 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAWARE: Adaptive Whole-body Active Rotating Control for Enhanced LiDAR-Inertial Odometry under Human-in-the-Loop Interaction
Apr 12, 2026Human-in-the-loop (HITL) UAV operation is essential in complex and safety-critical aerial surveying environments, where human operators provide navigation intent while onboard autonomy must maintain accurate and robust state estimation. A key challenge in this setting is that resource-constrained UAV platforms are often limited to narrow-field-of-view LiDAR sensors. In geometrically degenerate or feature-sparse scenes, limited sensing coverage often weakens LiDAR Inertial Odometry (LIO)'s observability, causing drift accumulation, degraded geometric accuracy, and unstable state estimation, which directly compromise safe and effective HITL operation and the reliability of downstream surveying products. To overcome this limitation, we present AWARE, a bio-inspired whole-body active yawing framework that exploits the UAV's own rotational agility to extend the effective sensor horizon and improve LIO's observability without additional mechanical actuation. The core of AWARE is a differentiable Model Predictive Control (MPC) framework embedded in a Reinforcement Learning (RL) loop. It first identifies the viewing direction that maximizes information gain across the full yaw space, and a lightweight RL agent then adjusts the MPC cost weights online according to the current environmental context, enabling an adaptive balance between estimation accuracy and flight stability. A Safe Flight Corridor mechanism further ensures operational safety within this HITL paradigm by decoupling the operator's navigational intent from autonomous yaw optimization to enable safe and efficient cooperative control. We validate AWARE through extensive experiments in diverse simulated and real-world environments.
TOL: Textual Localization with OpenStreetMap
Apr 02, 2026Natural language provides an intuitive way to express spatial intent in geospatial applications. While existing localization methods often rely on dense point cloud maps or high-resolution imagery, OpenStreetMap (OSM) offers a compact and freely available map representation that encodes rich semantic and structural information, making it well suited for large-scale localization. However, text-to-OSM (T2O) localization remains largely unexplored. In this paper, we formulate the T2O global localization task, which aims to estimate accurate 2 degree-of-freedom (DoF) positions in urban environments from textual scene descriptions without relying on geometric observations or GNSS-based initial location. To support the proposed task, we introduce TOL, a large-scale benchmark spanning multiple continents and diverse urban environments. TOL contains approximately 121K textual queries paired with OSM map tiles and covers about 316 km of road trajectories across Boston, Karlsruhe, and Singapore. We further propose TOLoc, a coarse-to-fine localization framework that explicitly models the semantics of surrounding objects and their directional information. In the coarse stage, direction-aware features are extracted from both textual descriptions and OSM tiles to construct global descriptors, which are used to retrieve candidate locations for the query. In the fine stage, the query text and top-1 retrieved tile are jointly processed, where a dedicated alignment module fuses textual descriptor and local map features to regress the 2-DoF pose. Experimental results demonstrate that TOLoc achieves strong localization performance, outperforming the best existing method by 6.53%, 9.93%, and 8.31% at 5m, 10m, and 25m thresholds, respectively, and shows strong generalization to unseen environments. Dataset, code and models will be publicly available at: https://github.com/WHU-USI3DV/TOL.
S3KF: Spherical State-Space Kalman Filtering for Panoramic 3D Multi-Object Tracking
Mar 29, 2026Panoramic multi-object tracking is important for industrial safety monitoring, wide-area robotic perception, and infrastructure-light deployment in large workspaces. In these settings, the sensing system must provide full-surround coverage, metric geometric cues, and stable target association under wide field-of-view distortion and occlusion. Existing image-plane trackers are tightly coupled to the camera projection and become unreliable in panoramic imagery, while conventional Euclidean 3D formulations introduce redundant directional parameters and do not naturally unify angular, scale, and depth estimation. In this paper, we present $\mathbf{S^3KF}$, a panoramic 3D multi-object tracking framework built on a motorized rotating LiDAR and a quad-fisheye camera rig. The key idea is a geometry-consistent state representation on the unit sphere $\mathbb{S}^2$, where object bearing is modeled by a two-degree-of-freedom tangent-plane parameterization and jointly estimated with box scale and depth dynamics. Based on this state, we derive an extended spherical Kalman filtering pipeline that fuses panoramic camera detections with LiDAR depth observations for multimodal tracking. We further establish a map-based ground-truth generation pipeline using wearable localization devices registered to a shared global LiDAR map, enabling quantitative evaluation without motion-capture infrastructure. Experiments on self-collected real-world sequences show decimeter-level planar tracking accuracy, improved identity continuity over a 2D panoramic baseline in dynamic scenes, and real-time onboard operation on a Jetson AGX Orin platform. These results indicate that the proposed framework is a practical solution for panoramic perception and industrial-scale multi-object tracking.The project page can be found at https://kafeiyin00.github.io/S3KF/.
