 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterDeepResearch: Enabling Human-Agent Collaborative Information Seeking through Interactive Deep Research
Mar 13, 2026Deep research systems powered by LLM agents have transformed complex information seeking by automating the iterative retrieval, filtering, and synthesis of insights from massive-scale web sources. However, existing systems predominantly follow an autonomous "query-to-report" paradigm, limiting users to a passive role and failing to integrate their personal insights, contextual knowledge, and evolving research intents. This paper addresses the lack of human-in-the-loop collaboration in the agentic research process. Through a formative study, we identify that current systems hinder effective human-agent collaboration in terms of process observability, real-time steerability, and context navigation efficiency. Informed by these findings, we propose InterDeepResearch, an interactive deep research system backed by a dedicated research context management framework. The framework organizes research context into a hierarchical architecture with three levels (information, actions, and sessions), enabling dynamic context reduction to prevent LLM context exhaustion and cross-action backtracing for evidence provenance. Built upon this framework, the system interface integrates three coordinated views for visual sensemaking, and dedicated interaction mechanisms for interactive research context navigation. Evaluation on the Xbench-DeepSearch-v1 and Seal-0 benchmarks shows that InterDeepResearch achieves competitive performance compared to state-of-the-art deep research systems, while a formal user study demonstrates its effectiveness in supporting human-agent collaborative information seeking. Project page with system demo: https://github.com/bopan3/InterDeepResearch.
Retrieval-Augmented Foundation Models for Matched Molecular Pair Transformations to Recapitulate Medicinal Chemistry Intuition
Feb 18, 2026Matched molecular pairs (MMPs) capture the local chemical edits that medicinal chemists routinely use to design analogs, but existing ML approaches either operate at the whole-molecule level with limited edit controllability or learn MMP-style edits from restricted settings and small models. We propose a variable-to-variable formulation of analog generation and train a foundation model on large-scale MMP transformations (MMPTs) to generate diverse variables conditioned on an input variable. To enable practical control, we develop prompting mechanisms that let the users specify preferred transformation patterns during generation. We further introduce MMPT-RAG, a retrieval-augmented framework that uses external reference analogs as contextual guidance to steer generation and generalize from project-specific series. Experiments on general chemical corpora and patent-specific datasets demonstrate improved diversity, novelty, and controllability, and show that our method recovers realistic analog structures in practical discovery scenarios.
Bi-Level Prompt Optimization for Multimodal LLM-as-a-Judge
Feb 11, 2026Large language models (LLMs) have become widely adopted as automated judges for evaluating AI-generated content. Despite their success, aligning LLM-based evaluations with human judgments remains challenging. While supervised fine-tuning on human-labeled data can improve alignment, it is costly and inflexible, requiring new training for each task or dataset. Recent progress in auto prompt optimization (APO) offers a more efficient alternative by automatically improving the instructions that guide LLM judges. However, existing APO methods primarily target text-only evaluations and remain underexplored in multimodal settings. In this work, we study auto prompt optimization for multimodal LLM-as-a-judge, particularly for evaluating AI-generated images. We identify a key bottleneck: multimodal models can only process a limited number of visual examples due to context window constraints, which hinders effective trial-and-error prompt refinement. To overcome this, we propose BLPO, a bi-level prompt optimization framework that converts images into textual representations while preserving evaluation-relevant visual cues. Our bi-level optimization approach jointly refines the judge prompt and the I2T prompt to maintain fidelity under limited context budgets. Experiments on four datasets and three LLM judges demonstrate the effectiveness of our method.
Transformer-Based Approach for Automated Functional Group Replacement in Chemical Compounds
Jan 12, 2026Functional group replacement is a pivotal approach in cheminformatics to enable the design of novel chemical compounds with tailored properties. Traditional methods for functional group removal and replacement often rely on rule-based heuristics, which can be limited in their ability to generate diverse and novel chemical structures. Recently, transformer-based models have shown promise in improving the accuracy and efficiency of molecular transformations, but existing approaches typically focus on single-step modeling, lacking the guarantee of structural similarity. In this work, we seek to advance the state of the art by developing a novel two-stage transformer model for functional group removal and replacement. Unlike one-shot approaches that generate entire molecules in a single pass, our method generates the functional group to be removed and appended sequentially, ensuring strict substructure-level modifications. Using a matched molecular pairs (MMPs) dataset derived from ChEMBL, we trained an encoder-decoder transformer model with SMIRKS-based representations to capture transformation rules effectively. Extensive evaluations demonstrate our method's ability to generate chemically valid transformations, explore diverse chemical spaces, and maintain scalability across varying search sizes.
