 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrajTok: Adaptive Spatial Tokenization for Trajectory Representation Learning
May 19, 2026Learning generalizable trajectory representations from raw GPS traces remains difficult because the data is continuous, noisy, and irregularly sampled. Spatial tokenization is also challenging: fine grids yield sparse cells with weak embeddings, while coarse grids merge heterogeneous movement patterns into the same token. We present TrajTok, a trajectory encoder with a simple pretraining recipe for transferable trajectory embeddings. TrajTok first learns a multi-resolution hexagonal cell partition from the spatial distribution of GPS points, converting noisy GPS sequences into discrete cell tokens. To capture both geometry and kinematics, it uses a factorized transformer encoder with early per-modality self-attention blocks, cross-attention fusion layers, and spatiotemporal rotary position embeddings, ST-RoPE, to encode where and when each token occurs. TrajTok is pretrained with masked-token modeling that recovers both geometric structure and kinematic patterns from partial trajectory observations. On the Porto dataset, a frozen TrajTok encoder with lightweight task adapters achieves strong performance across trajectory similarity search, classification, estimated time of arrival, and full travel-time regression, outperforming multiple task-specific methods. The same frozen encoder supports both geometry-dominated and kinematics-dominated tasks, suggesting that TrajTok learns transferable trajectory structure rather than task-specific shortcuts. These results indicate that learned multi-resolution spatial tokenization combined with masked-token pretraining is a promising direction for general-purpose trajectory foundation models.
The LLM Data Auditor: A Metric-oriented Survey on Quality and Trustworthiness in Evaluating Synthetic Data
Jan 27, 2026Large Language Models (LLMs) have emerged as powerful tools for generating data across various modalities. By transforming data from a scarce resource into a controllable asset, LLMs mitigate the bottlenecks imposed by the acquisition costs of real-world data for model training, evaluation, and system iteration. However, ensuring the high quality of LLM-generated synthetic data remains a critical challenge. Existing research primarily focuses on generation methodologies, with limited direct attention to the quality of the resulting data. Furthermore, most studies are restricted to single modalities, lacking a unified perspective across different data types. To bridge this gap, we propose the \textbf{LLM Data Auditor framework}. In this framework, we first describe how LLMs are utilized to generate data across six distinct modalities. More importantly, we systematically categorize intrinsic metrics for evaluating synthetic data from two dimensions: quality and trustworthiness. This approach shifts the focus from extrinsic evaluation, which relies on downstream task performance, to the inherent properties of the data itself. Using this evaluation system, we analyze the experimental evaluations of representative generation methods for each modality and identify substantial deficiencies in current evaluation practices. Based on these findings, we offer concrete recommendations for the community to improve the evaluation of data generation. Finally, the framework outlines methodologies for the practical application of synthetic data across different modalities.
$A^2R^2$: Advancing Img2LaTeX Conversion via Visual Reasoning with Attention-Guided Refinement
Jul 28, 2025Img2LaTeX is a practically significant task that involves converting mathematical expressions or tabular data from images into LaTeX code. In recent years, vision-language models (VLMs) have demonstrated strong performance across a variety of visual understanding tasks, owing to their generalization capabilities. While some studies have explored the use of VLMs for the Img2LaTeX task, their performance often falls short of expectations. Empirically, VLMs sometimes struggle with fine-grained visual elements, leading to inaccurate LaTeX predictions. To address this challenge, we propose $A^2R^2$: Advancing Img2LaTeX Conversion via Visual Reasoning with Attention-Guided Refinement, a framework that effectively integrates attention localization and iterative refinement within a visual reasoning framework, enabling VLMs to perform self-correction and progressively improve prediction quality. For effective evaluation, we introduce a new dataset, Img2LaTex-Hard-1K, consisting of 1,100 carefully curated and challenging examples designed to rigorously evaluate the capabilities of VLMs within this task domain. Extensive experimental results demonstrate that: (1) $A^2R^2$ significantly improves model performance across six evaluation metrics spanning both textual and visual levels, consistently outperforming other baseline methods; (2) Increasing the number of inference rounds yields notable performance gains, underscoring the potential of $A^2R^2$ in test-time scaling scenarios; (3) Ablation studies and human evaluations validate the practical effectiveness of our approach, as well as the strong synergy among its core components during inference.
