 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolutionary Generation of Multi-Agent Systems
Feb 06, 2026Large language model (LLM)-based multi-agent systems (MAS) show strong promise for complex reasoning, planning, and tool-augmented tasks, but designing effective MAS architectures remains labor-intensive, brittle, and hard to generalize. Existing automatic MAS generation methods either rely on code generation, which often leads to executability and robustness failures, or impose rigid architectural templates that limit expressiveness and adaptability. We propose Evolutionary Generation of Multi-Agent Systems (EvoMAS), which formulates MAS generation as structured configuration generation. EvoMAS performs evolutionary generation in configuration space. Specifically, EvoMAS selects initial configurations from a pool, applies feedback-conditioned mutation and crossover guided by execution traces, and iteratively refines both the candidate pool and an experience memory. We evaluate EvoMAS on diverse benchmarks, including BBEH, SWE-Bench, and WorkBench, covering reasoning, software engineering, and tool-use tasks. EvoMAS consistently improves task performance over both human-designed MAS and prior automatic MAS generation methods, while producing generated systems with higher executability and runtime robustness. EvoMAS outperforms the agent evolution method EvoAgent by +10.5 points on BBEH reasoning and +7.1 points on WorkBench. With Claude-4.5-Sonnet, EvoMAS also reaches 79.1% on SWE-Bench-Verified, matching the top of the leaderboard.
RAG without Forgetting: Continual Query-Infused Key Memory
Feb 05, 2026Retrieval-augmented generation (RAG) systems commonly improve robustness via query-time adaptations such as query expansion and iterative retrieval. While effective, these approaches are inherently stateless: adaptations are recomputed for each query and discarded thereafter, precluding cumulative learning and repeatedly incurring inference-time cost. Index-side approaches like key expansion introduce persistence but rely on offline preprocessing or heuristic updates that are weakly aligned with downstream task utility, leading to semantic drift and noise accumulation. We propose Evolving Retrieval Memory (ERM), a training-free framework that transforms transient query-time gains into persistent retrieval improvements. ERM updates the retrieval index through correctness-gated feedback, selectively attributes atomic expansion signals to the document keys they benefit, and progressively evolves keys via stable, norm-bounded updates. We show that query and key expansion are theoretically equivalent under standard similarity functions and prove convergence of ERM's selective updates, amortizing optimal query expansion into a stable index with zero inference-time overhead. Experiments on BEIR and BRIGHT across 13 domains demonstrate consistent gains in retrieval and generation, particularly on reasoning-intensive tasks, at native retrieval speed.
Multimodal Representation Learning Conditioned on Semantic Relations
Aug 24, 2025Multimodal representation learning has advanced rapidly with contrastive models such as CLIP, which align image-text pairs in a shared embedding space. However, these models face limitations: (1) they typically focus on image-text pairs, underutilizing the semantic relations across different pairs. (2) they directly match global embeddings without contextualization, overlooking the need for semantic alignment along specific subspaces or relational dimensions; and (3) they emphasize cross-modal contrast, with limited support for intra-modal consistency. To address these issues, we propose Relation-Conditioned Multimodal Learning RCML, a framework that learns multimodal representations under natural-language relation descriptions to guide both feature extraction and alignment. Our approach constructs many-to-many training pairs linked by semantic relations and introduces a relation-guided cross-attention mechanism that modulates multimodal representations under each relation context. The training objective combines inter-modal and intra-modal contrastive losses, encouraging consistency across both modalities and semantically related samples. Experiments on different datasets show that RCML consistently outperforms strong baselines on both retrieval and classification tasks, highlighting the effectiveness of leveraging semantic relations to guide multimodal representation learning.
