 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMErroR: A Benchmark for Erroneous Reasoning in Vision-Language Models
Jan 06, 2026Recent advances in Vision-Language Models (VLMs) have improved performance in multi-modal learning, raising the question of whether these models truly understand the content they process. Crucially, can VLMs detect when a reasoning process is wrong and identify its error type? To answer this, we present MMErroR, a multi-modal benchmark of 2,013 samples, each embedding a single coherent reasoning error. These samples span 24 subdomains across six top-level domains, ensuring broad coverage and taxonomic richness. Unlike existing benchmarks that focus on answer correctness, MMErroR targets a process-level, error-centric evaluation that requires models to detect incorrect reasoning and classify the error type within both visual and linguistic contexts. We evaluate 20 advanced VLMs, even the best model (Gemini-3.0-Pro) classifies the error in only 66.47\% of cases, underscoring the challenge of identifying erroneous reasoning. Furthermore, the ability to accurately identify errors offers valuable insights into the capabilities of multi-modal reasoning models. Project Page: https://mmerror-benchmark.github.io
UPETrack: Unidirectional Position Estimation for Tracking Occluded Deformable Linear Objects
Dec 10, 2025Real-time state tracking of Deformable Linear Objects (DLOs) is critical for enabling robotic manipulation of DLOs in industrial assembly, medical procedures, and daily-life applications. However, the high-dimensional configuration space, nonlinear dynamics, and frequent partial occlusions present fundamental barriers to robust real-time DLO tracking. To address these limitations, this study introduces UPETrack, a geometry-driven framework based on Unidirectional Position Estimation (UPE), which facilitates tracking without the requirement for physical modeling, virtual simulation, or visual markers. The framework operates in two phases: (1) visible segment tracking is based on a Gaussian Mixture Model (GMM) fitted via the Expectation Maximization (EM) algorithm, and (2) occlusion region prediction employing UPE algorithm we proposed. UPE leverages the geometric continuity inherent in DLO shapes and their temporal evolution patterns to derive a closed-form positional estimator through three principal mechanisms: (i) local linear combination displacement term, (ii) proximal linear constraint term, and (iii) historical curvature term. This analytical formulation allows efficient and stable estimation of occluded nodes through explicit linear combinations of geometric components, eliminating the need for additional iterative optimization. Experimental results demonstrate that UPETrack surpasses two state-of-the-art tracking algorithms, including TrackDLO and CDCPD2, in both positioning accuracy and computational efficiency.
Partitioner Guided Modal Learning Framework
Jul 15, 2025Multimodal learning benefits from multiple modal information, and each learned modal representations can be divided into uni-modal that can be learned from uni-modal training and paired-modal features that can be learned from cross-modal interaction. Building on this perspective, we propose a partitioner-guided modal learning framework, PgM, which consists of the modal partitioner, uni-modal learner, paired-modal learner, and uni-paired modal decoder. Modal partitioner segments the learned modal representation into uni-modal and paired-modal features. Modal learner incorporates two dedicated components for uni-modal and paired-modal learning. Uni-paired modal decoder reconstructs modal representation based on uni-modal and paired-modal features. PgM offers three key benefits: 1) thorough learning of uni-modal and paired-modal features, 2) flexible distribution adjustment for uni-modal and paired-modal representations to suit diverse downstream tasks, and 3) different learning rates across modalities and partitions. Extensive experiments demonstrate the effectiveness of PgM across four multimodal tasks and further highlight its transferability to existing models. Additionally, we visualize the distribution of uni-modal and paired-modal features across modalities and tasks, offering insights into their respective contributions.