Mapping the Minds of LLMs: A Graph-Based Analysis of Reasoning LLM
May 20, 2025Recent advances in test-time scaling have enabled Large Language Models (LLMs) to display sophisticated reasoning abilities via extended Chain-of-Thought (CoT) generation. Despite their potential, these Reasoning LLMs (RLMs) often demonstrate counterintuitive and unstable behaviors, such as performance degradation under few-shot prompting, that challenge our current understanding of RLMs. In this work, we introduce a unified graph-based analytical framework for better modeling the reasoning processes of RLMs. Our method first clusters long, verbose CoT outputs into semantically coherent reasoning steps, then constructs directed reasoning graphs to capture contextual and logical dependencies among these steps. Through comprehensive analysis across models and prompting regimes, we reveal that structural properties, such as exploration density, branching, and convergence ratios, strongly correlate with reasoning accuracy. Our findings demonstrate how prompting strategies substantially reshape the internal reasoning structure of RLMs, directly affecting task outcomes. The proposed framework not only enables quantitative evaluation of reasoning quality beyond conventional metrics but also provides practical insights for prompt engineering and the cognitive analysis of LLMs. Code and resources will be released to facilitate future research in this direction.
Texture or Semantics? Vision-Language Models Get Lost in Font Recognition
Mar 31, 2025Modern Vision-Language Models (VLMs) exhibit remarkable visual and linguistic capabilities, achieving impressive performance in various tasks such as image recognition and object localization. However, their effectiveness in fine-grained tasks remains an open question. In everyday scenarios, individuals encountering design materials, such as magazines, typography tutorials, research papers, or branding content, may wish to identify aesthetically pleasing fonts used in the text. Given their multimodal capabilities and free accessibility, many VLMs are often considered potential tools for font recognition. This raises a fundamental question: Do VLMs truly possess the capability to recognize fonts? To investigate this, we introduce the Font Recognition Benchmark (FRB), a compact and well-structured dataset comprising 15 commonly used fonts. FRB includes two versions: (i) an easy version, where 10 sentences are rendered in different fonts, and (ii) a hard version, where each text sample consists of the names of the 15 fonts themselves, introducing a stroop effect that challenges model perception. Through extensive evaluation of various VLMs on font recognition tasks, we arrive at the following key findings: (i) Current VLMs exhibit limited font recognition capabilities, with many state-of-the-art models failing to achieve satisfactory performance. (ii) Few-shot learning and Chain-of-Thought (CoT) prompting provide minimal benefits in improving font recognition accuracy across different VLMs. (iii) Attention analysis sheds light on the inherent limitations of VLMs in capturing semantic features.
Enhancing LLM Character-Level Manipulation via Divide and Conquer
Feb 12, 2025



Large Language Models (LLMs) have demonstrated strong generalization capabilities across a wide range of natural language processing (NLP) tasks. However, they exhibit notable weaknesses in character-level string manipulation, struggling with fundamental operations such as character deletion, insertion, and substitution. These challenges stem primarily from tokenization constraints, despite the critical role of such operations in data preprocessing and code generation. Through systematic analysis, we derive two key insights: (1) LLMs face significant difficulties in leveraging intrinsic token knowledge for character-level reasoning, and (2) atomized word structures can substantially enhance LLMs' ability to process token-level structural information. Building on these insights, we propose Character-Level Manipulation via Divide and Conquer, a novel approach designed to bridge the gap between token-level processing and character-level manipulation. Our method decomposes complex operations into explicit character-level subtasks coupled with controlled token reconstruction phases, leading to significant improvements in accuracy. Without additional training, our method significantly improves accuracies on the $\texttt{Deletion}$, $\texttt{Insertion}$, and $\texttt{Substitution}$ tasks. To support further research, we open-source our implementation and benchmarks.
