 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRead As Human: Compressing Context via Parallelizable Close Reading and Skimming
Feb 02, 2026Large Language Models (LLMs) demonstrate exceptional capability across diverse tasks. However, their deployment in long-context scenarios is hindered by two challenges: computational inefficiency and redundant information. We propose RAM (Read As HuMan), a context compression framework that adopts an adaptive hybrid reading strategy, to address these challenges. Inspired by human reading behavior (i.e., close reading important content while skimming less relevant content), RAM partitions the context into segments and encodes them with the input query in parallel. High-relevance segments are fully retained (close reading), while low-relevance ones are query-guided compressed into compact summary vectors (skimming). Both explicit textual segments and implicit summary vectors are concatenated and fed into decoder to achieve both superior performance and natural language format interpretability. To refine the decision boundary between close reading and skimming, we further introduce a contrastive learning objective based on positive and negative query-segment pairs. Experiments demonstrate that RAM outperforms existing baselines on multiple question answering and summarization benchmarks across two backbones, while delivering up to a 12x end-to-end speedup on long inputs (average length 16K; maximum length 32K).
COMI: Coarse-to-fine Context Compression via Marginal Information Gain
Feb 02, 2026Large Language Models (LLMs) have demonstrated exceptional capabilities across diverse tasks. However, their deployment in long context scenarios remains hindered by computational inefficiency and information redundancy. Context compression methods address these challenges by significantly reducing input length and eliminating redundancy. We propose COMI, a coarse-to-fine adaptive context compression framework that jointly optimizes for semantic relevance and diversity under high compression rates. We introduce Marginal Information Gain (MIG), a metric defined as the relevance of a unit to the input query minus its semantic redundancy with other units, guiding the compression process to prioritize information that is both relevant and low redundant. The framework operates in two stages: (1) Coarse-Grained Group Reallocation, where the context is partitioned into groups and dynamically assigned compression rates based on inter-group MIG, ensuring compression budgets align with information value distribution; and (2) Fine-Grained Token Merging, where tokens within each group are fused via an intra-group MIG-based weighting mechanism, thereby preserving key semantics while avoiding the accumulation of redundancy. Extensive experiments across question-answering (e.g., NaturalQuestions, 2WikiMQA, HotpotQA and NarrativeQA), summarization (e.g., MultiNews) with various backbones (e.g., LLaMA-2-7B, Qwen2-7B) show that COMI outperforms existing baselines by a large margin, e.g., approximately 25-point Exact Match (EM) improvement under 32x compression constraint with Qwen2-7B on NaturalQuestions.
Data Distribution Matters: A Data-Centric Perspective on Context Compression for Large Language Model
Feb 02, 2026The deployment of Large Language Models (LLMs) in long-context scenarios is hindered by computational inefficiency and significant information redundancy. Although recent advancements have widely adopted context compression to address these challenges, existing research only focus on model-side improvements, the impact of the data distribution itself on context compression remains largely unexplored. To bridge this gap, we are the first to adopt a data-centric perspective to systematically investigate how data distribution impacts compression quality, including two dimensions: input data and intrinsic data (i.e., the model's internal pretrained knowledge). We evaluate the semantic integrity of compressed representations using an autoencoder-based framework to systematically investigate it. Our experimental results reveal that: (1) encoder-measured input entropy negatively correlates with compression quality, while decoder-measured entropy shows no significant relationship under a frozen-decoder setting; and (2) the gap between intrinsic data of the encoder and decoder significantly diminishes compression gains, which is hard to mitigate. Based on these findings, we further present practical guidelines to optimize compression gains.
