 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFU-MPC: Frontier- and Uncertainty-Aware Model Predictive Control for Efficient and Accurate UAV Exploration with Motorized LiDAR
May 14, 2026Efficient UAV exploration in unknown environments requires rapid coverage expansion while maintaining accurate and reliable localization, since safe navigation in complex scenes depends on consistent mapping and pose estimation. However, for conventional LiDAR-equipped UAVs, the observable region is tightly coupled with the UAV pose and motion. Expanding coverage often requires additional translational or rotational maneuvers, which can reduce exploration efficiency and increase the risk of localization degradation in geometrically challenging environments. Motorized rotating LiDARs provide a promising solution by actively adjusting the sensor viewing direction without changing the UAV motion, thereby introducing an additional sensing degree of freedom. Nevertheless, existing exploration systems rarely exploit this scanning freedom as an explicit decision variable linked to both exploration progress and localization quality. To address this gap, we develop a UAV platform equipped with an independently actuated rotating LiDAR and propose a hierarchical exploration framework. The global planner organizes frontiers into representative viewpoints and sequences them using topology-aware transition costs. Built upon this planner, FU-MPC serves as a local receding-horizon scan controller that optimizes LiDAR rotation along the predicted flight trajectory. The controller jointly considers frontier-aware exploration utility and direction-dependent localization uncertainty, while lightweight surrogate evaluation enables real-time onboard execution. Experiments in complex environments demonstrate that the proposed system improves exploration efficiency while maintaining robust localization performance compared with fixed-pattern scanning and uncertainty-only baselines. The project page can be found at https://kafeiyin00.github.io/FU-MPC/.
S3KF: Spherical State-Space Kalman Filtering for Panoramic 3D Multi-Object Tracking
Mar 29, 2026Panoramic multi-object tracking is important for industrial safety monitoring, wide-area robotic perception, and infrastructure-light deployment in large workspaces. In these settings, the sensing system must provide full-surround coverage, metric geometric cues, and stable target association under wide field-of-view distortion and occlusion. Existing image-plane trackers are tightly coupled to the camera projection and become unreliable in panoramic imagery, while conventional Euclidean 3D formulations introduce redundant directional parameters and do not naturally unify angular, scale, and depth estimation. In this paper, we present $\mathbf{S^3KF}$, a panoramic 3D multi-object tracking framework built on a motorized rotating LiDAR and a quad-fisheye camera rig. The key idea is a geometry-consistent state representation on the unit sphere $\mathbb{S}^2$, where object bearing is modeled by a two-degree-of-freedom tangent-plane parameterization and jointly estimated with box scale and depth dynamics. Based on this state, we derive an extended spherical Kalman filtering pipeline that fuses panoramic camera detections with LiDAR depth observations for multimodal tracking. We further establish a map-based ground-truth generation pipeline using wearable localization devices registered to a shared global LiDAR map, enabling quantitative evaluation without motion-capture infrastructure. Experiments on self-collected real-world sequences show decimeter-level planar tracking accuracy, improved identity continuity over a 2D panoramic baseline in dynamic scenes, and real-time onboard operation on a Jetson AGX Orin platform. These results indicate that the proposed framework is a practical solution for panoramic perception and industrial-scale multi-object tracking.The project page can be found at https://kafeiyin00.github.io/S3KF/.
Co-Layout: LLM-driven Co-optimization for Interior Layout
Nov 16, 2025We present a novel framework for automated interior design that combines large language models (LLMs) with grid-based integer programming to jointly optimize room layout and furniture placement. Given a textual prompt, the LLM-driven agent workflow extracts structured design constraints related to room configurations and furniture arrangements. These constraints are encoded into a unified grid-based representation inspired by ``Modulor". Our formulation accounts for key design requirements, including corridor connectivity, room accessibility, spatial exclusivity, and user-specified preferences. To improve computational efficiency, we adopt a coarse-to-fine optimization strategy that begins with a low-resolution grid to solve a simplified problem and guides the solution at the full resolution. Experimental results across diverse scenarios demonstrate that our joint optimization approach significantly outperforms existing two-stage design pipelines in solution quality, and achieves notable computational efficiency through the coarse-to-fine strategy.
