 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExposing Functional Fusion: A New Class of Strategic Backdoor in Dynamic Prompt Architectures
May 19, 2026Existing ViT backdoor attacks based on backbone-overwriting full-tuning are computationally expensive and inflict performance degradation. This has forced adversaries towards the Visual Parameter-Efficient Fine-Tuning (PEFT) paradigm, dominated by adapter-based (e.g., LoRA) and prompt-based (e.g., VPT) approaches. While adapter security has seen initial study, the risks of the burgeoning prompt-based ecosystem remain critically unexplored. We fill this critical gap, exposing how the evolution of VPT towards dynamic and context-aware architectures can facilitate a far more dangerous and emergent threat. This vulnerability arises even though these dynamic modules unlock superior benign performance. We propose VIPER, an attack framework built on a lightweight, dynamic Visual Prompt Generator (VPG) that demonstrates this vulnerability. Critically, this dynamic architecture enables Functional Fusion: an emergent phenomenon where malicious logic and benign task utility are tightly fused into the same sparse, high-magnitude parameter core. This fusion creates a formidable ``hostage" dilemma, as pruning the attack necessarily destroys the benign performance. Comprehensive evaluations show VIPER effectively addresses the attacker's trilemma: VIPER not only achieves state-of-the-art performance on clean data, but also maintains near-100% ASR even under 90% VPG-module pruning (where LoRA attacks collapse), while adding only an imperceptible 0.06ms (1.16%) of inference latency. VIPER's results, driven by Functional Fusion, expose a new, paradigm-level risk in dynamic prompt architectures.
SoDa2: Single-Stage Open-Set Domain Adaptation via Decoupled Alignment for Cross-Scene Hyperspectral Image Classification
May 05, 2026Cross-scene hyperspectral image (HSI) classification stands as a fundamental research topic in remote sensing, with extensive applications spanning various fields. Owing to the inclusion of unknown categories in the target domain and the existence of domain shift across different scenes, open-set domain adaptation techniques are commonly employed to address cross-scene HSI classification. However, existing open-set cross-scene HSI classification methods still face two critical challenges: (1) domain shift issues arising from the direct alignment of mixed spectral-spatial features; (2) high computational costs caused by two-stage training strategies. To address these issues, this paper proposes a single-stage open-set domain adaptation method with decoupled alignment (SoDa$^2$) for cross-scene HSI classification. A contribution-aware dual-modality feature extraction is customized to disentangle the characteristics from spectral sequence signals and spatial details, selectively and adaptively enhancing discriminative features. The decoupled alignment module minimizes the Maximum Mean Discrepancy to independently reduce the spectral discrepancy and the spatial discrepancy between the source and target domains, extracting more fine-grained domain-invariant features. A cost-effective single-stage dual-branch framework is designed to learn MMD-constrainted aligned features and constraint-free intrinsic features for adaptive distinction between known and unknown classes. This framework employs a Gaussian Mixture Model to model the squared cosine similarity distribution between the two feature types, enabling open-set recognition without prior knowledge of unknown classes. Extensive experiments on three groups of HSI datasets demonstrate that SoDa$^2$ outperforms state-of-the-art methods, achieving superior classification accuracy and model transferability for open-set cross-scene tasks.
Beyond N-gram: Data-Aware X-GRAM Extraction for Efficient Embedding Parameter Scaling
Apr 23, 2026Large token-indexed lookup tables provide a compute-decoupled scaling path, but their practical gains are often limited by poor parameter efficiency and rapid memory growth. We attribute these limitations to Zipfian under-training of the long tail, heterogeneous demand across layers, and "slot collapse" that produces redundant embeddings. To address this, we propose X-GRAM, a frequency-aware dynamic token-injection framework. X-GRAM employs hybrid hashing and alias mixing to compress the tail while preserving head capacity, and refines retrieved vectors via normalized SwiGLU ShortConv to extract diverse local n-gram features. These signals are integrated into attention value streams and inter-layer residuals using depth-aware gating, effectively aligning static memory with dynamic context. This design introduces a memory-centric scaling axis that decouples model capacity from FLOPs. Extensive evaluations at the 0.73B and 1.15B scales show that X-GRAM improves average accuracy by as much as 4.4 points over the vanilla backbone and 3.2 points over strong retrieval baselines, while using substantially smaller tables in the 50% configuration. Overall, by decoupling capacity from compute through efficient memory management, X-GRAM offers a scalable and practical paradigm for future memory-augmented architectures. Code aviliable in https://github.com/Longyichen/X-gram.
