 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInducing Reasoning Primitives from Agent Traces
Jun 02, 2026ReAct-style LLM agents often rediscover the same reasoning routines across problems, yet leave those routines trapped in transient scratchpads. We introduce Reasoning Primitive Induction, a single-pass method that mines successful ReAct traces, clusters recurrent reasoning moves, and converts the most frequent moves into a compact library of typed pseudo-tools. Each pseudo-tool is specified by a natural-language docstring interpreted by an LLM at invocation time, and a standard ReAct loop composes these primitives at test time. The central result is that induced libraries outperform the very agent that generated their traces: by +44pp on RuleArena NBA (30 -> 74), +30pp on MuSR team allocation (38 -> 68), and +22pp on NatPlan meeting planning (7 -> 29). Across five comparable subtasks spanning narrative deduction, rule application, and constraint-satisfaction planning, a single fixed configuration improves over zero-shot Chain-of-Thought on every subtask, matches or surpasses expert-authored decompositions, and outperforms AWM at lower average inference cost.
Learning to Construct Practical Agentic Systems
May 29, 2026Automated design and optimization of agentic LLM-based systems leads to sophisticated systems that substantially improve result quality over off-the-shelf agentic patterns. However, studies of fielded agentic systems show that production systems focus much more on issues such as simplicity, controllability, and predictability of inference costs. In this paper we propose principled approaches to designing and optimizing practical agentic systems. We describe an agent framework that enables designers to enforce modularity in agentic systems, by defining "pseudo-tools" that call LLMs recursively on a restricted context. Using this framework we hand-engineer agents for a diverse set of tasks, and show that relative to dynamically-planned workflows, hand-constructed fixed workflows are generally cheaper and more accurate. We then propose novel learning methods for the agentic components required by this framework, namely pseudo-tools and fixed workflows. These learning methods generally outperform hand-engineered agents. We also exploit the modularity of the framework to apply multi-objective optimization methods to jointly optimize cost and response quality and blend the results of multiple learning systems.
CG-RAG: Research Question Answering by Citation Graph Retrieval-Augmented LLMs
Jan 25, 2025



Research question answering requires accurate retrieval and contextual understanding of scientific literature. However, current Retrieval-Augmented Generation (RAG) methods often struggle to balance complex document relationships with precise information retrieval. In this paper, we introduce Contextualized Graph Retrieval-Augmented Generation (CG-RAG), a novel framework that integrates sparse and dense retrieval signals within graph structures to enhance retrieval efficiency and subsequently improve generation quality for research question answering. First, we propose a contextual graph representation for citation graphs, effectively capturing both explicit and implicit connections within and across documents. Next, we introduce Lexical-Semantic Graph Retrieval (LeSeGR), which seamlessly integrates sparse and dense retrieval signals with graph encoding. It bridges the gap between lexical precision and semantic understanding in citation graph retrieval, demonstrating generalizability to existing graph retrieval and hybrid retrieval methods. Finally, we present a context-aware generation strategy that utilizes the retrieved graph-structured information to generate precise and contextually enriched responses using large language models (LLMs). Extensive experiments on research question answering benchmarks across multiple domains demonstrate that our CG-RAG framework significantly outperforms RAG methods combined with various state-of-the-art retrieval approaches, delivering superior retrieval accuracy and generation quality.
GRAG: Graph Retrieval-Augmented Generation
May 26, 2024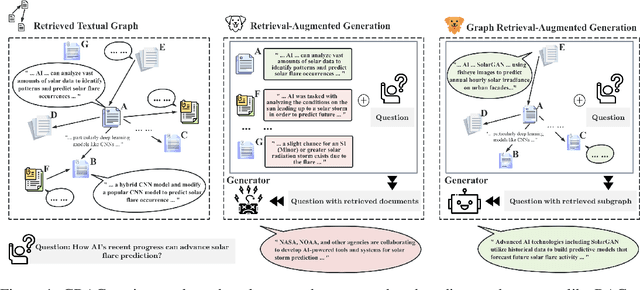

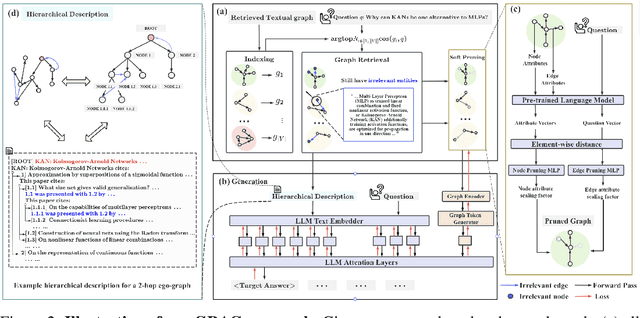
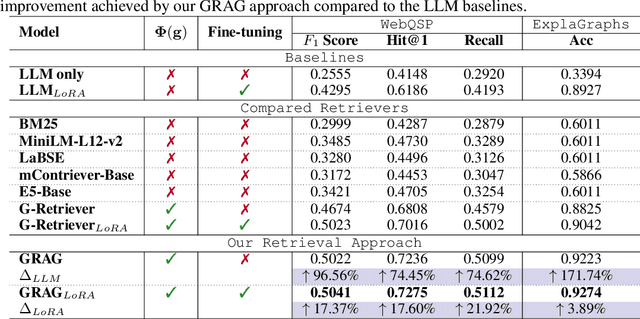
While Retrieval-Augmented Generation (RAG) enhances the accuracy and relevance of responses by generative language models, it falls short in graph-based contexts where both textual and topological information are important. Naive RAG approaches inherently neglect the structural intricacies of textual graphs, resulting in a critical gap in the generation process. To address this challenge, we introduce $\textbf{Graph Retrieval-Augmented Generation (GRAG)}$, which significantly enhances both the retrieval and generation processes by emphasizing the importance of subgraph structures. Unlike RAG approaches that focus solely on text-based entity retrieval, GRAG maintains an acute awareness of graph topology, which is crucial for generating contextually and factually coherent responses. Our GRAG approach consists of four main stages: indexing of $k$-hop ego-graphs, graph retrieval, soft pruning to mitigate the impact of irrelevant entities, and generation with pruned textual subgraphs. GRAG's core workflow-retrieving textual subgraphs followed by soft pruning-efficiently identifies relevant subgraph structures while avoiding the computational infeasibility typical of exhaustive subgraph searches, which are NP-hard. Moreover, we propose a novel prompting strategy that achieves lossless conversion from textual subgraphs to hierarchical text descriptions. Extensive experiments on graph multi-hop reasoning benchmarks demonstrate that in scenarios requiring multi-hop reasoning on textual graphs, our GRAG approach significantly outperforms current state-of-the-art RAG methods while effectively mitigating hallucinations.