Turb-L1: Achieving Long-term Turbulence Tracing By Tackling Spectral Bias
May 25, 2025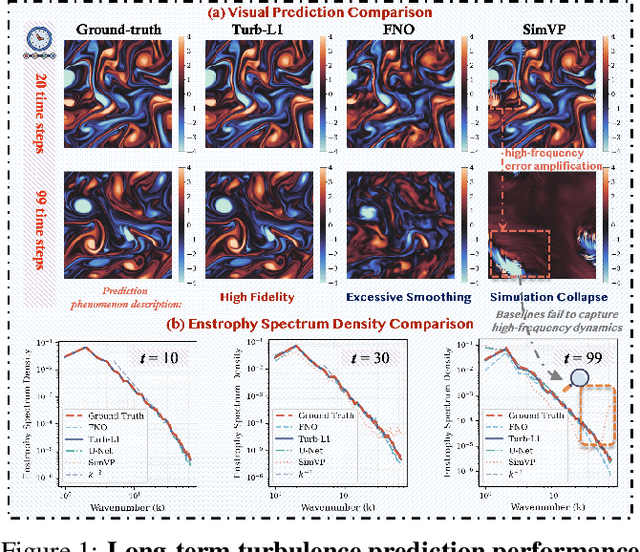
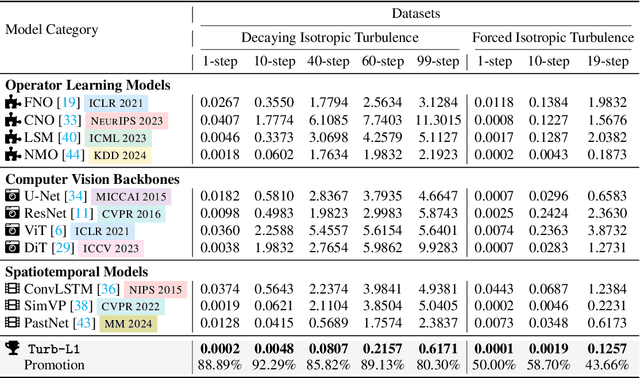
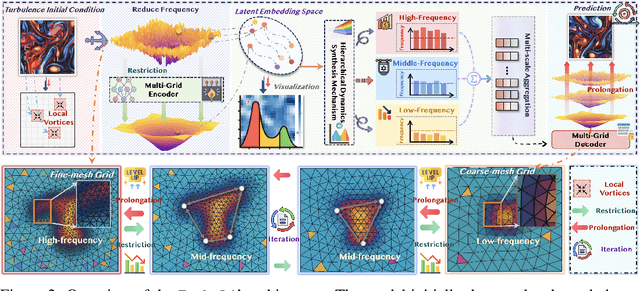
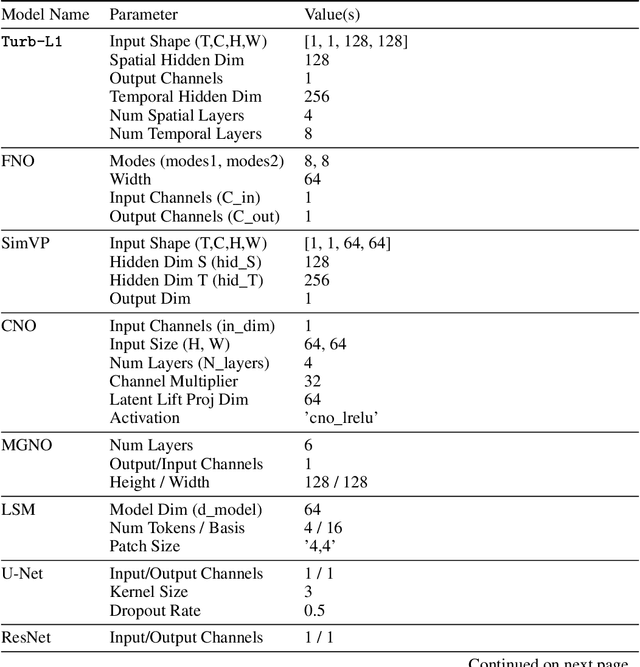
Accurately predicting the long-term evolution of turbulence is crucial for advancing scientific understanding and optimizing engineering applications. However, existing deep learning methods face significant bottlenecks in long-term autoregressive prediction, which exhibit excessive smoothing and fail to accurately track complex fluid dynamics. Our extensive experimental and spectral analysis of prevailing methods provides an interpretable explanation for this shortcoming, identifying Spectral Bias as the core obstacle. Concretely, spectral bias is the inherent tendency of models to favor low-frequency, smooth features while overlooking critical high-frequency details during training, thus reducing fidelity and causing physical distortions in long-term predictions. Building on this insight, we propose Turb-L1, an innovative turbulence prediction method, which utilizes a Hierarchical Dynamics Synthesis mechanism within a multi-grid architecture to explicitly overcome spectral bias. It accurately captures cross-scale interactions and preserves the fidelity of high-frequency dynamics, enabling reliable long-term tracking of turbulence evolution. Extensive experiments on the 2D turbulence benchmark show that Turb-L1 demonstrates excellent performance: (I) In long-term predictions, it reduces Mean Squared Error (MSE) by $80.3\%$ and increases Structural Similarity (SSIM) by over $9\times$ compared to the SOTA baseline, significantly improving prediction fidelity. (II) It effectively overcomes spectral bias, accurately reproducing the full enstrophy spectrum and maintaining physical realism in high-wavenumber regions, thus avoiding the spectral distortions or spurious energy accumulation seen in other methods.