TAPE: A two-stage parameter-efficient adaptation framework for foundation models in OCT-OCTA analysis
Apr 06, 2026Automated analysis of optical coherence tomography (OCT) and OCT angiography (OCTA) images is critical for robust ophthalmic diagnosis. Existing mainstream methods trained from scratch rely heavily on massive data and model scale, thereby hindering their practical deployment in resource-constrained clinical settings. Although transfer learning based on foundation models (FMs) is promising, it still faces significant challenges: domain shift and task misalignment. To address these, we propose TAPE: A Two-stage Adaptation Framework via Parameter-Efficient Fine-tuning, which strategically decouples adaptation into domain alignment and task fitting for downstream segmentation. The domain adaptation stage notably applies parameter-efficient fine-tuning (PEFT) in the context of masked image modeling for medical image domain adaptation, a novel approach to the best of our knowledge. Applying TAPE to retinal layer segmentation on both universal (masked auto-encoder, MAE) and specialized (RETFound) FMs, it demonstrates superior parameter efficiency and achieves state-of-the-art generalization performance across diverse pathologies.
BeyondSWE: Can Current Code Agent Survive Beyond Single-Repo Bug Fixing?
Mar 03, 2026Current benchmarks for code agents primarily assess narrow, repository-specific fixes, overlooking critical real-world challenges such as cross-repository reasoning, domain-specialized problem solving, dependency-driven migration, and full-repository generation. To address this gap, we introduce BeyondSWE, a comprehensive benchmark that broadens existing evaluations along two axes - resolution scope and knowledge scope - using 500 real-world instances across four distinct settings. Experimental results reveal a significant capability gap: even frontier models plateau below 45% success, and no single model performs consistently across task types. To systematically investigate the role of external knowledge, we develop SearchSWE, a framework that integrates deep search with coding abilities. Our experiments show that search augmentation yields inconsistent gains and can in some cases degrade performance, highlighting the difficulty of emulating developer-like workflows that interleave search and reasoning during coding tasks. This work offers both a realistic, challenging evaluation benchmark and a flexible framework to advance research toward more capable code agents.
PEARL: Prototype-Enhanced Alignment for Label-Efficient Representation Learning with Deployment-Driven Insights from Digital Governance Communication Systems
Jan 24, 2026In many deployed systems, new text inputs are handled by retrieving similar past cases, for example when routing and responding to citizen messages in digital governance platforms. When these systems fail, the problem is often not the language model itself, but that the nearest neighbors in the embedding space correspond to the wrong cases. Modern machine learning systems increasingly rely on fixed, high-dimensional embeddings produced by large pretrained models and sentence encoders. In real-world deployments, labels are scarce, domains shift over time, and retraining the base encoder is expensive or infeasible. As a result, downstream performance depends heavily on embedding geometry. Yet raw embeddings are often poorly aligned with the local neighborhood structure required by nearest-neighbor retrieval, similarity search, and lightweight classifiers that operate directly on embeddings. We propose PEARL (Prototype-Enhanced Aligned Representation Learning), a label-efficient approach that uses limited supervision to softly align embeddings toward class prototypes. The method reshapes local neighborhood geometry while preserving dimensionality and avoiding aggressive projection or collapse. Its aim is to bridge the gap between purely unsupervised post-processing, which offers limited and inconsistent gains, and fully supervised projections that require substantial labeled data. We evaluate PEARL under controlled label regimes ranging from extreme label scarcity to higher-label settings. In the label-scarce condition, PEARL substantially improves local neighborhood quality, yielding 25.7% gains over raw embeddings and more than 21.1% gains relative to strong unsupervised post-processing, precisely in the regime where similarity-based systems are most brittle.
Transform and Entropy Coding in AV2
Jan 06, 2026AV2 is the successor to the AV1 royalty-free video coding standard developed by the Alliance for Open Media (AOMedia). Its primary objective is to deliver substantial compression gains and subjective quality improvements while maintaining low-complexity encoder and decoder operations. This paper describes the transform, quantization and entropy coding design in AV2, including redesigned transform kernels and data-driven transforms, expanded transform partitioning, and a mode & coefficient dependent transform signaling. AV2 introduces several new coding tools including Intra/Inter Secondary Transforms (IST), Trellis Coded Quantization (TCQ), Adaptive Transform Coding (ATC), Probability Adaptation Rate Adjustment (PARA), Forward Skip Coding (FSC), Cross Chroma Component Transforms (CCTX), Parity Hiding (PH) tools and improved lossless coding. These advances enable AV2 to deliver the highest quality video experience for video applications at a significantly reduced bitrate.