CoMeT: Collaborative Memory Transformer for Efficient Long Context Modeling
Feb 02, 2026The quadratic complexity and indefinitely growing key-value (KV) cache of standard Transformers pose a major barrier to long-context processing. To overcome this, we introduce the Collaborative Memory Transformer (CoMeT), a novel architecture that enables LLMs to handle arbitrarily long sequences with constant memory usage and linear time complexity. Designed as an efficient, plug-in module, CoMeT can be integrated into pre-trained models with only minimal fine-tuning. It operates on sequential data chunks, using a dual-memory system to manage context: a temporary memory on a FIFO queue for recent events, and a global memory with a gated update rule for long-range dependencies. These memories then act as a dynamic soft prompt for the next chunk. To enable efficient fine-tuning on extremely long contexts, we introduce a novel layer-level pipeline parallelism strategy. The effectiveness of our approach is remarkable: a model equipped with CoMeT and fine-tuned on 32k contexts can accurately retrieve a passkey from any position within a 1M token sequence. On the SCROLLS benchmark, CoMeT surpasses other efficient methods and achieves performance comparable to a full-attention baseline on summarization tasks. Its practical effectiveness is further validated on real-world agent and user behavior QA tasks. The code is available at: https://anonymous.4open.science/r/comet-B00B/
Length-Adaptive Interest Network for Balancing Long and Short Sequence Modeling in CTR Prediction
Jan 27, 2026User behavior sequences in modern recommendation systems exhibit significant length heterogeneity, ranging from sparse short-term interactions to rich long-term histories. While longer sequences provide more context, we observe that increasing the maximum input sequence length in existing CTR models paradoxically degrades performance for short-sequence users due to attention polarization and length imbalance in training data. To address this, we propose LAIN(Length-Adaptive Interest Network), a plug-and-play framework that explicitly incorporates sequence length as a conditioning signal to balance long- and short-sequence modeling. LAIN consists of three lightweight components: a Spectral Length Encoder that maps length into continuous representations, Length-Conditioned Prompting that injects global contextual cues into both long- and short-term behavior branches, and Length-Modulated Attention that adaptively adjusts attention sharpness based on sequence length. Extensive experiments on three real-world benchmarks across five strong CTR backbones show that LAIN consistently improves overall performance, achieving up to 1.15% AUC gain and 2.25% log loss reduction. Notably, our method significantly improves accuracy for short-sequence users without sacrificing longsequence effectiveness. Our work offers a general, efficient, and deployable solution to mitigate length-induced bias in sequential recommendation.
CoS: Towards Optimal Event Scheduling via Chain-of-Scheduling