Network Tomography with Path-Centric Graph Neural Network
Feb 23, 2025



Network tomography is a crucial problem in network monitoring, where the observable path performance metric values are used to infer the unobserved ones, making it essential for tasks such as route selection, fault diagnosis, and traffic control. However, most existing methods either assume complete knowledge of network topology and metric formulas-an unrealistic expectation in many real-world scenarios with limited observability-or rely entirely on black-box end-to-end models. To tackle this, in this paper, we argue that a good network tomography requires synergizing the knowledge from both data and appropriate inductive bias from (partial) prior knowledge. To see this, we propose Deep Network Tomography (DeepNT), a novel framework that leverages a path-centric graph neural network to predict path performance metrics without relying on predefined hand-crafted metrics, assumptions, or the real network topology. The path-centric graph neural network learns the path embedding by inferring and aggregating the embeddings of the sequence of nodes that compose this path. Training path-centric graph neural networks requires learning the neural netowrk parameters and network topology under discrete constraints induced by the observed path performance metrics, which motivates us to design a learning objective that imposes connectivity and sparsity constraints on topology and path performance triangle inequality on path performance. Extensive experiments on real-world and synthetic datasets demonstrate the superiority of DeepNT in predicting performance metrics and inferring graph topology compared to state-of-the-art methods.
CG-RAG: Research Question Answering by Citation Graph Retrieval-Augmented LLMs
Jan 25, 2025



Research question answering requires accurate retrieval and contextual understanding of scientific literature. However, current Retrieval-Augmented Generation (RAG) methods often struggle to balance complex document relationships with precise information retrieval. In this paper, we introduce Contextualized Graph Retrieval-Augmented Generation (CG-RAG), a novel framework that integrates sparse and dense retrieval signals within graph structures to enhance retrieval efficiency and subsequently improve generation quality for research question answering. First, we propose a contextual graph representation for citation graphs, effectively capturing both explicit and implicit connections within and across documents. Next, we introduce Lexical-Semantic Graph Retrieval (LeSeGR), which seamlessly integrates sparse and dense retrieval signals with graph encoding. It bridges the gap between lexical precision and semantic understanding in citation graph retrieval, demonstrating generalizability to existing graph retrieval and hybrid retrieval methods. Finally, we present a context-aware generation strategy that utilizes the retrieved graph-structured information to generate precise and contextually enriched responses using large language models (LLMs). Extensive experiments on research question answering benchmarks across multiple domains demonstrate that our CG-RAG framework significantly outperforms RAG methods combined with various state-of-the-art retrieval approaches, delivering superior retrieval accuracy and generation quality.
HiReview: Hierarchical Taxonomy-Driven Automatic Literature Review Generation
Oct 02, 2024In this work, we present HiReview, a novel framework for hierarchical taxonomy-driven automatic literature review generation. With the exponential growth of academic documents, manual literature reviews have become increasingly labor-intensive and time-consuming, while traditional summarization models struggle to generate comprehensive document reviews effectively. Large language models (LLMs), with their powerful text processing capabilities, offer a potential solution; however, research on incorporating LLMs for automatic document generation remains limited. To address key challenges in large-scale automatic literature review generation (LRG), we propose a two-stage taxonomy-then-generation approach that combines graph-based hierarchical clustering with retrieval-augmented LLMs. First, we retrieve the most relevant sub-community within the citation network, then generate a hierarchical taxonomy tree by clustering papers based on both textual content and citation relationships. In the second stage, an LLM generates coherent and contextually accurate summaries for clusters or topics at each hierarchical level, ensuring comprehensive coverage and logical organization of the literature. Extensive experiments demonstrate that HiReview significantly outperforms state-of-the-art methods, achieving superior hierarchical organization, content relevance, and factual accuracy in automatic literature review generation tasks.
PolygonGNN: Representation Learning for Polygonal Geometries with Heterogeneous Visibility Graph
Jun 30, 2024



Polygon representation learning is essential for diverse applications, encompassing tasks such as shape coding, building pattern classification, and geographic question answering. While recent years have seen considerable advancements in this field, much of the focus has been on single polygons, overlooking the intricate inner- and inter-polygonal relationships inherent in multipolygons. To address this gap, our study introduces a comprehensive framework specifically designed for learning representations of polygonal geometries, particularly multipolygons. Central to our approach is the incorporation of a heterogeneous visibility graph, which seamlessly integrates both inner- and inter-polygonal relationships. To enhance computational efficiency and minimize graph redundancy, we implement a heterogeneous spanning tree sampling method. Additionally, we devise a rotation-translation invariant geometric representation, ensuring broader applicability across diverse scenarios. Finally, we introduce Multipolygon-GNN, a novel model tailored to leverage the spatial and semantic heterogeneity inherent in the visibility graph. Experiments on five real-world and synthetic datasets demonstrate its ability to capture informative representations for polygonal geometries.