STARC: See-Through-Wall Augmented Reality Framework for Human-Robot Collaboration in Emergency Response
Sep 19, 2025In emergency response missions, first responders must navigate cluttered indoor environments where occlusions block direct line-of-sight, concealing both life-threatening hazards and victims in need of rescue. We present STARC, a see-through AR framework for human-robot collaboration that fuses mobile-robot mapping with responder-mounted LiDAR sensing. A ground robot running LiDAR-inertial odometry performs large-area exploration and 3D human detection, while helmet- or handheld-mounted LiDAR on the responder is registered to the robot's global map via relative pose estimation. This cross-LiDAR alignment enables consistent first-person projection of detected humans and their point clouds - rendered in AR with low latency - into the responder's view. By providing real-time visualization of hidden occupants and hazards, STARC enhances situational awareness and reduces operator risk. Experiments in simulation, lab setups, and tactical field trials confirm robust pose alignment, reliable detections, and stable overlays, underscoring the potential of our system for fire-fighting, disaster relief, and other safety-critical operations. Code and design will be open-sourced upon acceptance.
PERAL: Perception-Aware Motion Control for Passive LiDAR Excitation in Spherical Robots
Sep 18, 2025Autonomous mobile robots increasingly rely on LiDAR-IMU odometry for navigation and mapping, yet horizontally mounted LiDARs such as the MID360 capture few near-ground returns, limiting terrain awareness and degrading performance in feature-scarce environments. Prior solutions - static tilt, active rotation, or high-density sensors - either sacrifice horizontal perception or incur added actuators, cost, and power. We introduce PERAL, a perception-aware motion control framework for spherical robots that achieves passive LiDAR excitation without dedicated hardware. By modeling the coupling between internal differential-drive actuation and sensor attitude, PERAL superimposes bounded, non-periodic oscillations onto nominal goal- or trajectory-tracking commands, enriching vertical scan diversity while preserving