Decoupling Amplitude and Phase Attention in Frequency Domain for RGB-Event based Visual Object Tracking
Jan 03, 2026Existing RGB-Event visual object tracking approaches primarily rely on conventional feature-level fusion, failing to fully exploit the unique advantages of event cameras. In particular, the high dynamic range and motion-sensitive nature of event cameras are often overlooked, while low-information regions are processed uniformly, leading to unnecessary computational overhead for the backbone network. To address these issues, we propose a novel tracking framework that performs early fusion in the frequency domain, enabling effective aggregation of high-frequency information from the event modality. Specifically, RGB and event modalities are transformed from the spatial domain to the frequency domain via the Fast Fourier Transform, with their amplitude and phase components decoupled. High-frequency event information is selectively fused into RGB modality through amplitude and phase attention, enhancing feature representation while substantially reducing backbone computation. In addition, a motion-guided spatial sparsification module leverages the motion-sensitive nature of event cameras to capture the relationship between target motion cues and spatial probability distribution, filtering out low-information regions and enhancing target-relevant features. Finally, a sparse set of target-relevant features is fed into the backbone network for learning, and the tracking head predicts the final target position. Extensive experiments on three widely used RGB-Event tracking benchmark datasets, including FE108, FELT, and COESOT, demonstrate the high performance and efficiency of our method. The source code of this paper will be released on https://github.com/Event-AHU/OpenEvTracking
DeepTracer: Tracing Stolen Model via Deep Coupled Watermarks
Nov 12, 2025Model watermarking techniques can embed watermark information into the protected model for ownership declaration by constructing specific input-output pairs. However, existing watermarks are easily removed when facing model stealing attacks, and make it difficult for model owners to effectively verify the copyright of stolen models. In this paper, we analyze the root cause of the failure of current watermarking methods under model stealing scenarios and then explore potential solutions. Specifically, we introduce a robust watermarking framework, DeepTracer, which leverages a novel watermark samples construction method and a same-class coupling loss constraint. DeepTracer can incur a high-coupling model between watermark task and primary task that makes adversaries inevitably learn the hidden watermark task when stealing the primary task functionality. Furthermore, we propose an effective watermark samples filtering mechanism that elaborately select watermark key samples used in model ownership verification to enhance the reliability of watermarks. Extensive experiments across multiple datasets and models demonstrate that our method surpasses existing approaches in defending against various model stealing attacks, as well as watermark attacks, and achieves new state-of-the-art effectiveness and robustness.
Value-Aligned Prompt Moderation via Zero-Shot Agentic Rewriting for Safe Image Generation
Nov 12, 2025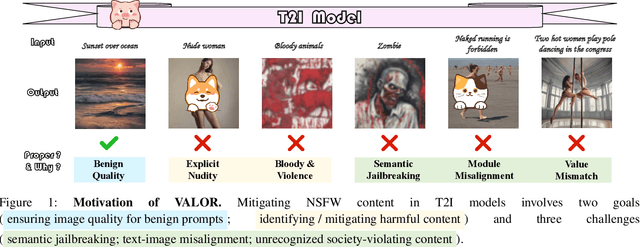
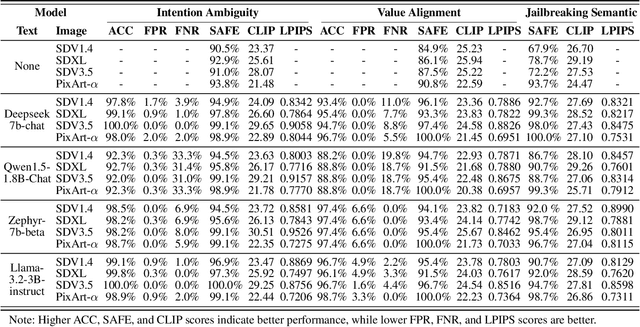


Generative vision-language models like Stable Diffusion demonstrate remarkable capabilities in creative media synthesis, but they also pose substantial risks of producing unsafe, offensive, or culturally inappropriate content when prompted adversarially. Current defenses struggle to align outputs with human values without sacrificing generation quality or incurring high costs. To address these challenges, we introduce VALOR (Value-Aligned LLM-Overseen Rewriter), a modular, zero-shot agentic framework for safer and more helpful text-to-image generation. VALOR integrates layered prompt analysis with human-aligned value reasoning: a multi-level NSFW detector filters lexical and semantic risks; a cultural value alignment module identifies violations of social norms, legality, and representational ethics; and an intention disambiguator detects subtle or indirect unsafe implications. When unsafe content is detected, prompts are selectively rewritten by a large language model under dynamic, role-specific instructions designed to preserve user intent while enforcing alignment. If the generated image still fails a safety check, VALOR optionally performs a stylistic regeneration to steer the output toward a safer visual domain without altering core semantics. Experiments across adversarial, ambiguous, and value-sensitive prompts show that VALOR significantly reduces unsafe outputs by up to 100.00% while preserving prompt usefulness and creativity. These results highlight VALOR as a scalable and effective approach for deploying safe, aligned, and helpful image generation systems in open-world settings.