OmniVLN: Omnidirectional 3D Perception and Token-Efficient LLM Reasoning for Visual-Language Navigation across Air and Ground Platforms
Mar 18, 2026Language-guided embodied navigation requires an agent to interpret object-referential instructions, search across multiple rooms, localize the referenced target, and execute reliable motion toward it. Existing systems remain limited in real indoor environments because narrow field-of-view sensing exposes only a partial local scene at each step, often forcing repeated rotations, delaying target discovery, and producing fragmented spatial understanding; meanwhile, directly prompting LLMs with dense 3D maps or exhaustive object lists quickly exceeds the context budget. We present OmniVLN, a zero-shot visual-language navigation framework that couples omnidirectional 3D perception with token-efficient hierarchical reasoning for both aerial and ground robots. OmniVLN fuses a rotating LiDAR and panoramic vision into a hardware-agnostic mapping stack, incrementally constructs a five-layer Dynamic Scene Graph (DSG) from mesh geometry to room- and building-level structure, and stabilizes high-level topology through persistent-homology-based room partitioning and hybrid geometric/VLM relation verification. For navigation, the global DSG is transformed into an agent-centric 3D octant representation with multi-resolution spatial attention prompting, enabling the LLM to progressively filter candidate rooms, infer egocentric orientation, localize target objects, and emit executable navigation primitives while preserving fine local detail and compact long-range memory. Experiments show that the proposed hierarchical interface improves spatial referring accuracy from 77.27\% to 93.18\%, reduces cumulative prompt tokens by up to 61.7\% in cluttered multi-room settings, and improves navigation success by up to 11.68\% over a flat-list baseline. We will release the code and an omnidirectional multimodal dataset to support reproducible research.
Detecting Miscitation on the Scholarly Web through LLM-Augmented Text-Rich Graph Learning
Mar 10, 2026Scholarly web is a vast network of knowledge connected by citations. However, this system is increasingly compromised by miscitation, where references do not support or even contradict the claims they are cited for. Current miscitation detection methods, which primarily rely on semantic similarity or network anomalies, struggle to capture the nuanced relationship between a citation's context and its place in the wider network. While large language models (LLMs) offer powerful capabilities in semantic reasoning for this task, their deployment is hindered by hallucination risks and high computational costs. In this work, we introduce LLM-Augmented Graph Learning-based Miscitation Detector (LAGMiD), a novel framework that leverages LLMs for deep semantic reasoning over citation graphs and distills this knowledge into graph neural networks (GNNs) for efficient and scalable miscitation detection. Specifically, LAGMiD introduces an evidence-chain reasoning mechanism, which uses chain-of-thought prompting, to perform multi-hop citation tracing and assess semantic fidelity. To reduce LLM inference costs, we design a knowledge distillation method aligning GNN embeddings with intermediate LLM reasoning states. A collaborative learning strategy further routes complex cases to the LLM while optimizing the GNN for structure-based generalization. Experiments on three real-world benchmarks show that LAGMiD achieves state-of-the-art miscitation detection with significantly reduced inference cost.