navigation accuracy. Implemented on a compact spherical robot, PERAL is validated across laboratory, corridor, and tactical environments. Experiments demonstrate up to 96 percent map completeness, a 27 percent reduction in trajectory tracking error, and robust near-ground human detection, all at lower weight, power, and cost compared with static tilt, active rotation, and fixed horizontal baselines. The design and code will be open-sourced upon acceptance.
AEOS: Active Environment-aware Optimal Scanning Control for UAV LiDAR-Inertial Odometry in Complex Scenes
Sep 11, 2025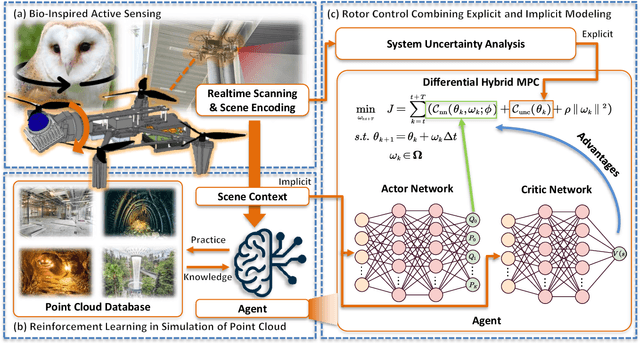

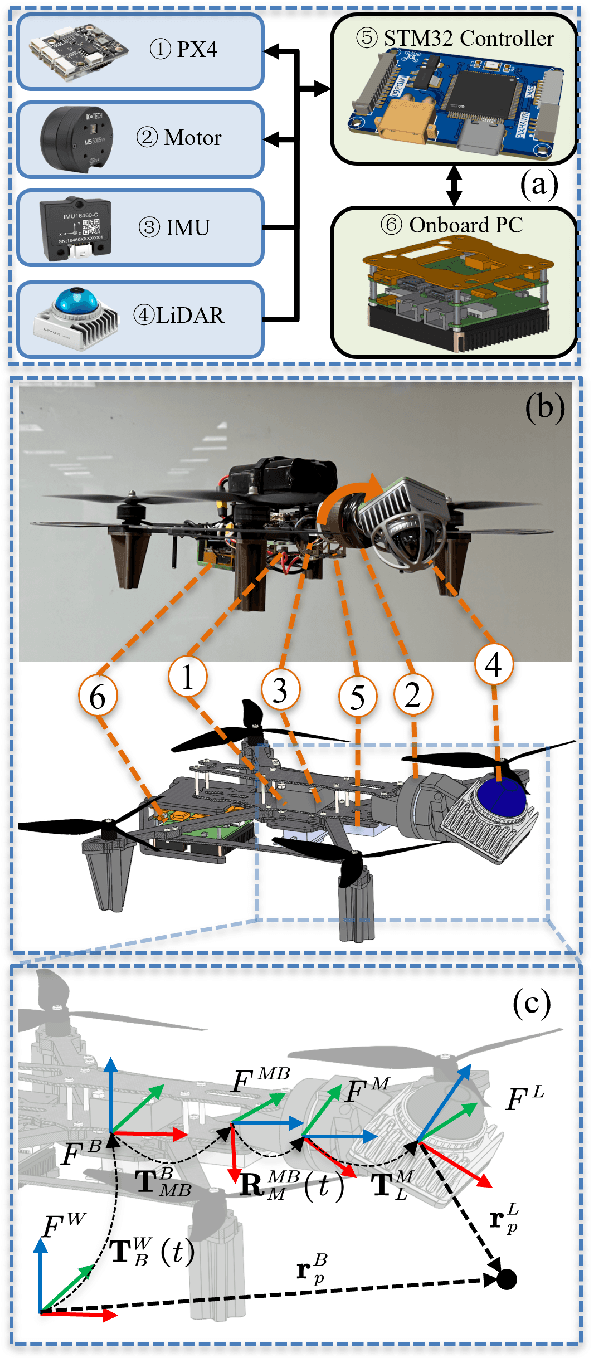
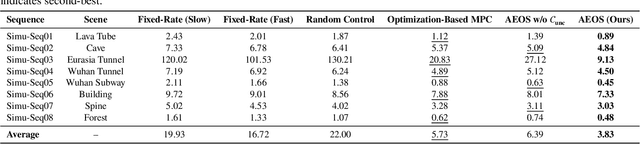
LiDAR-based 3D perception and localization on unmanned aerial vehicles (UAVs) are fundamentally limited by the narrow field of view (FoV) of compact LiDAR sensors and the payload constraints that preclude multi-sensor configurations. Traditional motorized scanning systems with fixed-speed rotations lack scene awareness and task-level adaptability, leading to degraded odometry and mapping performance in complex, occluded environments. Inspired by the active sensing behavior of owls, we propose AEOS (Active Environment-aware Optimal Scanning), a biologically inspired and computationally efficient framework for adaptive LiDAR control in UAV-based LiDAR-Inertial Odometry (LIO). AEOS combines model predictive control (MPC) and reinforcement learning (RL) in a hybrid architecture: an analytical uncertainty model predicts future pose observability for exploitation, while a lightweight neural network learns an implicit cost map from panoramic depth representations to guide exploration. To support scalable training and generalization, we develop a point cloud-based simulation environment with real-world LiDAR maps across diverse scenes, enabling sim-to-real transfer. Extensive experiments in both simulation and real-world environments demonstrate that AEOS significantly improves odometry accuracy compared to fixed-rate, optimization-only, and fully learned baselines, while maintaining real-time performance under onboard computational constraints. The project page can be found at https://kafeiyin00.github.io/AEOS/.
