 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode Copycat Conundrum: Demystifying Repetition in LLM-based Code Generation
Apr 17, 2025Despite recent advances in Large Language Models (LLMs) for code generation, the quality of LLM-generated code still faces significant challenges. One significant issue is code repetition, which refers to the model's tendency to generate structurally redundant code, resulting in inefficiencies and reduced readability. To address this, we conduct the first empirical study to investigate the prevalence and nature of repetition across 19 state-of-the-art code LLMs using three widely-used benchmarks. Our study includes both quantitative and qualitative analyses, revealing that repetition is pervasive and manifests at various granularities and extents, including character, statement, and block levels. We further summarize a taxonomy of 20 repetition patterns. Building on our findings, we propose DeRep, a rule-based technique designed to detect and mitigate repetition in generated code. We evaluate DeRep using both open-source benchmarks and in an industrial setting. Our results demonstrate that DeRep significantly outperforms baselines in reducing repetition (with an average improvements of 91.3%, 93.5%, and 79.9% in rep-3, rep-line, and sim-line metrics) and enhancing code quality (with a Pass@1 increase of 208.3% over greedy search). Furthermore, integrating DeRep improves the performance of existing repetition mitigation methods, with Pass@1 improvements ranging from 53.7% to 215.7%.
From Token to Line: Enhancing Code Generation with a Long-Term Perspective
Apr 10, 2025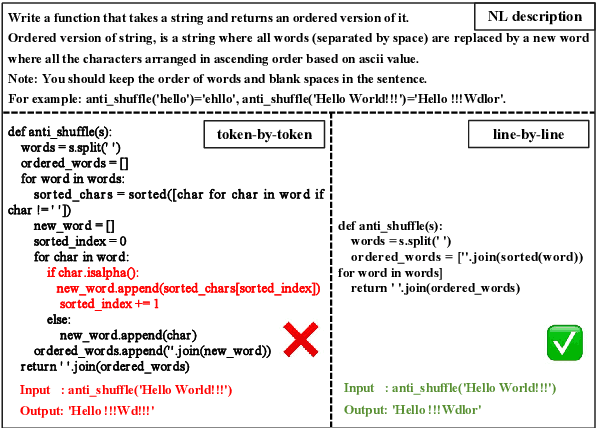
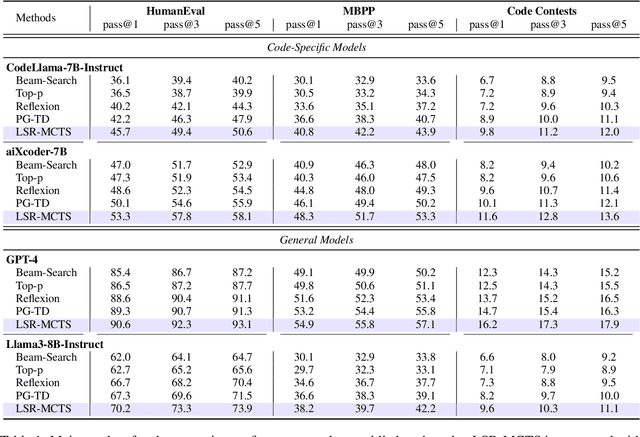
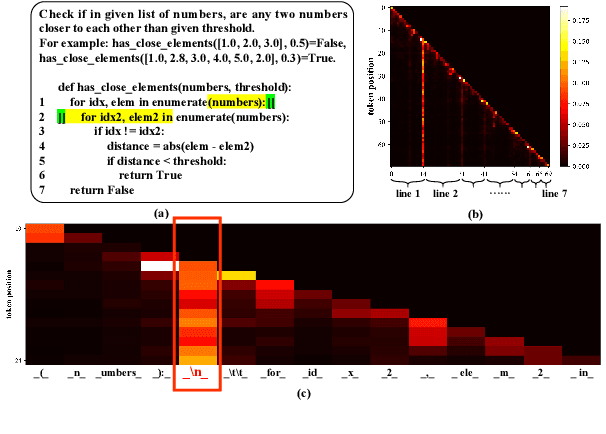
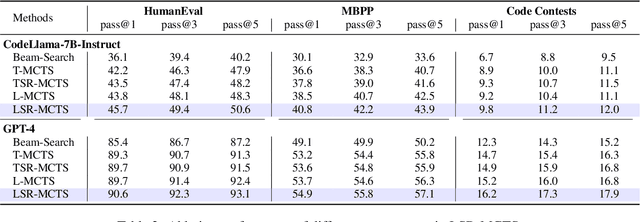
The emergence of large language models (LLMs) has significantly promoted the development of code generation task, sparking a surge in pertinent literature. Current research is hindered by redundant generation results and a tendency to overfit local patterns in the short term. Although existing studies attempt to alleviate the issue by adopting a multi-token prediction strategy, there remains limited focus on choosing the appropriate processing length for generations. By analyzing the attention between tokens during the generation process of LLMs, it can be observed that the high spikes of the attention scores typically appear at the end of lines. This insight suggests that it is reasonable to treat each line of code as a fundamental processing unit and generate them sequentially. Inspired by this, we propose the \textbf{LSR-MCTS} algorithm, which leverages MCTS to determine the code line-by-line and select the optimal path. Further, we integrate a self-refine mechanism at each node to enhance diversity and generate higher-quality programs through error correction. Extensive experiments and comprehensive analyses on three public coding benchmarks demonstrate that our method outperforms the state-of-the-art performance approaches.
Revisiting Classification Taxonomy for Grammatical Errors
Feb 18, 2025Grammatical error classification plays a crucial role in language learning systems, but existing classification taxonomies often lack rigorous validation, leading to inconsistencies and unreliable feedback. In this paper, we revisit previous classification taxonomies for grammatical errors by introducing a systematic and qualitative evaluation framework. Our approach examines four aspects of a taxonomy, i.e., exclusivity, coverage, balance, and usability. Then, we construct a high-quality grammatical error classification dataset annotated with multiple classification taxonomies and evaluate them grounding on our proposed evaluation framework. Our experiments reveal the drawbacks of existing taxonomies. Our contributions aim to improve the precision and effectiveness of error analysis, providing more understandable and actionable feedback for language learners.