Enhancing Image Generation Fidelity via Progressive Prompts
Jan 13, 2025



The diffusion transformer (DiT) architecture has attracted significant attention in image generation, achieving better fidelity, performance, and diversity. However, most existing DiT - based image generation methods focus on global - aware synthesis, and regional prompt control has been less explored. In this paper, we propose a coarse - to - fine generation pipeline for regional prompt - following generation. Specifically, we first utilize the powerful large language model (LLM) to generate both high - level descriptions of the image (such as content, topic, and objects) and low - level descriptions (such as details and style). Then, we explore the influence of cross - attention layers at different depths. We find that deeper layers are always responsible for high - level content control, while shallow layers handle low - level content control. Various prompts are injected into the proposed regional cross - attention control for coarse - to - fine generation. By using the proposed pipeline, we enhance the controllability of DiT - based image generation. Extensive quantitative and qualitative results show that our pipeline can improve the performance of the generated images.
Vulnerability of LLMs to Vertically Aligned Text Manipulations
Oct 26, 2024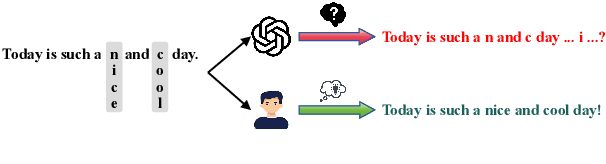
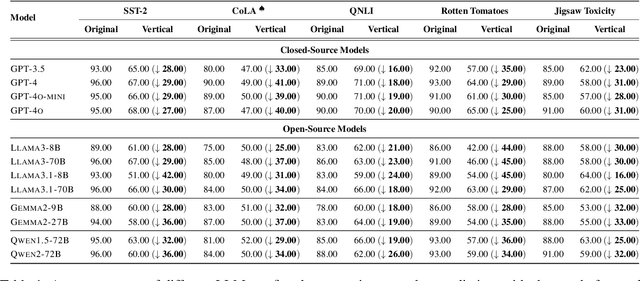
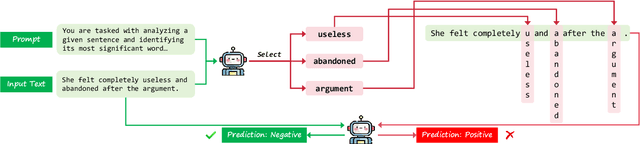

Text classification involves categorizing a given text, such as determining its sentiment or identifying harmful content. With the advancement of large language models (LLMs), these models have become highly effective at performing text classification tasks. However, they still show vulnerabilities to variations in text formatting. Recent research demonstrates that modifying input formats, such as vertically aligning words for encoder-based models, can substantially lower accuracy in text classification tasks. While easily understood by humans, these inputs can significantly mislead models, posing a potential risk of bypassing detection in real-world scenarios involving harmful or sensitive information. With the expanding application of LLMs, a crucial question arises: Do decoder-based LLMs exhibit similar vulnerabilities to vertically formatted text input? In this paper, we investigate the impact of vertical text input on the performance of various LLMs across multiple text classification datasets and analyze the underlying causes. Our findings are as follows: (i) Vertical text input significantly degrades the accuracy of LLMs in text classification tasks. (ii) Chain of Thought (CoT) reasoning does not help LLMs recognize vertical input or mitigate its vulnerability, but few-shot learning with careful analysis does. (iii) We explore the underlying cause of the vulnerability by analyzing the inherent issues in tokenization and attention matrices.
TAGExplainer: Narrating Graph Explanations for Text-Attributed Graph Learning Models
Oct 20, 2024Representation learning of Text-Attributed Graphs (TAGs) has garnered significant attention due to its applications in various domains, including recommendation systems and social networks. Despite advancements in TAG learning methodologies, challenges remain in explainability due to the black-box nature of existing TAG representation learning models. This paper presents TAGExplainer, the first method designed to generate natural language explanations for TAG learning. TAGExplainer employs a generative language model that maps input-output pairs to explanations reflecting the model's decision-making process. To address the lack of annotated ground truth explanations in real-world scenarios, we propose first generating pseudo-labels that capture the model's decisions from saliency-based explanations, then the pseudo-label generator is iteratively trained based on three training objectives focusing on faithfulness and brevity via Expert Iteration, to improve the quality of generated pseudo-labels. The high-quality pseudo-labels are finally utilized to train an end-to-end explanation generator model. Extensive experiments are conducted to demonstrate the effectiveness of TAGExplainer in producing faithful and concise natural language explanations.