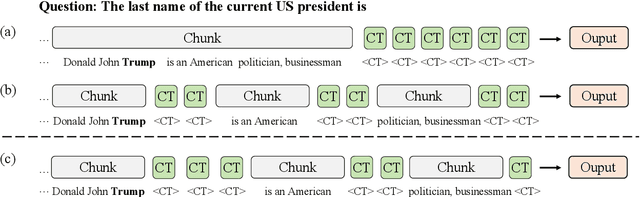
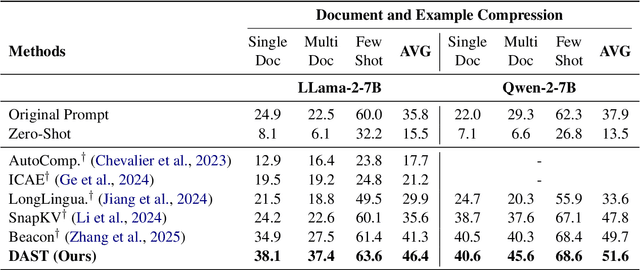
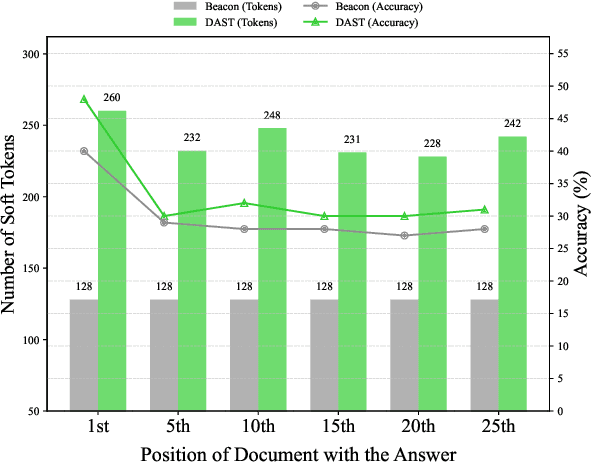
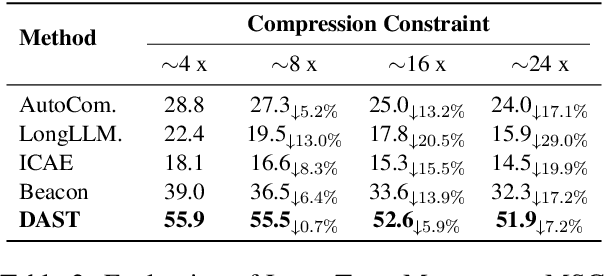
Large Language Models (LLMs) face computational inefficiencies and redundant processing when handling long context inputs, prompting a focus on compression techniques. While existing semantic vector-based compression methods achieve promising performance, these methods fail to account for the intrinsic information density variations between context chunks, instead allocating soft tokens uniformly across context chunks. This uniform distribution inevitably diminishes allocation to information-critical regions. To address this, we propose Dynamic Allocation of Soft Tokens (DAST), a simple yet effective method that leverages the LLM's intrinsic understanding of contextual relevance to guide compression. DAST combines perplexity-based local information with attention-driven global information to dynamically allocate soft tokens to the informative-rich chunks, enabling effective, context-aware compression. Experimental results across multiple benchmarks demonstrate that DAST surpasses state-of-the-art methods.
KaLM-Embedding: Superior Training Data Brings A Stronger Embedding Model
Jan 03, 2025



As retrieval-augmented generation prevails in large language models, embedding models are becoming increasingly crucial. Despite the growing number of general embedding models, prior work often overlooks the critical role of training data quality. In this work, we introduce KaLM-Embedding, a general multilingual embedding model that leverages a large quantity of cleaner, more diverse, and domain-specific training data. Our model has been trained with key techniques proven to enhance performance: (1) persona-based synthetic data to create diversified examples distilled from LLMs, (2) ranking consistency filtering to remove less informative samples, and (3) semi-homogeneous task batch sampling to improve training efficacy. Departing from traditional BERT-like architectures, we adopt Qwen2-0.5B as the pre-trained model, facilitating the adaptation of auto-regressive language models for general embedding tasks. Extensive evaluations of the MTEB benchmark across multiple languages show that our model outperforms others of comparable size, setting a new standard for multilingual embedding models with <1B parameters.
Loss-Aware Curriculum Learning for Chinese Grammatical Error Correction
Dec 31, 2024Chinese grammatical error correction (CGEC) aims to detect and correct errors in the input Chinese sentences. Recently, Pre-trained Language Models (PLMS) have been employed to improve the performance. However, current approaches ignore that correction difficulty varies across different instances and treat these samples equally, enhancing the challenge of model learning. To address this problem, we propose a multi-granularity Curriculum Learning (CL) framework. Specifically, we first calculate the correction difficulty of these samples and feed them into the model from easy to hard batch by batch. Then Instance-Level CL is employed to help the model optimize in the appropriate direction automatically by regulating the loss function. Extensive experimental results and comprehensive analyses of various datasets prove the effectiveness of our method.
B-STaR: Monitoring and Balancing Exploration and Exploitation in Self-Taught Reasoners
Dec 23, 2024



