 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiSegMan: Interactive Segment-and-Manipulate 3D Gaussians
May 17, 2025The efficient rendering and explicit nature of 3DGS promote the advancement of 3D scene manipulation. However, existing methods typically encounter challenges in controlling the manipulation region and are unable to furnish the user with interactive feedback, which inevitably leads to unexpected results. Intuitively, incorporating interactive 3D segmentation tools can compensate for this deficiency. Nevertheless, existing segmentation frameworks impose a pre-processing step of scene-specific parameter training, which limits the efficiency and flexibility of scene manipulation. To deliver a 3D region control module that is well-suited for scene manipulation with reliable efficiency, we propose interactive Segment-and-Manipulate 3D Gaussians (iSegMan), an interactive segmentation and manipulation framework that only requires simple 2D user interactions in any view. To propagate user interactions to other views, we propose Epipolar-guided Interaction Propagation (EIP), which innovatively exploits epipolar constraint for efficient and robust interaction matching. To avoid scene-specific training to maintain efficiency, we further propose the novel Visibility-based Gaussian Voting (VGV), which obtains 2D segmentations from SAM and models the region extraction as a voting game between 2D Pixels and 3D Gaussians based on Gaussian visibility. Taking advantage of the efficient and precise region control of EIP and VGV, we put forth a Manipulation Toolbox to implement various functions on selected regions, enhancing the controllability, flexibility and practicality of scene manipulation. Extensive results on 3D scene manipulation and segmentation tasks fully demonstrate the significant advantages of iSegMan. Project page is available at https://zhao-yian.github.io/iSegMan.
From Token to Line: Enhancing Code Generation with a Long-Term Perspective
Apr 10, 2025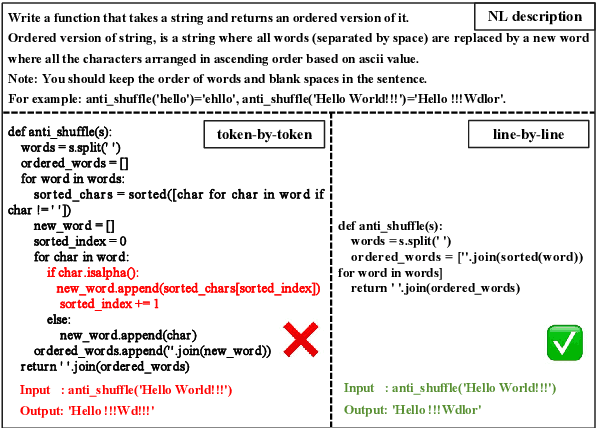
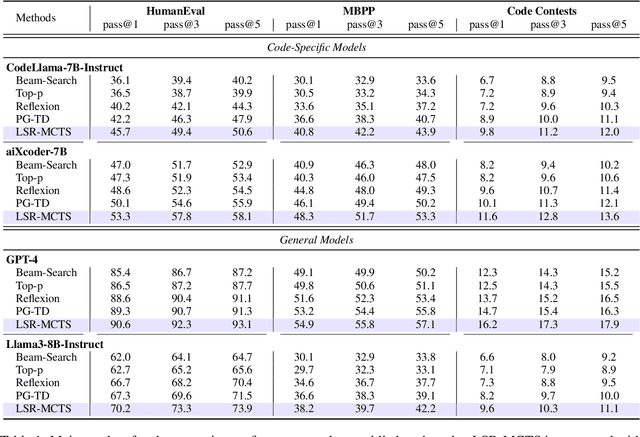
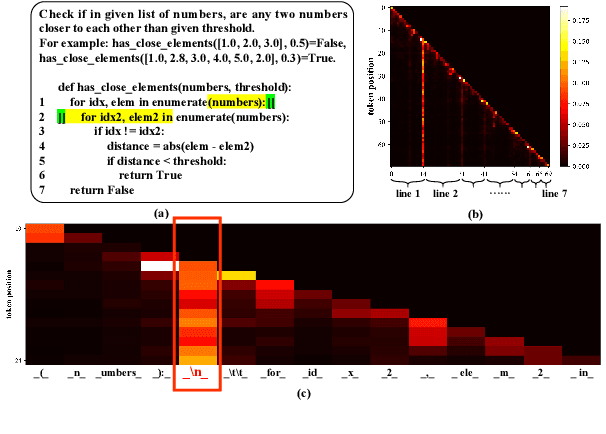
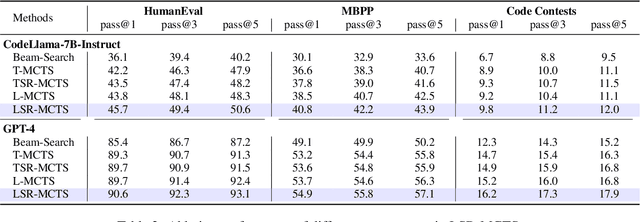
The emergence of large language models (LLMs) has significantly promoted the development of code generation task, sparking a surge in pertinent literature. Current research is hindered by redundant generation results and a tendency to overfit local patterns in the short term. Although existing studies attempt to alleviate the issue by adopting a multi-token prediction strategy, there remains limited focus on choosing the appropriate processing length for generations. By analyzing the attention between tokens during the generation process of LLMs, it can be observed that the high spikes of the attention scores typically appear at the end of lines. This insight suggests that it is reasonable to treat each line of code as a fundamental processing unit and generate them sequentially. Inspired by this, we propose the \textbf{LSR-MCTS} algorithm, which leverages MCTS to determine the code line-by-line and select the optimal path. Further, we integrate a self-refine mechanism at each node to enhance diversity and generate higher-quality programs through error correction. Extensive experiments and comprehensive analyses on three public coding benchmarks demonstrate that our method outperforms the state-of-the-art performance approaches.