TEG-DB: A Comprehensive Dataset and Benchmark of Textual-Edge Graphs
Jun 14, 2024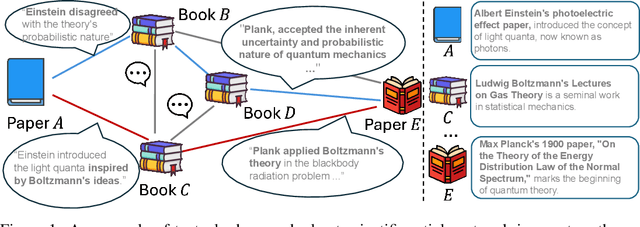
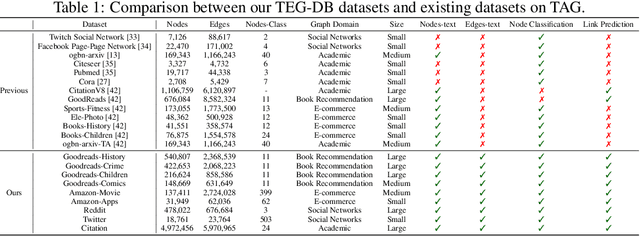
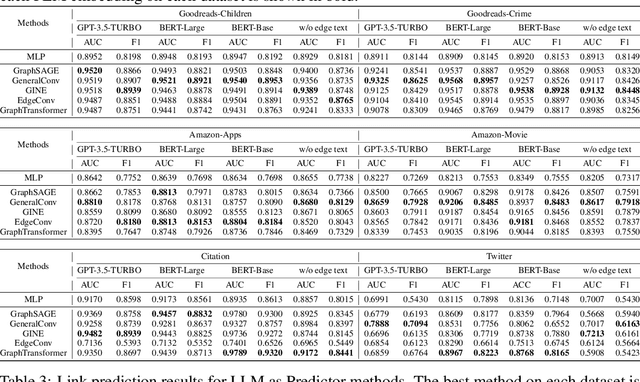
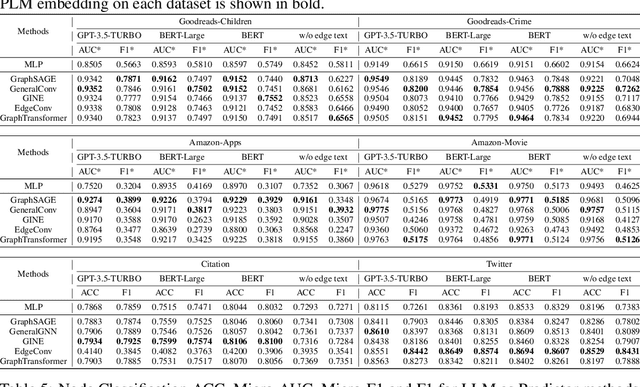
Text-Attributed Graphs (TAGs) augment graph structures with natural language descriptions, facilitating detailed depictions of data and their interconnections across various real-world settings. However, existing TAG datasets predominantly feature textual information only at the nodes, with edges typically represented by mere binary or categorical attributes. This lack of rich textual edge annotations significantly limits the exploration of contextual relationships between entities, hindering deeper insights into graph-structured data. To address this gap, we introduce Textual-Edge Graphs Datasets and Benchmark (TEG-DB), a comprehensive and diverse collection of benchmark textual-edge datasets featuring rich textual descriptions on nodes and edges. The TEG-DB datasets are large-scale and encompass a wide range of domains, from citation networks to social networks. In addition, we conduct extensive benchmark experiments on TEG-DB to assess the extent to which current techniques, including pre-trained language models, graph neural networks, and their combinations, can utilize textual node and edge information. Our goal is to elicit advancements in textual-edge graph research, specifically in developing methodologies that exploit rich textual node and edge descriptions to enhance graph analysis and provide deeper insights into complex real-world networks. The entire TEG-DB project is publicly accessible as an open-source repository on Github, accessible at https://github.com/Zhuofeng-Li/TEG-Benchmark.