In the absence of extensive human-annotated data for complex reasoning tasks, self-improvement -- where models are trained on their own outputs -- has emerged as a primary method for enhancing performance. However, the critical factors underlying the mechanism of these iterative self-improving methods remain poorly understood, such as under what conditions self-improvement is effective, and what are the bottlenecks in the current iterations. In this work, we identify and propose methods to monitor two pivotal factors in this iterative process: (1) the model's ability to generate sufficiently diverse responses (exploration); and (2) the effectiveness of external rewards in distinguishing high-quality candidates from lower-quality ones (exploitation). Using mathematical reasoning as a case study, we begin with a quantitative analysis to track the dynamics of exploration and exploitation, discovering that a model's exploratory capabilities rapidly deteriorate over iterations, and the effectiveness of exploiting external rewards diminishes as well. Motivated by these findings, we introduce B-STaR, a Self-Taught Reasoning framework that autonomously adjusts configurations across iterations to Balance exploration and exploitation, thereby optimizing the self-improving effectiveness based on the current policy model and available rewards. Our experiments on mathematical reasoning, coding, and commonsense reasoning demonstrate that B-STaR not only enhances the model's exploratory capabilities throughout training but also achieves a more effective balance between exploration and exploitation, leading to superior performance.
Distill Visual Chart Reasoning Ability from LLMs to MLLMs
Oct 24, 2024



Solving complex chart Q&A tasks requires advanced visual reasoning abilities in multimodal large language models (MLLMs). Recent studies highlight that these abilities consist of two main parts: recognizing key information from visual inputs and conducting reasoning over it. Thus, a promising approach to enhance MLLMs is to construct relevant training data focusing on the two aspects. However, collecting and annotating complex charts and questions is costly and time-consuming, and ensuring the quality of annotated answers remains a challenge. In this paper, we propose Code-as-Intermediary Translation (CIT), a cost-effective, efficient and easily scalable data synthesis method for distilling visual reasoning abilities from LLMs to MLLMs. The code serves as an intermediary that translates visual chart representations into textual representations, enabling LLMs to understand cross-modal information. Specifically, we employ text-based synthesizing techniques to construct chart-plotting code and produce ReachQA, a dataset containing 3k reasoning-intensive charts and 20k Q&A pairs to enhance both recognition and reasoning abilities. Experiments show that when fine-tuned with our data, models not only perform well on chart-related benchmarks, but also demonstrate improved multimodal reasoning abilities on general mathematical benchmarks like MathVista. The code and dataset are publicly available at https://github.com/hewei2001/ReachQA.
Firzen: Firing Strict Cold-Start Items with Frozen Heterogeneous and Homogeneous Graphs for Recommendation
Oct 10, 2024



Recommendation models utilizing unique identities (IDs) to represent distinct users and items have dominated the recommender systems literature for over a decade. Since multi-modal content of items (e.g., texts and images) and knowledge graphs (KGs) may reflect the interaction-related users' preferences and items' characteristics, they have been utilized as useful side information to further improve the recommendation quality. However, the success of such methods often limits to either warm-start or strict cold-start item recommendation in which some items neither appear in the training data nor have any interactions in the test stage: (1) Some fail to learn the embedding of a strict cold-start item since side information is only utilized to enhance the warm-start ID representations; (2) The others deteriorate the performance of warm-start recommendation since unrelated multi-modal content or entities in KGs may blur the final representations. In this paper, we propose a unified framework incorporating multi-modal content of items and KGs to effectively solve both strict cold-start and warm-start recommendation termed Firzen, which extracts the user-item collaborative information over frozen heterogeneous graph (collaborative knowledge graph), and exploits the item-item semantic structures and user-user behavioral association over frozen homogeneous graphs (item-item relation graph and user-user co-occurrence graph). Furthermore, we build four unified strict cold-start evaluation benchmarks based on publicly available Amazon datasets and a real-world industrial dataset from Weixin Channels via rearranging the interaction data and constructing KGs. Extensive empirical results demonstrate that our model yields significant improvements for strict cold-start recommendation and outperforms or matches the state-of-the-art performance in the warm-start scenario.