 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemoving Averaging: Personalized Lip-Sync Driven Characters Based on Identity Adapter
Mar 09, 2025



Recent advances in diffusion-based lip-syncing generative models have demonstrated their ability to produce highly synchronized talking face videos for visual dubbing. Although these models excel at lip synchronization, they often struggle to maintain fine-grained control over facial details in generated images. In this work, we identify "lip averaging" phenomenon where the model fails to preserve subtle facial details when dubbing unseen in-the-wild videos. This issue arises because the commonly used UNet backbone primarily integrates audio features into visual representations in the latent space via cross-attention mechanisms and multi-scale fusion, but it struggles to retain fine-grained lip details in the generated faces. To address this issue, we propose UnAvgLip, which extracts identity embeddings from reference videos to generate highly faithful facial sequences while maintaining accurate lip synchronization. Specifically, our method comprises two primary components: (1) an Identity Perceiver module that encodes facial embeddings to align with conditioned audio features; and (2) an ID-CrossAttn module that injects facial embeddings into the generation process, enhancing model's capability of identity retention. Extensive experiments demonstrate that, at a modest training and inference cost, UnAvgLip effectively mitigates the "averaging" phenomenon in lip inpainting, significantly preserving unique facial characteristics while maintaining precise lip synchronization. Compared with the original approach, our method demonstrates significant improvements of 5% on the identity consistency metric and 2% on the SSIM metric across two benchmark datasets (HDTF and LRW).
DAST: Context-Aware Compression in LLMs via Dynamic Allocation of Soft Tokens
Feb 17, 2025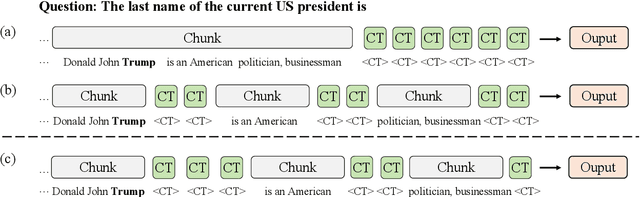
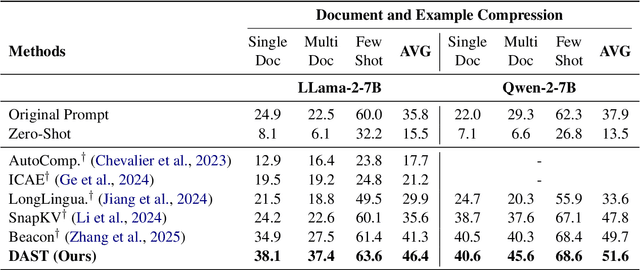
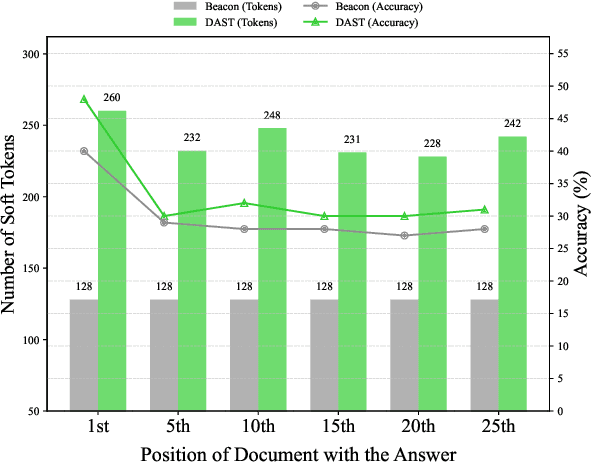
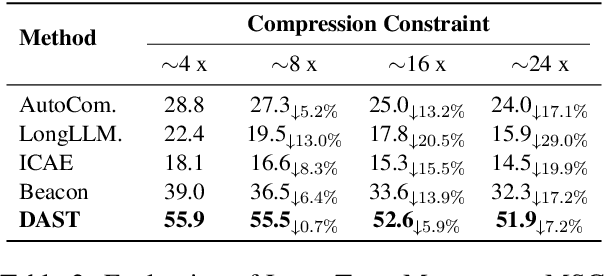
Large Language Models (LLMs) face computational inefficiencies and redundant processing when handling long context inputs, prompting a focus on compression techniques. While existing semantic vector-based compression methods achieve promising performance, these methods fail to account for the intrinsic information density variations between context chunks, instead allocating soft tokens uniformly across context chunks. This uniform distribution inevitably diminishes allocation to information-critical regions. To address this, we propose Dynamic Allocation of Soft Tokens (DAST), a simple yet effective method that leverages the LLM's intrinsic understanding of contextual relevance to guide compression. DAST combines perplexity-based local information with attention-driven global information to dynamically allocate soft tokens to the informative-rich chunks, enabling effective, context-aware compression. Experimental results across multiple benchmarks demonstrate that DAST surpasses state-of-the-art methods.
Establishing a stronger baseline for lightweight contrastive models
Dec 14, 2022