TAGA: Text-Attributed Graph Self-Supervised Learning by Synergizing Graph and Text Mutual Transformations
May 27, 2024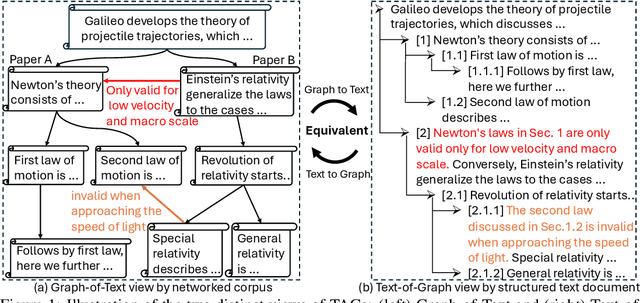
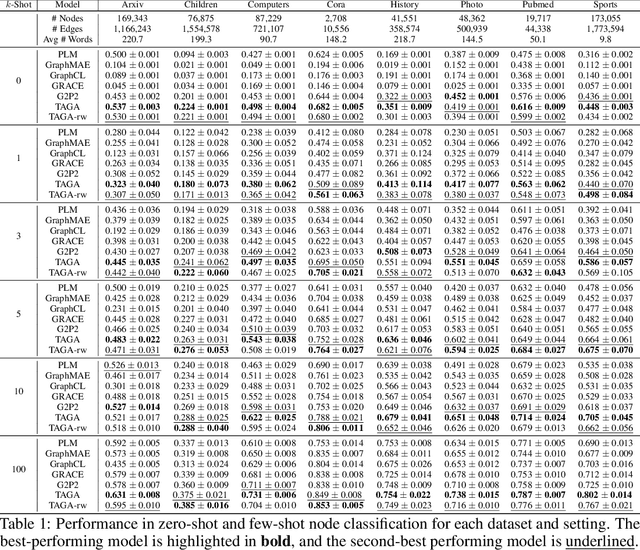
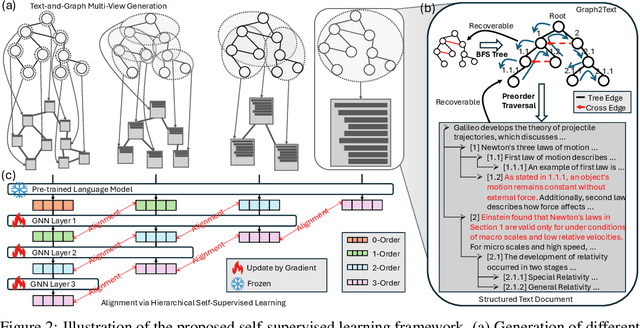
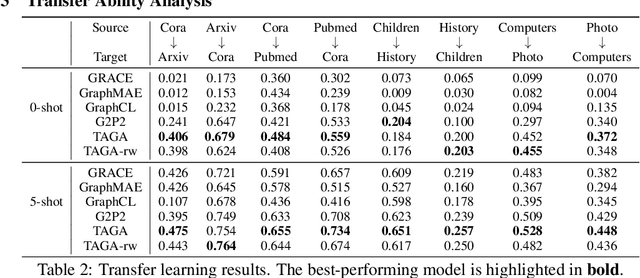
Text-Attributed Graphs (TAGs) enhance graph structures with natural language descriptions, enabling detailed representation of data and their relationships across a broad spectrum of real-world scenarios. Despite the potential for deeper insights, existing TAG representation learning primarily relies on supervised methods, necessitating extensive labeled data and limiting applicability across diverse contexts. This paper introduces a new self-supervised learning framework, Text-And-Graph Multi-View Alignment (TAGA), which overcomes these constraints by integrating TAGs' structural and semantic dimensions. TAGA constructs two complementary views: Text-of-Graph view, which organizes node texts into structured documents based on graph topology, and the Graph-of-Text view, which converts textual nodes and connections into graph data. By aligning representations from both views, TAGA captures joint textual and structural information. In addition, a novel structure-preserving random walk algorithm is proposed for efficient training on large-sized TAGs. Our framework demonstrates strong performance in zero-shot and few-shot scenarios across eight real-world datasets.