Accurate Calibration and Robust LiDAR-Inertial Odometry for Spinning Actuated LiDAR Systems
Jan 24, 2026Accurate calibration and robust localization are fundamental for downstream tasks in spinning actuated LiDAR applications. Existing methods, however, require parameterizing extrinsic parameters based on different mounting configurations, limiting their generalizability. Additionally, spinning actuated LiDAR inevitably scans featureless regions, which complicates the balance between scanning coverage and localization robustness. To address these challenges, this letter presents a targetless LiDAR-motor calibration (LM-Calibr) on the basis of the Denavit-Hartenberg convention and an environmental adaptive LiDAR-inertial odometry (EVA-LIO). LM-Calibr supports calibration of LiDAR-motor systems with various mounting configurations. Extensive experiments demonstrate its accuracy and convergence across different scenarios, mounting angles, and initial values. Additionally, EVA-LIO adaptively selects downsample rates and map resolutions according to spatial scale. This adaptivity enables the actuator to operate at maximum speed, thereby enhancing scanning completeness while ensuring robust localization, even when LiDAR briefly scans featureless areas. The source code and hardware design are available on GitHub: \textcolor{blue}{\href{https://github.com/zijiechenrobotics/lm_calibr}{github.com/zijiechenrobotics/lm\_calibr}}. The video is available at \textcolor{blue}{\href{https://youtu.be/cZyyrkmeoSk}{youtu.be/cZyyrkmeoSk}}
WHU-PCPR: A cross-platform heterogeneous point cloud dataset for place recognition in complex urban scenes
Jan 10, 2026Point Cloud-based Place Recognition (PCPR) demonstrates considerable potential in applications such as autonomous driving, robot localization and navigation, and map update. In practical applications, point clouds used for place recognition are often acquired from different platforms and LiDARs across varying scene. However, existing PCPR datasets lack diversity in scenes, platforms, and sensors, which limits the effective development of related research. To address this gap, we establish WHU-PCPR, a cross-platform heterogeneous point cloud dataset designed for place recognition. The dataset differentiates itself from existing datasets through its distinctive characteristics: 1) cross-platform heterogeneous point clouds: collected from survey-grade vehicle-mounted Mobile Laser Scanning (MLS) systems and low-cost Portable helmet-mounted Laser Scanning (PLS) systems, each equipped with distinct mechanical and solid-state LiDAR sensors. 2) Complex localization scenes: encompassing real-time and long-term changes in both urban and campus road scenes. 3) Large-scale spatial coverage: featuring 82.3 km of trajectory over a 60-month period and an unrepeated route of approximately 30 km. Based on WHU-PCPR, we conduct extensive evaluation and in-depth analysis of several representative PCPR methods, and provide a concise discussion of key challenges and future research directions. The dataset and benchmark code are available at https://github.com/zouxianghong/WHU-PCPR.
AEOS: Active Environment-aware Optimal Scanning Control for UAV LiDAR-Inertial Odometry in Complex Scenes
Sep 11, 2025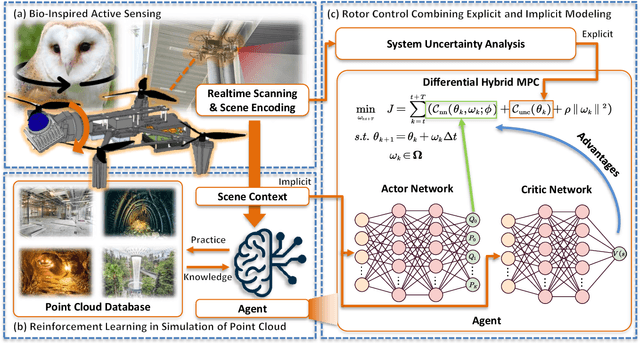

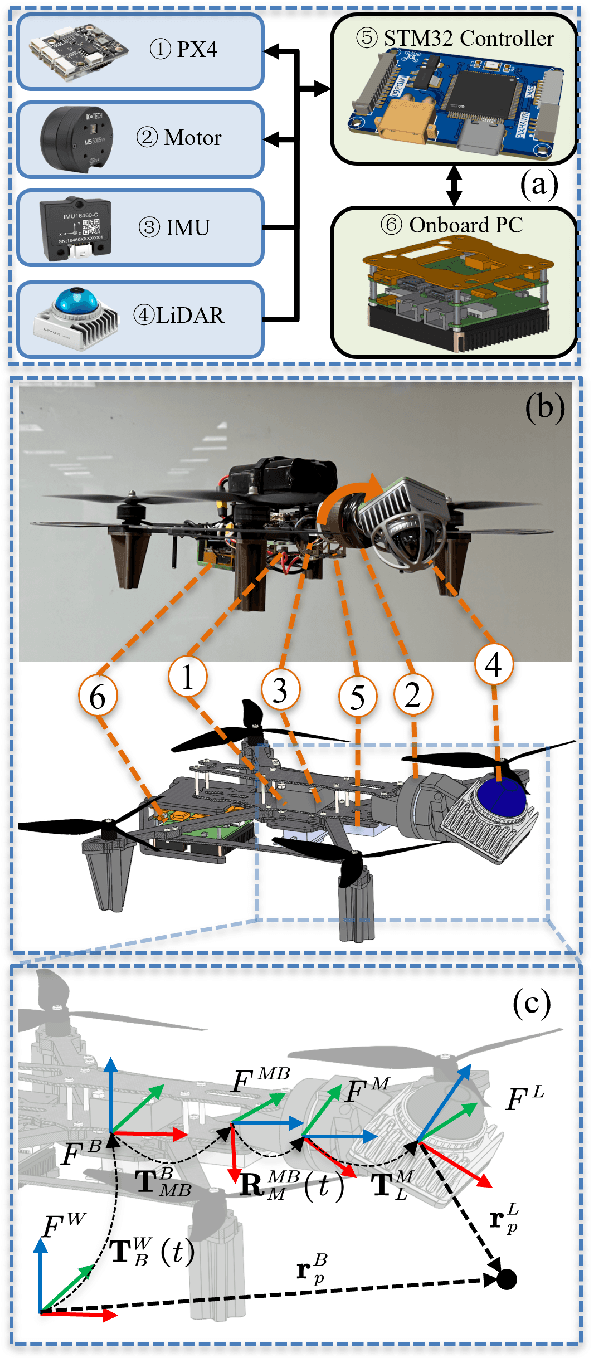
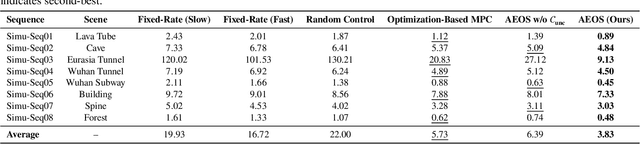