LiMo-Calib: On-Site Fast LiDAR-Motor Calibration for Quadruped Robot-Based Panoramic 3D Sensing System
Feb 18, 2025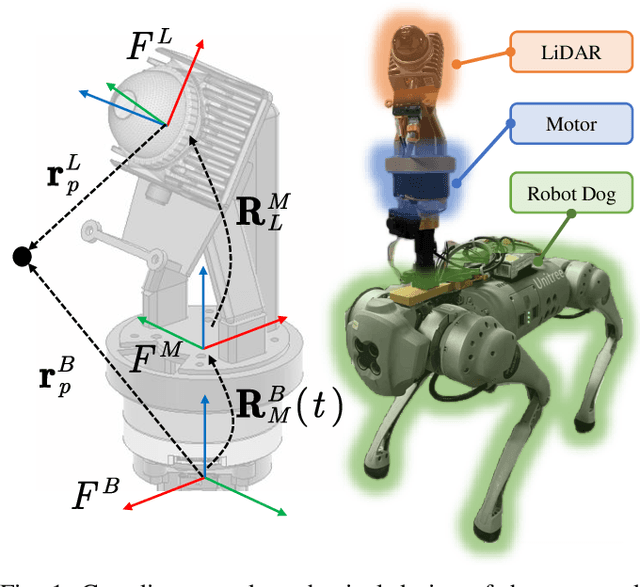
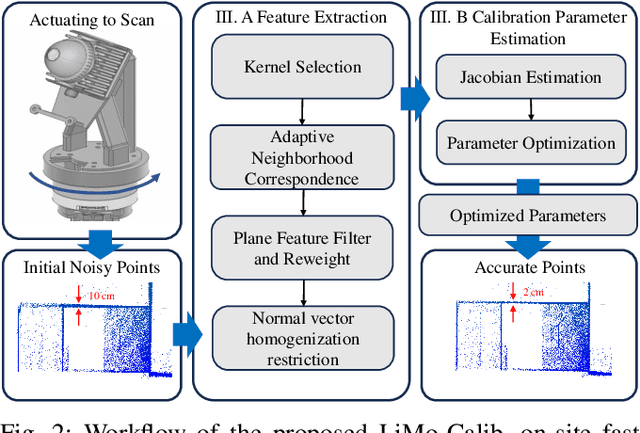
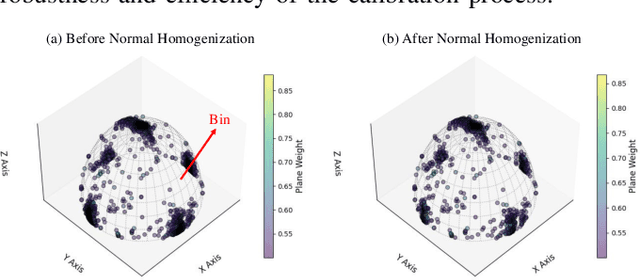

Conventional single LiDAR systems are inherently constrained by their limited field of view (FoV), leading to blind spots and incomplete environmental awareness, particularly on robotic platforms with strict payload limitations. Integrating a motorized LiDAR offers a practical solution by significantly expanding the sensor's FoV and enabling adaptive panoramic 3D sensing. However, the high-frequency vibrations of the quadruped robot introduce calibration challenges, causing variations in the LiDAR-motor transformation that degrade sensing accuracy. Existing calibration methods that use artificial targets or dense feature extraction lack feasibility for on-site applications and real-time implementation. To overcome these limitations, we propose LiMo-Calib, an efficient on-site calibration method that eliminates the need for external targets by leveraging geometric features directly from raw LiDAR scans. LiMo-Calib optimizes feature selection based on normal distribution to accelerate convergence while maintaining accuracy and incorporates a reweighting mechanism that evaluates local plane fitting quality to enhance robustness. We integrate and validate the proposed method on a motorized LiDAR system mounted on a quadruped robot, demonstrating significant improvements in calibration efficiency and 3D sensing accuracy, making LiMo-Calib well-suited for real-world robotic applications. The demo video is available at: https://youtu.be/FMINa-sap7g
TEG-DB: A Comprehensive Dataset and Benchmark of Textual-Edge Graphs
Jun 14, 2024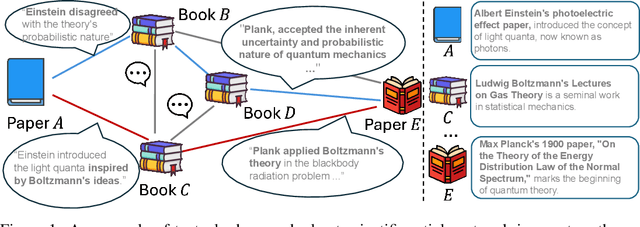
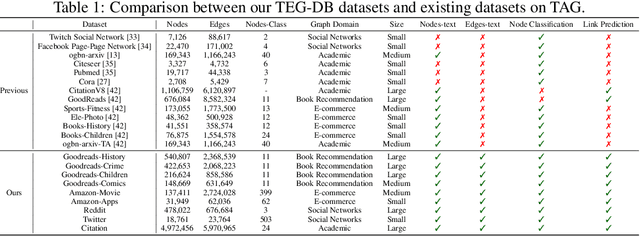
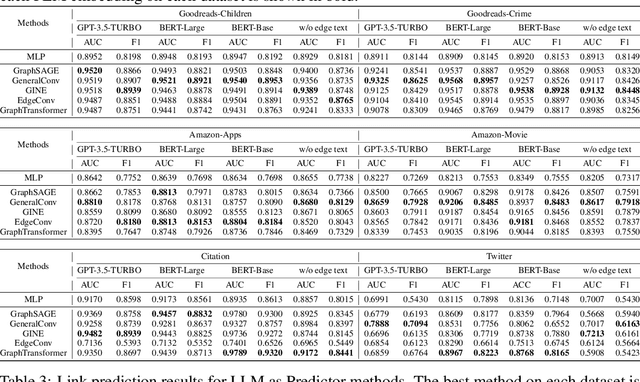
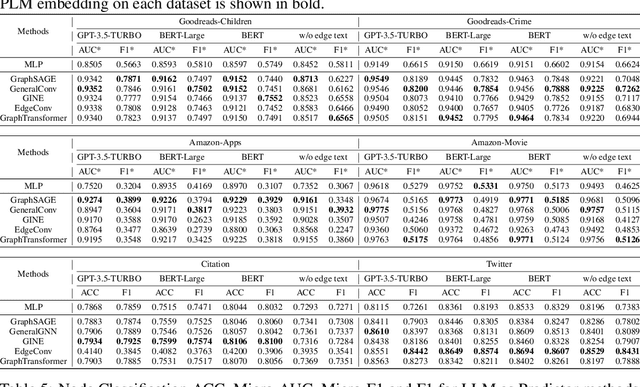
Text-Attributed Graphs (TAGs) augment graph structures with natural language descriptions, facilitating detailed depictions of data and their interconnections across various real-world settings. However, existing TAG datasets predominantly feature textual information only at the nodes, with edges typically represented by mere binary or categorical attributes. This lack of rich textual edge annotations significantly limits the exploration of contextual relationships between entities, hindering deeper insights into graph-structured data. To address this gap, we introduce Textual-Edge Graphs Datasets and Benchmark (TEG-DB), a comprehensive and diverse collection of benchmark textual-edge datasets featuring rich textual descriptions on nodes and edges. The TEG-DB datasets are large-scale and encompass a wide range of domains, from citation networks to social networks. In addition, we conduct extensive benchmark experiments on TEG-DB to assess the extent to which current techniques, including pre-trained language models, graph neural networks, and their combinations, can utilize textual node and edge information. Our goal is to elicit advancements in textual-edge graph research, specifically in developing methodologies that exploit rich textual node and edge descriptions to enhance graph analysis and provide deeper insights into complex real-world networks. The entire TEG-DB project is publicly accessible as an open-source repository on Github, accessible at https://github.com/Zhuofeng-Li/TEG-Benchmark.
DreamMat: High-quality PBR Material Generation with Geometry- and Light-aware Diffusion Models
May 27, 20242D diffusion model, which often contains unwanted baked-in shading effects and results in unrealistic rendering effects in the downstream applications. Generating Physically Based Rendering (PBR) materials instead of just RGB textures would be a promising solution. However, directly distilling the PBR material parameters from 2D diffusion models still suffers from incorrect material decomposition, such as baked-in shading effects in albedo. We introduce DreamMat, an innovative approach to resolve the aforementioned problem, to generate high-quality PBR materials from text descriptions. We find out that the main reason for the incorrect material distillation is that large-scale 2D diffusion models are only trained to generate final shading colors, resulting in insufficient constraints on material decomposition during distillation. To tackle this problem, we first finetune a new light-aware 2D diffusion model to condition on a given lighting environment and generate the shading results on this specific lighting condition. Then, by applying the same environment lights in the material distillation, DreamMat can generate high-quality PBR materials that are not only consistent with the given geometry but also free from any baked-in shading effects in albedo. Extensive experiments demonstrate that the materials produced through our methods exhibit greater visual appeal to users and achieve significantly superior rendering quality compared to baseline methods, which are preferable for downstream tasks such as game and film production.