GRAG: Graph Retrieval-Augmented Generation
May 26, 2024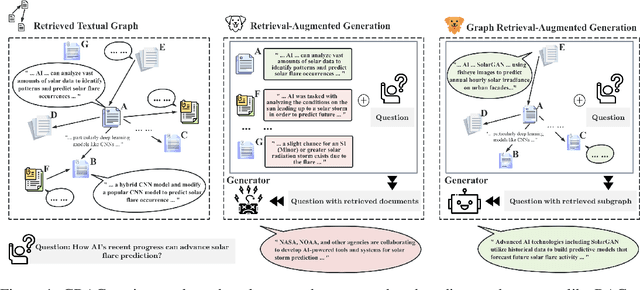

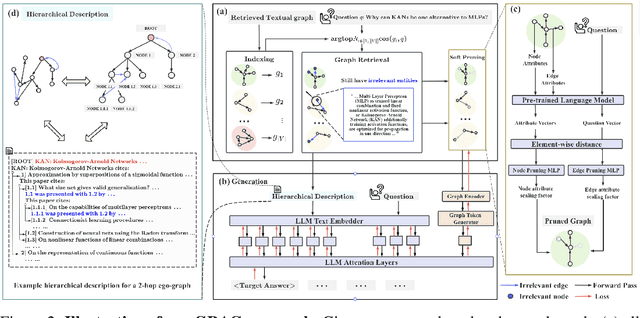
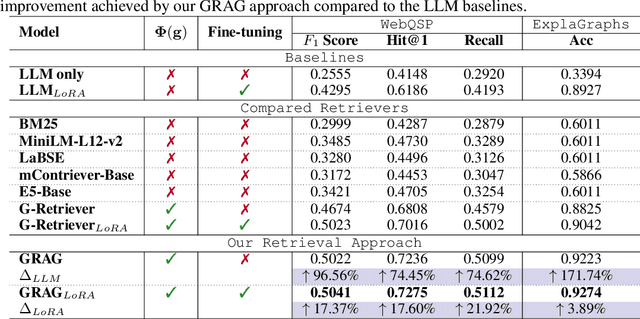
While Retrieval-Augmented Generation (RAG) enhances the accuracy and relevance of responses by generative language models, it falls short in graph-based contexts where both textual and topological information are important. Naive RAG approaches inherently neglect the structural intricacies of textual graphs, resulting in a critical gap in the generation process. To address this challenge, we introduce $\textbf{Graph Retrieval-Augmented Generation (GRAG)}$, which significantly enhances both the retrieval and generation processes by emphasizing the importance of subgraph structures. Unlike RAG approaches that focus solely on text-based entity retrieval, GRAG maintains an acute awareness of graph topology, which is crucial for generating contextually and factually coherent responses. Our GRAG approach consists of four main stages: indexing of $k$-hop ego-graphs, graph retrieval, soft pruning to mitigate the impact of irrelevant entities, and generation with pruned textual subgraphs. GRAG's core workflow-retrieving textual subgraphs followed by soft pruning-efficiently identifies relevant subgraph structures while avoiding the computational infeasibility typical of exhaustive subgraph searches, which are NP-hard. Moreover, we propose a novel prompting strategy that achieves lossless conversion from textual subgraphs to hierarchical text descriptions. Extensive experiments on graph multi-hop reasoning benchmarks demonstrate that in scenarios requiring multi-hop reasoning on textual graphs, our GRAG approach significantly outperforms current state-of-the-art RAG methods while effectively mitigating hallucinations.