Nov 17, 2025Recommending event schedules is a key issue in Event-based Social Networks (EBSNs) in order to maintain user activity. An effective recommendation is required to maximize the user's preference, subjecting to both time and geographical constraints. Existing methods face an inherent trade-off among efficiency, effectiveness, and generalization, due to the NP-hard nature of the problem. This paper proposes the Chain-of-Scheduling (CoS) framework, which activates the event scheduling capability of Large Language Models (LLMs) through a guided, efficient scheduling process. CoS enhances LLM by formulating the schedule task into three atomic stages, i.e., exploration, verification and integration. Then we enable the LLMs to generate CoS autonomously via Knowledge Distillation (KD). Experimental results show that CoS achieves near-theoretical optimal effectiveness with high efficiency on three real-world datasets in a interpretable manner. Moreover, it demonstrates strong zero-shot learning ability on out-of-domain data.
GMSA: Enhancing Context Compression via Group Merging and Layer Semantic Alignment
May 18, 2025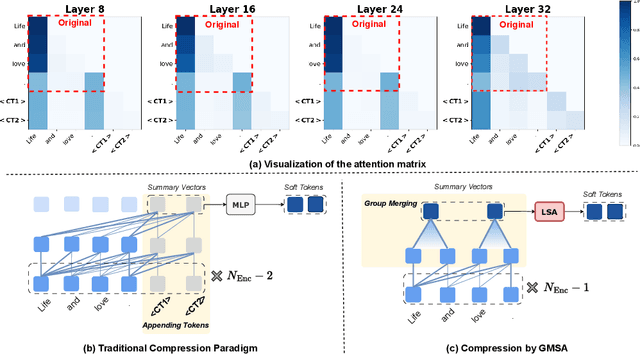
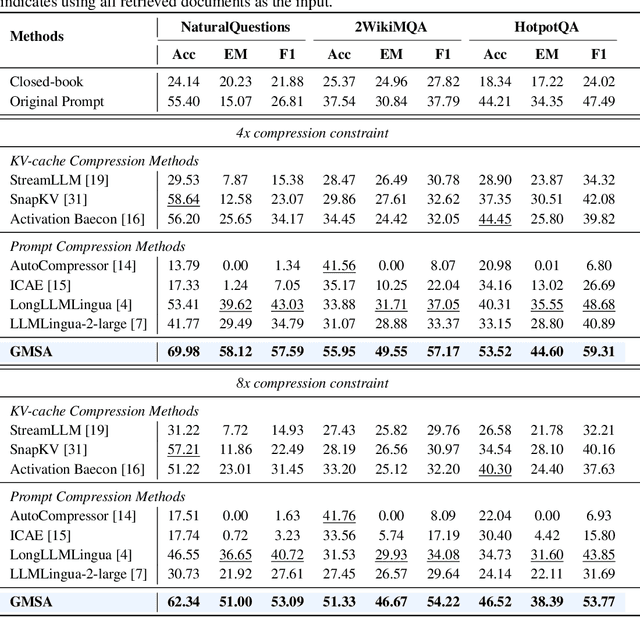
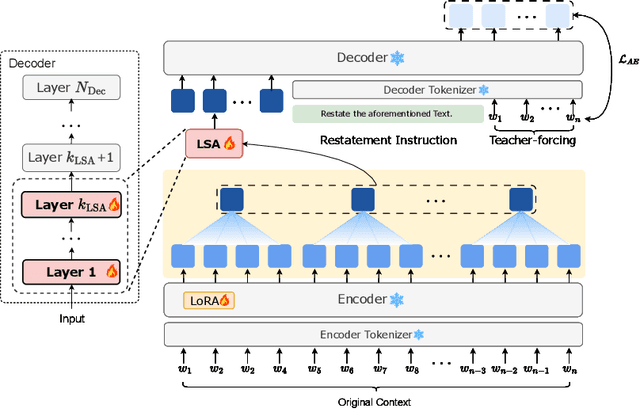

Large language models (LLMs) have achieved impressive performance in a variety of natural language processing (NLP) tasks. However, when applied to long-context scenarios, they face two challenges, i.e., low computational efficiency and much redundant information. This paper introduces GMSA, a context compression framework based on the encoder-decoder architecture, which addresses these challenges by reducing input sequence length and redundant information. Structurally, GMSA has two key components: Group Merging and Layer Semantic Alignment (LSA). Group merging is used to effectively and efficiently extract summary vectors from the original context. Layer semantic alignment, on the other hand, aligns the high-level summary vectors with the low-level primary input semantics, thus bridging the semantic gap between different layers. In the training process, GMSA first learns soft tokens that contain complete semantics through autoencoder training. To furtherly adapt GMSA to downstream tasks, we propose Knowledge Extraction Fine-tuning (KEFT) to extract knowledge from the soft tokens for downstream tasks. We train GMSA by randomly sampling the compression rate for each sample in the dataset. Under this condition, GMSA not only significantly outperforms the traditional compression paradigm in context restoration but also achieves stable and significantly faster convergence with only a few encoder layers. In downstream question-answering (QA) tasks, GMSA can achieve approximately a 2x speedup in end-to-end inference while outperforming both the original input prompts and various state-of-the-art (SOTA) methods by a large margin.
Never too Cocky to Cooperate: An FIM and RL-based USV-AUV Collaborative System for Underwater Tasks in Extreme Sea Conditions
Apr 21, 2025



This paper develops a novel unmanned surface vehicle (USV)-autonomous underwater vehicle (AUV) collaborative system designed to enhance underwater task performance in extreme sea conditions. The system integrates a dual strategy: (1) high-precision multi-AUV localization enabled by Fisher information matrix-optimized USV path planning, and (2) reinforcement learning-based cooperative planning and control method for multi-AUV task execution. Extensive experimental evaluations in the underwater data collection task demonstrate the system's operational feasibility, with quantitative results showing significant performance improvements over baseline methods. The proposed system exhibits robust coordination capabilities between USV and AUVs while maintaining stability in extreme sea conditions. To facilitate reproducibility and community advancement, we provide an open-source simulation toolkit available at: https://github.com/360ZMEM/USV-AUV-colab .