IGenBench: Benchmarking the Reliability of Text-to-Infographic Generation
Jan 08, 2026Infographics are composite visual artifacts that combine data visualizations with textual and illustrative elements to communicate information. While recent text-to-image (T2I) models can generate aesthetically appealing images, their reliability in generating infographics remains unclear. Generated infographics may appear correct at first glance but contain easily overlooked issues, such as distorted data encoding or incorrect textual content. We present IGENBENCH, the first benchmark for evaluating the reliability of text-to-infographic generation, comprising 600 curated test cases spanning 30 infographic types. We design an automated evaluation framework that decomposes reliability verification into atomic yes/no questions based on a taxonomy of 10 question types. We employ multimodal large language models (MLLMs) to verify each question, yielding question-level accuracy (Q-ACC) and infographic-level accuracy (I-ACC). We comprehensively evaluate 10 state-of-the-art T2I models on IGENBENCH. Our systematic analysis reveals key insights for future model development: (i) a three-tier performance hierarchy with the top model achieving Q-ACC of 0.90 but I-ACC of only 0.49; (ii) data-related dimensions emerging as universal bottlenecks (e.g., Data Completeness: 0.21); and (iii) the challenge of achieving end-to-end correctness across all models. We release IGENBENCH at https://igen-bench.vercel.app/.
RelayGR: Scaling Long-Sequence Generative Recommendation via Cross-Stage Relay-Race Inference
Jan 05, 2026Real-time recommender systems execute multi-stage cascades (retrieval, pre-processing, fine-grained ranking) under strict tail-latency SLOs, leaving only tens of milliseconds for ranking. Generative recommendation (GR) models can improve quality by consuming long user-behavior sequences, but in production their online sequence length is tightly capped by the ranking-stage P99 budget. We observe that the majority of GR tokens encode user behaviors that are independent of the item candidates, suggesting an opportunity to pre-infer a user-behavior prefix once and reuse it during ranking rather than recomputing it on the critical path. Realizing this idea at industrial scale is non-trivial: the prefix cache must survive across multiple pipeline stages before the final ranking instance is determined, the user population implies cache footprints far beyond a single device, and indiscriminate pre-inference would overload shared resources under high QPS. We present RelayGR, a production system that enables in-HBM relay-race inference for GR. RelayGR selectively pre-infers long-term user prefixes, keeps their KV caches resident in HBM over the request lifecycle, and ensures the subsequent ranking can consume them without remote fetches. RelayGR combines three techniques: 1) a sequence-aware trigger that admits only at-risk requests under a bounded cache footprint and pre-inference load, 2) an affinity-aware router that co-locates cache production and consumption by routing both the auxiliary pre-infer signal and the ranking request to the same instance, and 3) a memory-aware expander that uses server-local DRAM to capture short-term cross-request reuse while avoiding redundant reloads. We implement RelayGR on Huawei Ascend NPUs and evaluate it with real queries. Under a fixed P99 SLO, RelayGR supports up to 1.5$\times$ longer sequences and improves SLO-compliant throughput by up to 3.6$\times$.
VIS-Shepherd: Constructing Critic for LLM-based Data Visualization Generation
Jun 16, 2025Data visualization generation using Large Language Models (LLMs) has shown promising results but often produces suboptimal visualizations that require human intervention for improvement. In this work, we introduce VIS-Shepherd, a specialized Multimodal Large Language Model (MLLM)-based critic to evaluate and provide feedback for LLM-generated data visualizations. At the core of our approach is a framework to construct a high-quality visualization critique dataset, where we collect human-created visualization instances, synthesize corresponding LLM-generated instances, and construct high-quality critiques. We conduct both model-based automatic evaluation and human preference studies to evaluate the effectiveness of our approach. Our experiments show that even small (7B parameters) open-source MLLM models achieve substantial performance gains by leveraging our high-quality visualization critique dataset, reaching levels comparable to much larger open-source or even proprietary models. Our work demonstrates significant potential for MLLM-based automated visualization critique and indicates promising directions for enhancing LLM-based data visualization generation. Our project page: https://github.com/bopan3/VIS-Shepherd.
Can Past Experience Accelerate LLM Reasoning?
