 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOPAL: Visibility-aware LiDAR-to-OpenStreetMap Place Recognition via Adaptive Radial Fusion
Apr 30, 2025LiDAR place recognition is a critical capability for autonomous navigation and cross-modal localization in large-scale outdoor environments. Existing approaches predominantly depend on pre-built 3D dense maps or aerial imagery, which impose significant storage overhead and lack real-time adaptability. In this paper, we propose OPAL, a novel network for LiDAR place recognition that leverages OpenStreetMap (OSM) as a lightweight and up-to-date prior. Our key innovation lies in bridging the domain disparity between sparse LiDAR scans and structured OSM data through two carefully designed components. First, a cross-modal visibility mask that identifies maximal observable regions from both modalities to guide feature learning. Second, an adaptive radial fusion module that dynamically consolidates radial features into discriminative global descriptors. Extensive experiments on the KITTI and KITTI-360 datasets demonstrate OPAL's superiority, achieving 15.98% higher recall at @1m threshold for top-1 retrieved matches, along with 12x faster inference speed compared to the state-of-the-art approach. Code and datasets will be publicly available.
OSMLoc: Single Image-Based Visual Localization in OpenStreetMap with Geometric and Semantic Guidances
Nov 13, 2024



OpenStreetMap (OSM), an online and versatile source of volunteered geographic information (VGI), is widely used for human self-localization by matching nearby visual observations with vectorized map data. However, due to the divergence in modalities and views, image-to-OSM (I2O) matching and localization remain challenging for robots, preventing the full utilization of VGI data in the unmanned ground vehicles and logistic industry. Inspired by the fact that the human brain relies on geometric and semantic understanding of sensory information for spatial localization tasks, we propose the OSMLoc in this paper. OSMLoc is a brain-inspired single-image visual localization method with semantic and geometric guidance to improve accuracy, robustness, and generalization ability. First, we equip the OSMLoc with the visual foundational model to extract powerful image features. Second, a geometry-guided depth distribution adapter is proposed to bridge the monocular depth estimation and camera-to-BEV transform. Thirdly, the semantic embeddings from the OSM data are utilized as auxiliary guidance for image-to-OSM feature matching. To validate the proposed OSMLoc, we collect a worldwide cross-area and cross-condition (CC) benchmark for extensive evaluation. Experiments on the MGL dataset, CC validation benchmark, and KITTI dataset have demonstrated the superiority of our method. Code, pre-trained models, CC validation benchmark, and additional results are available on: https://github.com/WHU-USI3DV/OSMLoc
Mobile-Seed: Joint Semantic Segmentation and Boundary Detection for Mobile Robots
Nov 23, 2023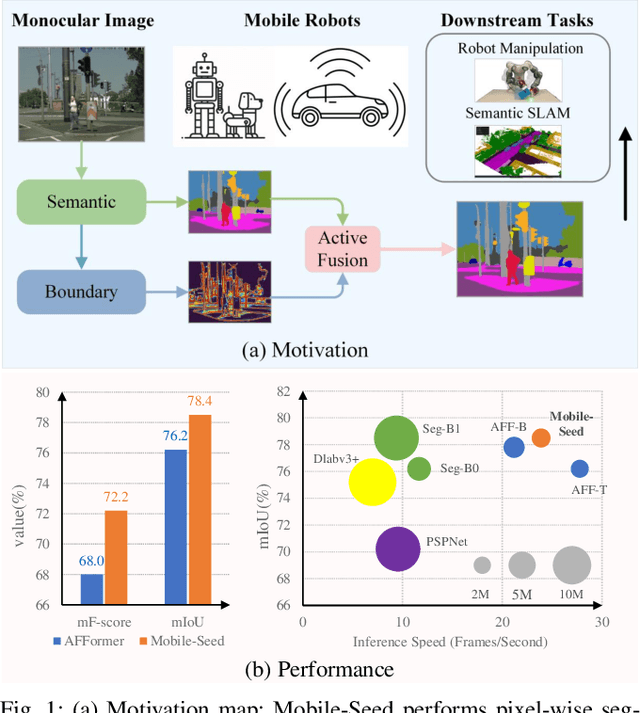
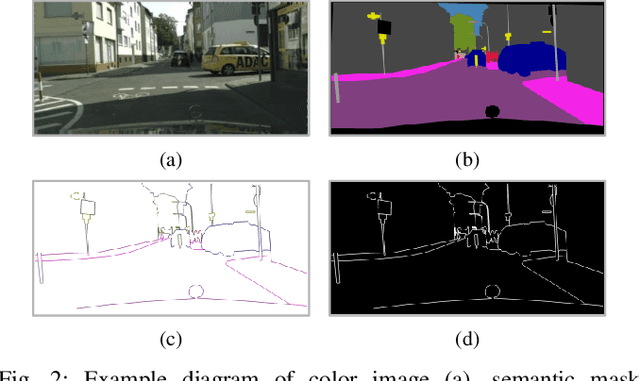
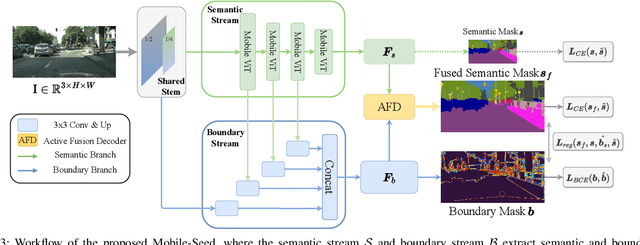
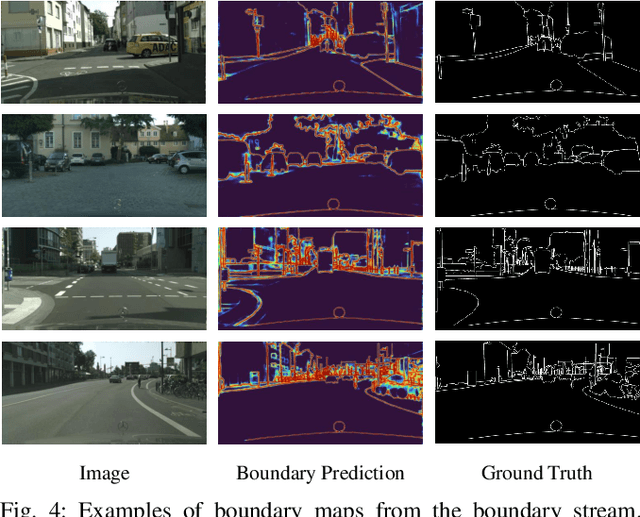