Recent research has reported a performance degradation in self-supervised contrastive learning for specially designed efficient networks, such as MobileNet and EfficientNet. A common practice to address this problem is to introduce a pretrained contrastive teacher model and train the lightweight networks with distillation signals generated by the teacher. However, it is time and resource consuming to pretrain a teacher model when it is not available. In this work, we aim to establish a stronger baseline for lightweight contrastive models without using a pretrained teacher model. Specifically, we show that the optimal recipe for efficient models is different from that of larger models, and using the same training settings as ResNet50, as previous research does, is inappropriate. Additionally, we observe a common issu e in contrastive learning where either the positive or negative views can be noisy, and propose a smoothed version of InfoNCE loss to alleviate this problem. As a result, we successfully improve the linear evaluation results from 36.3\% to 62.3\% for MobileNet-V3-Large and from 42.2\% to 65.8\% for EfficientNet-B0 on ImageNet, closing the accuracy gap to ResNet50 with $5\times$ fewer parameters. We hope our research will facilitate the usage of lightweight contrastive models.
Efficient Sub-structured Knowledge Distillation
Mar 09, 2022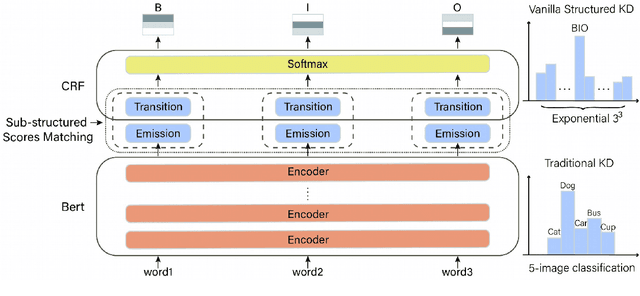
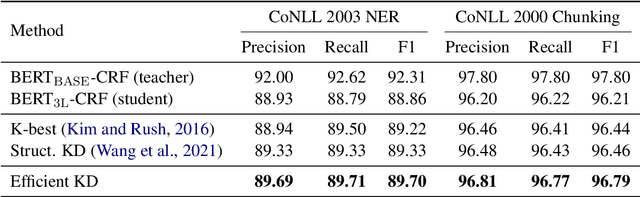

Structured prediction models aim at solving a type of problem where the output is a complex structure, rather than a single variable. Performing knowledge distillation for such models is not trivial due to their exponentially large output space. In this work, we propose an approach that is much simpler in its formulation and far more efficient for training than existing approaches. Specifically, we transfer the knowledge from a teacher model to its student model by locally matching their predictions on all sub-structures, instead of the whole output space. In this manner, we avoid adopting some time-consuming techniques like dynamic programming (DP) for decoding output structures, which permits parallel computation and makes the training process even faster in practice. Besides, it encourages the student model to better mimic the internal behavior of the teacher model. Experiments on two structured prediction tasks demonstrate that our approach outperforms previous methods and halves the time cost for one training epoch.