May 27, 2025
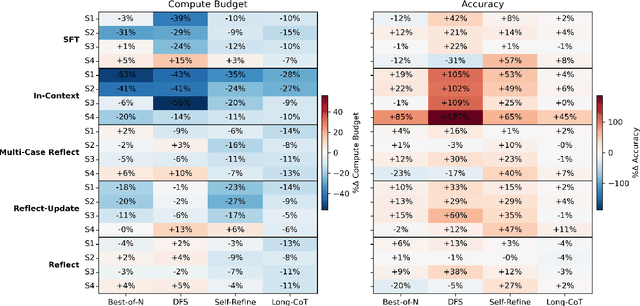


Allocating more compute to large language models (LLMs) reasoning has generally been demonstrated to improve their effectiveness, but also results in increased inference time. In contrast, humans can perform tasks faster and better with increased experience and exposure. Hence, this paper aims to investigate the question: Can LLMs also become faster at reasoning through recurrent exposure on relevant tasks, and if so, how can it be achieved? To address these questions, we first formalize the problem setting of LLM reasoning speedup systematically in the dimensions of task relevancy and compute budget calculation. We then propose SpeedupLLM, a theoretically guaranteed framework to implement and benchmark such reasoning speedup behaviour based on adaptive compute allocation and memory mechanisms. We further conduct comprehensive experiments to benchmark such behaviour across different question similarity levels, memory methods, and reasoning methods. Results show that LLMs can generally reason faster with past experience, achieving up to a 56% reduction in compute cost when equipped with appropriate memory and reasoning methods.
Exploring Multimodal Prompt for Visualization Authoring with Large Language Models
Apr 18, 2025



Recent advances in large language models (LLMs) have shown great potential in automating the process of visualization authoring through simple natural language utterances. However, instructing LLMs using natural language is limited in precision and expressiveness for conveying visualization intent, leading to misinterpretation and time-consuming iterations. To address these limitations, we conduct an empirical study to understand how LLMs interpret ambiguous or incomplete text prompts in the context of visualization authoring, and the conditions making LLMs misinterpret user intent. Informed by the findings, we introduce visual prompts as a complementary input modality to text prompts, which help clarify user intent and improve LLMs' interpretation abilities. To explore the potential of multimodal prompting in visualization authoring, we design VisPilot, which enables users to easily create visualizations using multimodal prompts, including text, sketches, and direct manipulations on existing visualizations. Through two case studies and a controlled user study, we demonstrate that VisPilot provides a more intuitive way to create visualizations without affecting the overall task efficiency compared to text-only prompting approaches. Furthermore, we analyze the impact of text and visual prompts in different visualization tasks. Our findings highlight the importance of multimodal prompting in improving the usability of LLMs for visualization authoring. We discuss design implications for future visualization systems and provide insights into how multimodal prompts can enhance human-AI collaboration in creative visualization tasks. All materials are available at https://OSF.IO/2QRAK.
MEGL: Multimodal Explanation-Guided Learning
Nov 20, 2024



Explaining the decision-making processes of Artificial Intelligence (AI) models is crucial for addressing their "black box" nature, particularly in tasks like image classification. Traditional eXplainable AI (XAI) methods typically rely on unimodal explanations, either visual or textual, each with inherent limitations. Visual explanations highlight key regions but often lack rationale, while textual explanations provide context without spatial grounding. Further, both explanation types can be inconsistent or incomplete, limiting their reliability. To address these challenges, we propose a novel Multimodal Explanation-Guided Learning (MEGL) framework that leverages both visual and textual explanations to enhance model interpretability and improve classification performance. Our Saliency-Driven Textual Grounding (SDTG) approach integrates spatial information from visual explanations into textual rationales, providing spatially grounded and contextually rich explanations. Additionally, we introduce Textual Supervision on Visual Explanations to align visual explanations with textual rationales, even in cases where ground truth visual annotations are missing. A Visual Explanation Distribution Consistency loss further reinforces visual coherence by aligning the generated visual explanations with dataset-level patterns, enabling the model to effectively learn from incomplete multimodal supervision. We validate MEGL on two new datasets, Object-ME and Action-ME, for image classification with multimodal explanations. Experimental results demonstrate that MEGL outperforms previous approaches in prediction accuracy and explanation quality across both visual and textual domains. Our code will be made available upon the acceptance of the paper.