CellVerse: Do Large Language Models Really Understand Cell Biology?
May 09, 2025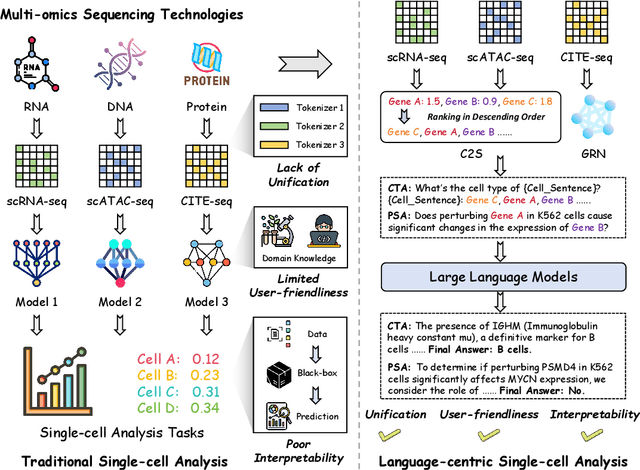
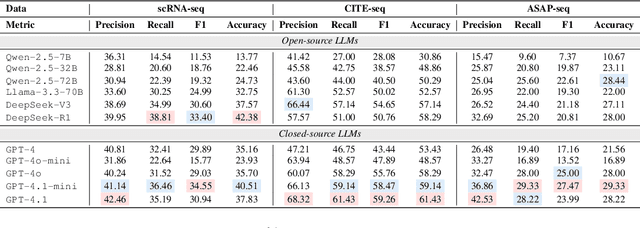
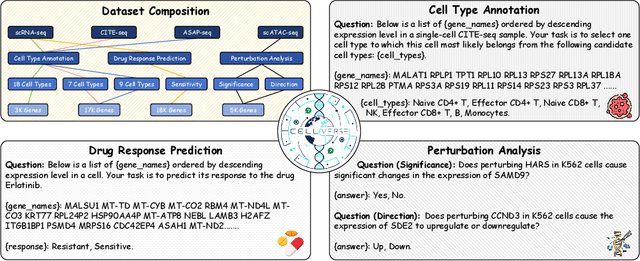
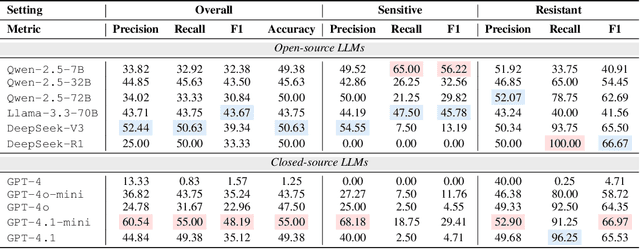
Recent studies have demonstrated the feasibility of modeling single-cell data as natural languages and the potential of leveraging powerful large language models (LLMs) for understanding cell biology. However, a comprehensive evaluation of LLMs' performance on language-driven single-cell analysis tasks still remains unexplored. Motivated by this challenge, we introduce CellVerse, a unified language-centric question-answering benchmark that integrates four types of single-cell multi-omics data and encompasses three hierarchical levels of single-cell analysis tasks: cell type annotation (cell-level), drug response prediction (drug-level), and perturbation analysis (gene-level). Going beyond this, we systematically evaluate the performance across 14 open-source and closed-source LLMs ranging from 160M to 671B on CellVerse. Remarkably, the experimental results reveal: (1) Existing specialist models (C2S-Pythia) fail to make reasonable decisions across all sub-tasks within CellVerse, while generalist models such as Qwen, Llama, GPT, and DeepSeek family models exhibit preliminary understanding capabilities within the realm of cell biology. (2) The performance of current LLMs falls short of expectations and has substantial room for improvement. Notably, in the widely studied drug response prediction task, none of the evaluated LLMs demonstrate significant performance improvement over random guessing. CellVerse offers the first large-scale empirical demonstration that significant challenges still remain in applying LLMs to cell biology. By introducing CellVerse, we lay the foundation for advancing cell biology through natural languages and hope this paradigm could facilitate next-generation single-cell analysis.
