 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVulnerability of LLMs to Vertically Aligned Text Manipulations
Paper and Code
Oct 26, 2024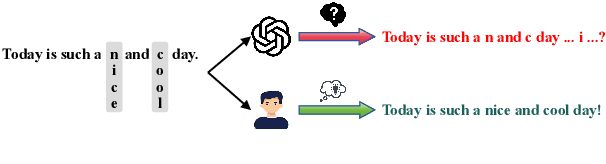
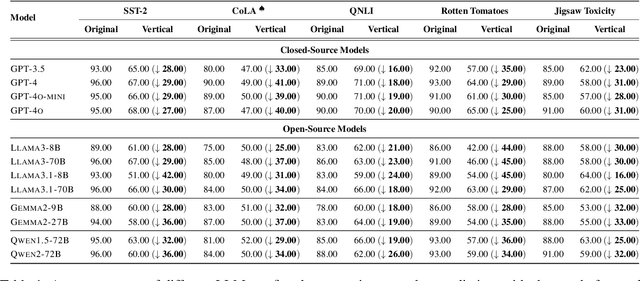
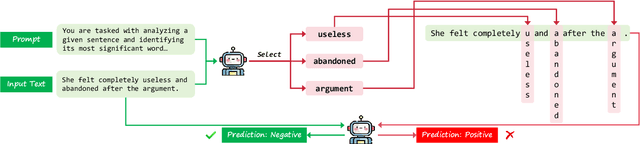

Text classification involves categorizing a given text, such as determining its sentiment or identifying harmful content. With the advancement of large language models (LLMs), these models have become highly effective at performing text classification tasks. However, they still show vulnerabilities to variations in text formatting. Recent research demonstrates that modifying input formats, such as vertically aligning words for encoder-based models, can substantially lower accuracy in text classification tasks. While easily understood by humans, these inputs can significantly mislead models, posing a potential risk of bypassing detection in real-world scenarios involving harmful or sensitive information. With the expanding application of LLMs, a crucial question arises: Do decoder-based LLMs exhibit similar vulnerabilities to vertically formatted text input? In this paper, we investigate the impact of vertical text input on the performance of various LLMs across multiple text classification datasets and analyze the underlying causes. Our findings are as follows: (i) Vertical text input significantly degrades the accuracy of LLMs in text classification tasks. (ii) Chain of Thought (CoT) reasoning does not help LLMs recognize vertical input or mitigate its vulnerability, but few-shot learning with careful analysis does. (iii) We explore the underlying cause of the vulnerability by analyzing the inherent issues in tokenization and attention matrices.