 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMARS: Optimizing Dual-System Deep Research via Multi-Agent Reinforcement Learning
Oct 06, 2025Large Reasoning Models (LRMs) often exhibit a tendency for overanalysis in simple tasks, where the models excessively utilize System 2-type, deliberate reasoning, leading to inefficient token generation. Furthermore, these models face challenges in adapting their reasoning capabilities to rapidly changing environments due to the static nature of their pretraining data. To address these issues, advancing Large Language Models (LLMs) for complex reasoning tasks requires innovative approaches that bridge intuitive and deliberate cognitive processes, akin to human cognition's dual-system dynamic. This paper introduces a Multi-Agent System for Deep ReSearch (MARS) enabling seamless integration of System 1's fast, intuitive thinking with System 2's deliberate reasoning within LLMs. MARS strategically integrates multiple external tools, such as Google Search, Google Scholar, and Python Interpreter, to access up-to-date information and execute complex computations, while creating a specialized division of labor where System 1 efficiently processes and summarizes high-volume external information, providing distilled insights that expand System 2's reasoning context without overwhelming its capacity. Furthermore, we propose a multi-agent reinforcement learning framework extending Group Relative Policy Optimization to simultaneously optimize both systems with multi-turn tool interactions, bin-packing optimization, and sample balancing strategies that enhance collaborative efficiency. Extensive experiments demonstrate MARS achieves substantial improvements of 3.86% on the challenging Humanity's Last Exam (HLE) benchmark and an average gain of 8.9% across 7 knowledge-intensive tasks, validating the effectiveness of our dual-system paradigm for complex reasoning in dynamic information environments.
From Data-Centric to Sample-Centric: Enhancing LLM Reasoning via Progressive Optimization
Jul 09, 2025



Reinforcement learning with verifiable rewards (RLVR) has recently advanced the reasoning capabilities of large language models (LLMs). While prior work has emphasized algorithmic design, data curation, and reward shaping, we investigate RLVR from a sample-centric perspective and introduce LPPO (Learning-Progress and Prefix-guided Optimization), a framework of progressive optimization techniques. Our work addresses a critical question: how to best leverage a small set of trusted, high-quality demonstrations, rather than simply scaling up data volume. First, motivated by how hints aid human problem-solving, we propose prefix-guided sampling, an online data augmentation method that incorporates partial solution prefixes from expert demonstrations to guide the policy, particularly for challenging instances. Second, inspired by how humans focus on important questions aligned with their current capabilities, we introduce learning-progress weighting, a dynamic strategy that adjusts each training sample's influence based on model progression. We estimate sample-level learning progress via an exponential moving average of per-sample pass rates, promoting samples that foster learning and de-emphasizing stagnant ones. Experiments on mathematical-reasoning benchmarks demonstrate that our methods outperform strong baselines, yielding faster convergence and a higher performance ceiling.
Efficient and Adaptive Simultaneous Speech Translation with Fully Unidirectional Architecture
Apr 16, 2025



Simultaneous speech translation (SimulST) produces translations incrementally while processing partial speech input. Although large language models (LLMs) have showcased strong capabilities in offline translation tasks, applying them to SimulST poses notable challenges. Existing LLM-based SimulST approaches either incur significant computational overhead due to repeated encoding of bidirectional speech encoder, or they depend on a fixed read/write policy, limiting the efficiency and performance. In this work, we introduce Efficient and Adaptive Simultaneous Speech Translation (EASiST) with fully unidirectional architecture, including both speech encoder and LLM. EASiST includes a multi-latency data curation strategy to generate semantically aligned SimulST training samples and redefines SimulST as an interleaved generation task with explicit read/write tokens. To facilitate adaptive inference, we incorporate a lightweight policy head that dynamically predicts read/write actions. Additionally, we employ a multi-stage training strategy to align speech-text modalities and optimize both translation and policy behavior. Experiments on the MuST-C En$\rightarrow$De and En$\rightarrow$Es datasets demonstrate that EASiST offers superior latency-quality trade-offs compared to several strong baselines.
LLMs Can Achieve High-quality Simultaneous Machine Translation as Efficiently as Offline
Apr 13, 2025
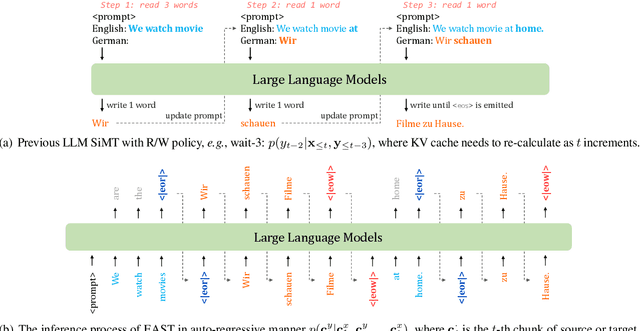
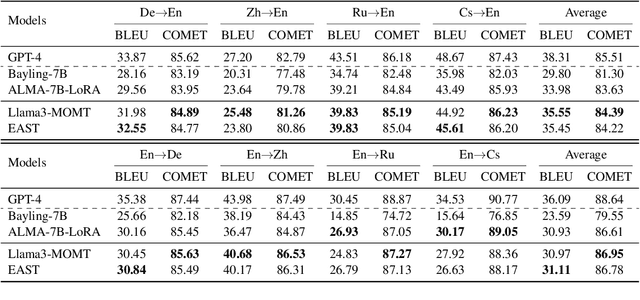
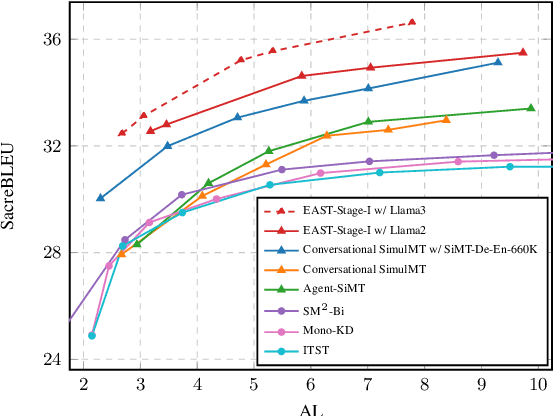
When the complete source sentence is provided, Large Language Models (LLMs) perform excellently in offline machine translation even with a simple prompt "Translate the following sentence from [src lang] into [tgt lang]:". However, in many real scenarios, the source tokens arrive in a streaming manner and simultaneous machine translation (SiMT) is required, then the efficiency and performance of decoder-only LLMs are significantly limited by their auto-regressive nature. To enable LLMs to achieve high-quality SiMT as efficiently as offline translation, we propose a novel paradigm that includes constructing supervised fine-tuning (SFT) data for SiMT, along with new training and inference strategies. To replicate the token input/output stream in SiMT, the source and target tokens are rearranged into an interleaved sequence, separated by special tokens according to varying latency requirements. This enables powerful LLMs to learn read and write operations adaptively, based on varying latency prompts, while still maintaining efficient auto-regressive decoding. Experimental results show that, even with limited SFT data, our approach achieves state-of-the-art performance across various SiMT benchmarks, and preserves the original abilities of offline translation. Moreover, our approach generalizes well to document-level SiMT setting without requiring specific fine-tuning, even beyond the offline translation model.
C-3PO: Compact Plug-and-Play Proxy Optimization to Achieve Human-like Retrieval-Augmented Generation
Feb 10, 2025