LiDAR-based 3D perception and localization on unmanned aerial vehicles (UAVs) are fundamentally limited by the narrow field of view (FoV) of compact LiDAR sensors and the payload constraints that preclude multi-sensor configurations. Traditional motorized scanning systems with fixed-speed rotations lack scene awareness and task-level adaptability, leading to degraded odometry and mapping performance in complex, occluded environments. Inspired by the active sensing behavior of owls, we propose AEOS (Active Environment-aware Optimal Scanning), a biologically inspired and computationally efficient framework for adaptive LiDAR control in UAV-based LiDAR-Inertial Odometry (LIO). AEOS combines model predictive control (MPC) and reinforcement learning (RL) in a hybrid architecture: an analytical uncertainty model predicts future pose observability for exploitation, while a lightweight neural network learns an implicit cost map from panoramic depth representations to guide exploration. To support scalable training and generalization, we develop a point cloud-based simulation environment with real-world LiDAR maps across diverse scenes, enabling sim-to-real transfer. Extensive experiments in both simulation and real-world environments demonstrate that AEOS significantly improves odometry accuracy compared to fixed-rate, optimization-only, and fully learned baselines, while maintaining real-time performance under onboard computational constraints. The project page can be found at https://kafeiyin00.github.io/AEOS/.
Aerial-ground Cross-modal Localization: Dataset, Ground-truth, and Benchmark
Sep 09, 2025Accurate visual localization in dense urban environments poses a fundamental task in photogrammetry, geospatial information science, and robotics. While imagery is a low-cost and widely accessible sensing modality, its effectiveness on visual odometry is often limited by textureless surfaces, severe viewpoint changes, and long-term drift. The growing public availability of airborne laser scanning (ALS) data opens new avenues for scalable and precise visual localization by leveraging ALS as a prior map. However, the potential of ALS-based localization remains underexplored due to three key limitations: (1) the lack of platform-diverse datasets, (2) the absence of reliable ground-truth generation methods applicable to large-scale urban environments, and (3) limited validation of existing Image-to-Point Cloud (I2P) algorithms under aerial-ground cross-platform settings. To overcome these challenges, we introduce a new large-scale dataset that integrates ground-level imagery from mobile mapping systems with ALS point clouds collected in Wuhan, Hong Kong, and San Francisco.
ARMOR: Adaptive Meshing with Reinforcement Optimization for Real-time 3D Monitoring in Unexposed Scenes
Apr 28, 2025Unexposed environments, such as lava tubes, mines, and tunnels, are among the most complex yet strategically significant domains for scientific exploration and infrastructure development. Accurate and real-time 3D meshing of these environments is essential for applications including automated structural assessment, robotic-assisted inspection, and safety monitoring. Implicit neural Signed Distance Fields (SDFs) have shown promising capabilities in online meshing; however, existing methods often suffer from large projection errors and rely on fixed reconstruction parameters, limiting their adaptability to complex and unstructured underground environments such as tunnels, caves, and lava tubes. To address these challenges, this paper proposes ARMOR, a scene-adaptive and reinforcement learning-based framework for real-time 3D meshing in unexposed environments. The proposed method was validated across more than 3,000 meters of underground environments, including engineered tunnels, natural caves, and lava tubes. Experimental results demonstrate that ARMOR achieves superior performance in real-time mesh reconstruction, reducing geometric error by 3.96\% compared to state-of-the-art baselines, while maintaining real-time efficiency. The method exhibits improved robustness, accuracy, and adaptability, indicating its potential for advanced 3D monitoring and mapping in challenging unexposed scenarios. The project page can be found at: https://yizhezhang0418.github.io/armor.github.io/