Enhancing Image Generation Fidelity via Progressive Prompts
Jan 13, 2025



The diffusion transformer (DiT) architecture has attracted significant attention in image generation, achieving better fidelity, performance, and diversity. However, most existing DiT - based image generation methods focus on global - aware synthesis, and regional prompt control has been less explored. In this paper, we propose a coarse - to - fine generation pipeline for regional prompt - following generation. Specifically, we first utilize the powerful large language model (LLM) to generate both high - level descriptions of the image (such as content, topic, and objects) and low - level descriptions (such as details and style). Then, we explore the influence of cross - attention layers at different depths. We find that deeper layers are always responsible for high - level content control, while shallow layers handle low - level content control. Various prompts are injected into the proposed regional cross - attention control for coarse - to - fine generation. By using the proposed pipeline, we enhance the controllability of DiT - based image generation. Extensive quantitative and qualitative results show that our pipeline can improve the performance of the generated images.
VASparse: Towards Efficient Visual Hallucination Mitigation for Large Vision-Language Model via Visual-Aware Sparsification
Jan 11, 2025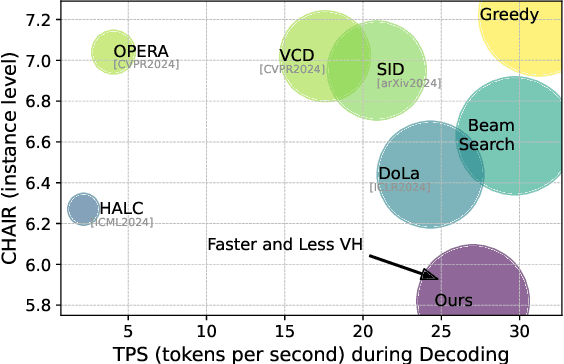



Large Vision-Language Models (LVLMs) may produce outputs that are unfaithful to reality, also known as visual hallucinations (VH), which significantly impedes their real-world usage. To alleviate VH, various decoding strategies have been proposed to enhance visual information. However, many of these methods may require secondary decoding and rollback, which significantly reduces inference speed. In this work, we propose an efficient plug-and-play decoding algorithm via Visual-Aware Sparsification (VASparse) from the perspective of token sparsity for mitigating VH. VASparse is inspired by empirical observations: (1) the sparse activation of attention in LVLMs, and (2) visual-agnostic tokens sparsification exacerbates VH. Based on these insights, we propose a novel token sparsification strategy that balances efficiency and trustworthiness. Specifically, VASparse implements a visual-aware token selection strategy during decoding to reduce redundant tokens while preserving visual context effectively. Additionally, we innovatively introduce a sparse-based visual contrastive decoding method to recalibrate the distribution of hallucinated outputs without the time overhead associated with secondary decoding. Subsequently, VASparse recalibrates attention scores to penalize attention sinking of LVLMs towards text tokens. Extensive experiments across four popular benchmarks confirm the effectiveness of VASparse in mitigating VH across different LVLM families without requiring additional training or post-processing. Impressively, VASparse achieves state-of-the-art performance for mitigating VH while maintaining competitive decoding speed. Code is available at https://github.com/mengchuang123/VASparse-github.