From Token to Line: Enhancing Code Generation with a Long-Term Perspective
Apr 10, 2025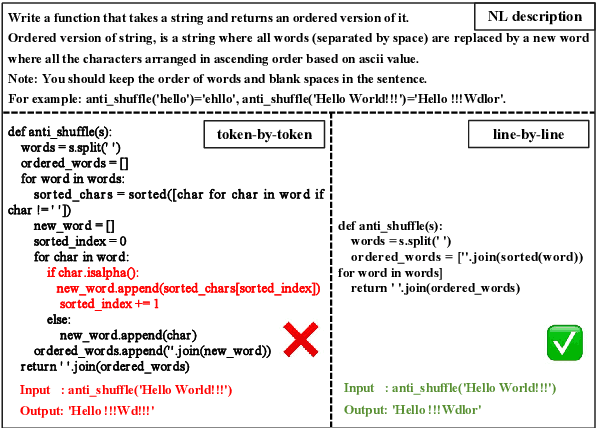
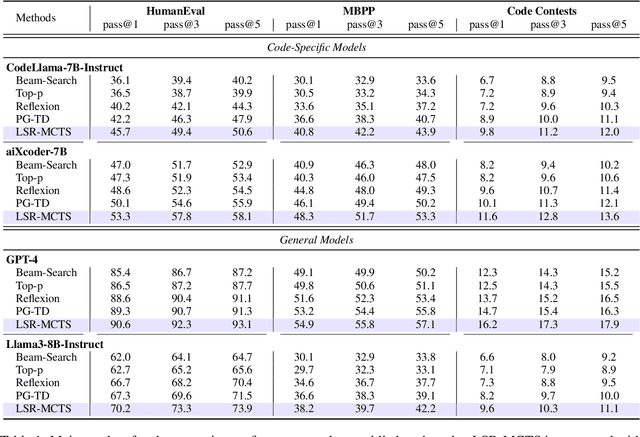
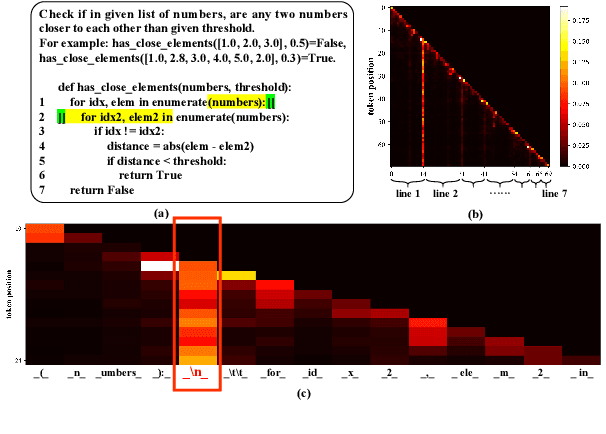
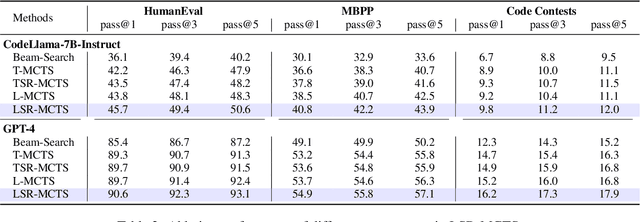
The emergence of large language models (LLMs) has significantly promoted the development of code generation task, sparking a surge in pertinent literature. Current research is hindered by redundant generation results and a tendency to overfit local patterns in the short term. Although existing studies attempt to alleviate the issue by adopting a multi-token prediction strategy, there remains limited focus on choosing the appropriate processing length for generations. By analyzing the attention between tokens during the generation process of LLMs, it can be observed that the high spikes of the attention scores typically appear at the end of lines. This insight suggests that it is reasonable to treat each line of code as a fundamental processing unit and generate them sequentially. Inspired by this, we propose the \textbf{LSR-MCTS} algorithm, which leverages MCTS to determine the code line-by-line and select the optimal path. Further, we integrate a self-refine mechanism at each node to enhance diversity and generate higher-quality programs through error correction. Extensive experiments and comprehensive analyses on three public coding benchmarks demonstrate that our method outperforms the state-of-the-art performance approaches.
RAISE: Reinforenced Adaptive Instruction Selection For Large Language Models
Apr 09, 2025In the instruction fine-tuning of large language models (LLMs), it has become a consensus that a few high-quality instructions are superior to a large number of low-quality instructions. At present, many instruction selection methods have been proposed, but most of these methods select instruction based on heuristic quality metrics, and only consider data selection before training. These designs lead to insufficient optimization of instruction fine-tuning, and fixed heuristic indicators are often difficult to optimize for specific tasks. So we designed a dynamic, task-objective-driven instruction selection framework RAISE(Reinforenced Adaptive Instruction SElection), which incorporates the entire instruction fine-tuning process into optimization, selecting instruction at each step based on the expected impact of instruction on model performance improvement. Our approach is well interpretable and has strong task-specific optimization capabilities. By modeling dynamic instruction selection as a sequential decision-making process, we use RL to train our selection strategy. Extensive experiments and result analysis prove the superiority of our method compared with other instruction selection methods. Notably, RAISE achieves superior performance by updating only 1\% of the training steps compared to full-data training, demonstrating its efficiency and effectiveness.