 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAST: Context-Aware Compression in LLMs via Dynamic Allocation of Soft Tokens
Paper and Code
Feb 17, 2025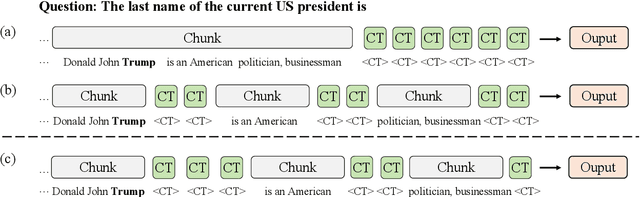
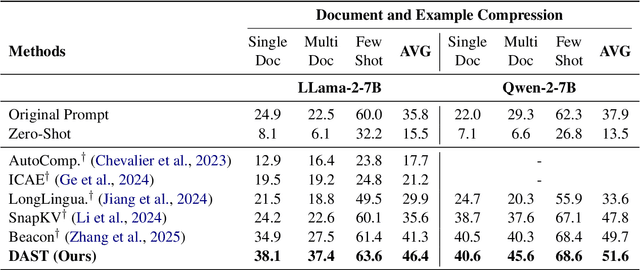
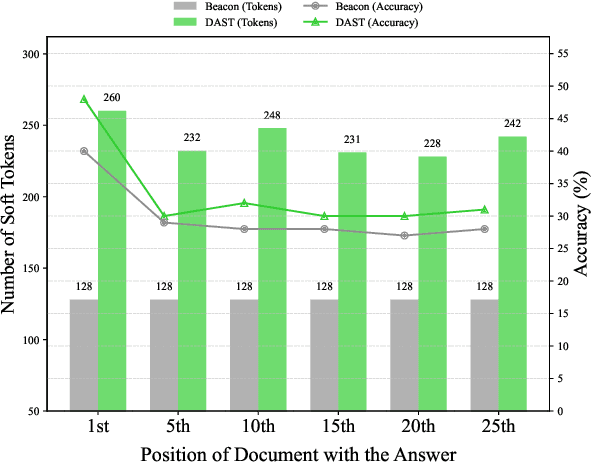
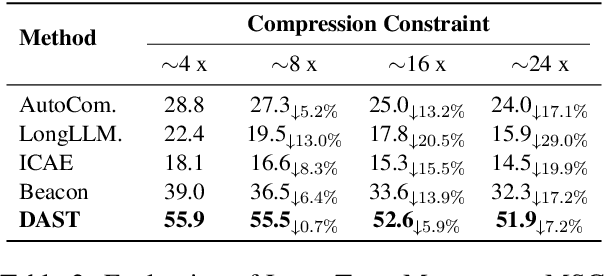
Large Language Models (LLMs) face computational inefficiencies and redundant processing when handling long context inputs, prompting a focus on compression techniques. While existing semantic vector-based compression methods achieve promising performance, these methods fail to account for the intrinsic information density variations between context chunks, instead allocating soft tokens uniformly across context chunks. This uniform distribution inevitably diminishes allocation to information-critical regions. To address this, we propose Dynamic Allocation of Soft Tokens (DAST), a simple yet effective method that leverages the LLM's intrinsic understanding of contextual relevance to guide compression. DAST combines perplexity-based local information with attention-driven global information to dynamically allocate soft tokens to the informative-rich chunks, enabling effective, context-aware compression. Experimental results across multiple benchmarks demonstrate that DAST surpasses state-of-the-art methods.