DisPose: Disentangling Pose Guidance for Controllable Human Image Animation
Dec 13, 2024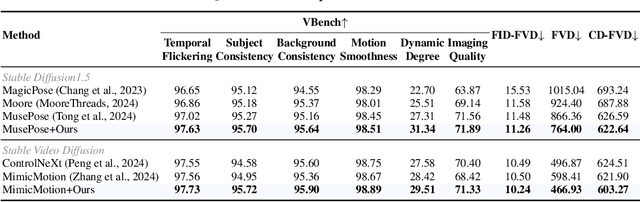
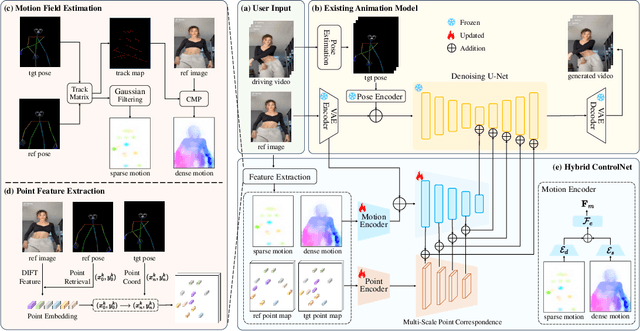
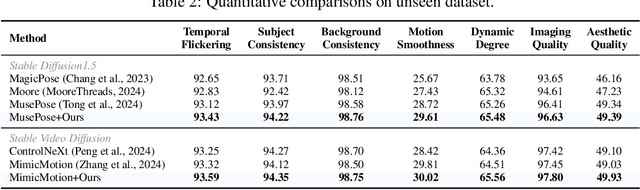

Controllable human image animation aims to generate videos from reference images using driving videos. Due to the limited control signals provided by sparse guidance (e.g., skeleton pose), recent works have attempted to introduce additional dense conditions (e.g., depth map) to ensure motion alignment. However, such strict dense guidance impairs the quality of the generated video when the body shape of the reference character differs significantly from that of the driving video. In this paper, we present DisPose to mine more generalizable and effective control signals without additional dense input, which disentangles the sparse skeleton pose in human image animation into motion field guidance and keypoint correspondence. Specifically, we generate a dense motion field from a sparse motion field and the reference image, which provides region-level dense guidance while maintaining the generalization of the sparse pose control. We also extract diffusion features corresponding to pose keypoints from the reference image, and then these point features are transferred to the target pose to provide distinct identity information. To seamlessly integrate into existing models, we propose a plug-and-play hybrid ControlNet that improves the quality and consistency of generated videos while freezing the existing model parameters. Extensive qualitative and quantitative experiments demonstrate the superiority of DisPose compared to current methods. Code: \href{https://github.com/lihxxx/DisPose}{https://github.com/lihxxx/DisPose}.
DiffATR: Diffusion-based Generative Modeling for Audio-Text Retrieval
Sep 16, 2024



Existing audio-text retrieval (ATR) methods are essentially discriminative models that aim to maximize the conditional likelihood, represented as p(candidates|query). Nevertheless, this methodology fails to consider the intrinsic data distribution p(query), leading to difficulties in discerning out-of-distribution data. In this work, we attempt to tackle this constraint through a generative perspective and model the relationship between audio and text as their joint probability p(candidates,query). To this end, we present a diffusion-based ATR framework (DiffATR), which models ATR as an iterative procedure that progressively generates joint distribution from noise. Throughout its training phase, DiffATR is optimized from both generative and discriminative viewpoints: the generator is refined through a generation loss, while the feature extractor benefits from a contrastive loss, thus combining the merits of both methodologies. Experiments on the AudioCaps and Clotho datasets with superior performances, verify the effectiveness of our approach. Notably, without any alterations, our DiffATR consistently exhibits strong performance in out-of-domain retrieval settings.
Audio-text Retrieval with Transformer-based Hierarchical Alignment and Disentangled Cross-modal Representation
Sep 14, 2024


Most existing audio-text retrieval (ATR) approaches typically rely on a single-level interaction to associate audio and text, limiting their ability to align different modalities and leading to suboptimal matches. In this work, we present a novel ATR framework that leverages two-stream Transformers in conjunction with a Hierarchical Alignment (THA) module to identify multi-level correspondences of different Transformer blocks between audio and text. Moreover, current ATR methods mainly focus on learning a global-level representation, missing out on intricate details to capture audio occurrences that correspond to textual semantics. To bridge this gap, we introduce a Disentangled Cross-modal Representation (DCR) approach that disentangles high-dimensional features into compact latent factors to grasp fine-grained audio-text semantic correlations. Additionally, we develop a confidence-aware (CA) module to estimate the confidence of each latent factor pair and adaptively aggregate cross-modal latent factors to achieve local semantic alignment. Experiments show that our THA effectively boosts ATR performance, with the DCR approach further contributing to consistent performance gains.