Precise and rapid delineation of sharp boundaries and robust semantics is essential for numerous downstream robotic tasks, such as robot grasping and manipulation, real-time semantic mapping, and online sensor calibration performed on edge computing units. Although boundary detection and semantic segmentation are complementary tasks, most studies focus on lightweight models for semantic segmentation but overlook the critical role of boundary detection. In this work, we introduce Mobile-Seed, a lightweight, dual-task framework tailored for simultaneous semantic segmentation and boundary detection. Our framework features a two-stream encoder, an active fusion decoder (AFD) and a dual-task regularization approach. The encoder is divided into two pathways: one captures category-aware semantic information, while the other discerns boundaries from multi-scale features. The AFD module dynamically adapts the fusion of semantic and boundary information by learning channel-wise relationships, allowing for precise weight assignment of each channel. Furthermore, we introduce a regularization loss to mitigate the conflicts in dual-task learning and deep diversity supervision. Compared to existing methods, the proposed Mobile-Seed offers a lightweight framework to simultaneously improve semantic segmentation performance and accurately locate object boundaries. Experiments on the Cityscapes dataset have shown that Mobile-Seed achieves notable improvement over the state-of-the-art (SOTA) baseline by 2.2 percentage points (pp) in mIoU and 4.2 pp in mF-score, while maintaining an online inference speed of 23.9 frames-per-second (FPS) with 1024x2048 resolution input on an RTX 2080 Ti GPU. Additional experiments on CamVid and PASCAL Context datasets confirm our method's generalizability. Code and additional results are publicly available at https://whu-usi3dv.github.io/Mobile-Seed/.
CoFiI2P: Coarse-to-Fine Correspondences for Image-to-Point Cloud Registration
Sep 26, 2023



Image-to-point cloud (I2P) registration is a fundamental task in the fields of robot navigation and mobile mapping. Existing I2P registration works estimate correspondences at the point-to-pixel level, neglecting the global alignment. However, I2P matching without high-level guidance from global constraints may converge to the local optimum easily. To solve the problem, this paper proposes CoFiI2P, a novel I2P registration network that extracts correspondences in a coarse-to-fine manner for the global optimal solution. First, the image and point cloud are fed into a Siamese encoder-decoder network for hierarchical feature extraction. Then, a coarse-to-fine matching module is designed to exploit features and establish resilient feature correspondences. Specifically, in the coarse matching block, a novel I2P transformer module is employed to capture the homogeneous and heterogeneous global information from image and point cloud. With the discriminate descriptors, coarse super-point-to-super-pixel matching pairs are estimated. In the fine matching module, point-to-pixel pairs are established with the super-point-to-super-pixel correspondence supervision. Finally, based on matching pairs, the transform matrix is estimated with the EPnP-RANSAC algorithm. Extensive experiments conducted on the KITTI dataset have demonstrated that CoFiI2P achieves a relative rotation error (RRE) of 2.25 degrees and a relative translation error (RTE) of 0.61 meters. These results represent a significant improvement of 14% in RRE and 52% in RTE compared to the current state-of-the-art (SOTA) method. The demo video for the experiments is available at https://youtu.be/TG2GBrJTuW4. The source code will be public at https://github.com/kang-1-2-3/CoFiI2P.