 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTEG-DB: A Comprehensive Dataset and Benchmark of Textual-Edge Graphs
Jun 14, 2024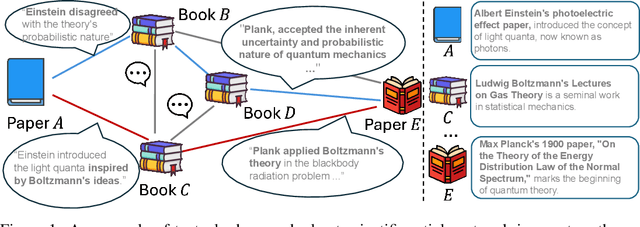
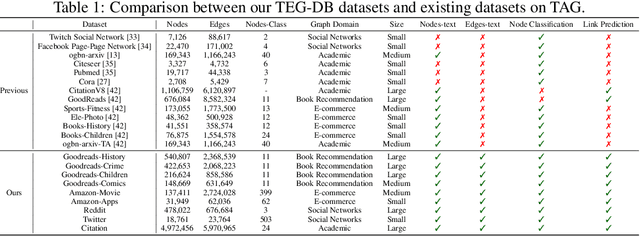
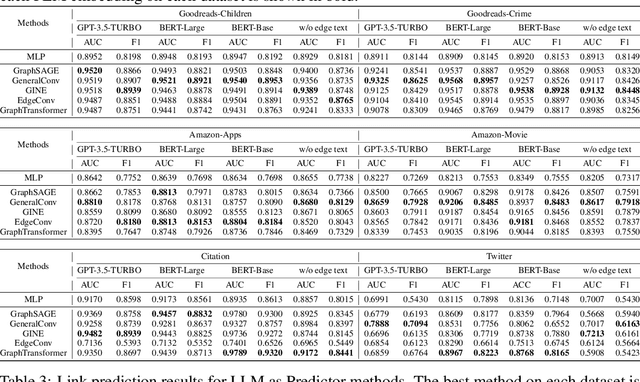
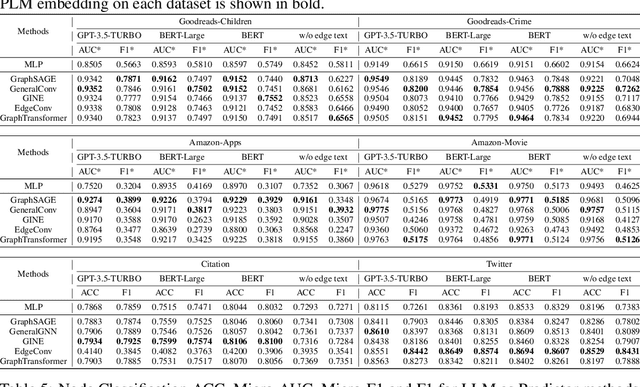
Text-Attributed Graphs (TAGs) augment graph structures with natural language descriptions, facilitating detailed depictions of data and their interconnections across various real-world settings. However, existing TAG datasets predominantly feature textual information only at the nodes, with edges typically represented by mere binary or categorical attributes. This lack of rich textual edge annotations significantly limits the exploration of contextual relationships between entities, hindering deeper insights into graph-structured data. To address this gap, we introduce Textual-Edge Graphs Datasets and Benchmark (TEG-DB), a comprehensive and diverse collection of benchmark textual-edge datasets featuring rich textual descriptions on nodes and edges. The TEG-DB datasets are large-scale and encompass a wide range of domains, from citation networks to social networks. In addition, we conduct extensive benchmark experiments on TEG-DB to assess the extent to which current techniques, including pre-trained language models, graph neural networks, and their combinations, can utilize textual node and edge information. Our goal is to elicit advancements in textual-edge graph research, specifically in developing methodologies that exploit rich textual node and edge descriptions to enhance graph analysis and provide deeper insights into complex real-world networks. The entire TEG-DB project is publicly accessible as an open-source repository on Github, accessible at https://github.com/Zhuofeng-Li/TEG-Benchmark.