ProGDF: Progressive Gaussian Differential Field for Controllable and Flexible 3D Editing
Dec 11, 2024



3D editing plays a crucial role in editing and reusing existing 3D assets, thereby enhancing productivity. Recently, 3DGS-based methods have gained increasing attention due to their efficient rendering and flexibility. However, achieving desired 3D editing results often requires multiple adjustments in an iterative loop, resulting in tens of minutes of training time cost for each attempt and a cumbersome trial-and-error cycle for users. This in-the-loop training paradigm results in a poor user experience. To address this issue, we introduce the concept of process-oriented modelling for 3D editing and propose the Progressive Gaussian Differential Field (ProGDF), an out-of-loop training approach that requires only a single training session to provide users with controllable editing capability and variable editing results through a user-friendly interface in real-time. ProGDF consists of two key components: Progressive Gaussian Splatting (PGS) and Gaussian Differential Field (GDF). PGS introduces the progressive constraint to extract the diverse intermediate results of the editing process and employs rendering quality regularization to improve the quality of these results. Based on these intermediate results, GDF leverages a lightweight neural network to model the editing process. Extensive results on two novel applications, namely controllable 3D editing and flexible fine-grained 3D manipulation, demonstrate the effectiveness, practicality and flexibility of the proposed ProGDF.
Towards Spoken Language Understanding via Multi-level Multi-grained Contrastive Learning
May 31, 2024



Spoken language understanding (SLU) is a core task in task-oriented dialogue systems, which aims at understanding the user's current goal through constructing semantic frames. SLU usually consists of two subtasks, including intent detection and slot filling. Although there are some SLU frameworks joint modeling the two subtasks and achieving high performance, most of them still overlook the inherent relationships between intents and slots and fail to achieve mutual guidance between the two subtasks. To solve the problem, we propose a multi-level multi-grained SLU framework MMCL to apply contrastive learning at three levels, including utterance level, slot level, and word level to enable intent and slot to mutually guide each other. For the utterance level, our framework implements coarse granularity contrastive learning and fine granularity contrastive learning simultaneously. Besides, we also apply the self-distillation method to improve the robustness of the model. Experimental results and further analysis demonstrate that our proposed model achieves new state-of-the-art results on two public multi-intent SLU datasets, obtaining a 2.6 overall accuracy improvement on the MixATIS dataset compared to previous best models.