Retrieval-augmented generation (RAG) systems face a fundamental challenge in aligning independently developed retrievers and large language models (LLMs). Existing approaches typically involve modifying either component or introducing simple intermediate modules, resulting in practical limitations and sub-optimal performance. Inspired by human search behavior -- typically involving a back-and-forth process of proposing search queries and reviewing documents, we propose C-3PO, a proxy-centric framework that facilitates communication between retrievers and LLMs through a lightweight multi-agent system. Our framework implements three specialized agents that collaboratively optimize the entire RAG pipeline without altering the retriever and LLMs. These agents work together to assess the need for retrieval, generate effective queries, and select information suitable for the LLMs. To enable effective multi-agent coordination, we develop a tree-structured rollout approach for reward credit assignment in reinforcement learning. Extensive experiments in both in-domain and out-of-distribution scenarios demonstrate that C-3PO significantly enhances RAG performance while maintaining plug-and-play flexibility and superior generalization capabilities.
Markov Chain of Thought for Efficient Mathematical Reasoning
Oct 23, 2024



Chain of Thought (CoT) of multi-step benefits from the logical structure of the reasoning steps and task-specific actions, significantly enhancing the mathematical reasoning capabilities of large language models. As the prevalence of long CoT, the number of reasoning steps exceeds manageable token limits and leads to higher computational demands. Inspired by the fundamental logic of human cognition, ``derive, then reduce'', we conceptualize the standard multi-step CoT as a novel Markov Chain of Thought (MCoT). In this study, we consider the mathematical reasoning task, defining each reasoning step as text accompanied by a Python code snippet. To facilitate a longer reasoning path, self-correction is enabled through interactions with the code interpreter. Our MCoT aims to compress previous reasoning steps into a simplified question, enabling efficient next-step inference without relying on a lengthy KV cache. In our experiments, we curate the \texttt{MCoTInstruct} dataset, and the empirical results indicate that MCoT not only significantly enhances efficiency but also maintains comparable accuracy. While much remains to be explored, this work paves the way for exploring the long CoT reasoning abilities of LLMs.
AnyTrans: Translate AnyText in the Image with Large Scale Models
Jun 17, 2024This paper introduces AnyTrans, an all-encompassing framework for the task-Translate AnyText in the Image (TATI), which includes multilingual text translation and text fusion within images. Our framework leverages the strengths of large-scale models, such as Large Language Models (LLMs) and text-guided diffusion models, to incorporate contextual cues from both textual and visual elements during translation. The few-shot learning capability of LLMs allows for the translation of fragmented texts by considering the overall context. Meanwhile, the advanced inpainting and editing abilities of diffusion models make it possible to fuse translated text seamlessly into the original image while preserving its style and realism. Additionally, our framework can be constructed entirely using open-source models and requires no training, making it highly accessible and easily expandable. To encourage advancement in the TATI task, we have meticulously compiled a test dataset called MTIT6, which consists of multilingual text image translation data from six language pairs.
Step-level Value Preference Optimization for Mathematical Reasoning
Jun 16, 2024



Direct Preference Optimization (DPO) using an implicit reward model has proven to be an effective alternative to reinforcement learning from human feedback (RLHF) for fine-tuning preference aligned large language models (LLMs). However, the overall preference annotations of responses do not fully capture the fine-grained quality of model outputs in complex multi-step reasoning tasks, such as mathematical reasoning. To address this limitation, we introduce a novel algorithm called Step-level Value Preference Optimization (SVPO). Our approach employs Monte Carlo Tree Search (MCTS) to automatically annotate step-level preferences for multi-step reasoning. Furthermore, from the perspective of learning-to-rank, we train an explicit value model to replicate the behavior of the implicit reward model, complementing standard preference optimization. This value model enables the LLM to generate higher reward responses with minimal cost during inference. Experimental results demonstrate that our method achieves state-of-the-art performance on both in-domain and out-of-domain mathematical reasoning benchmarks.
Enhancing Security and Privacy in Federated Learning using Update Digests and Voting-Based Defense
May 29, 2024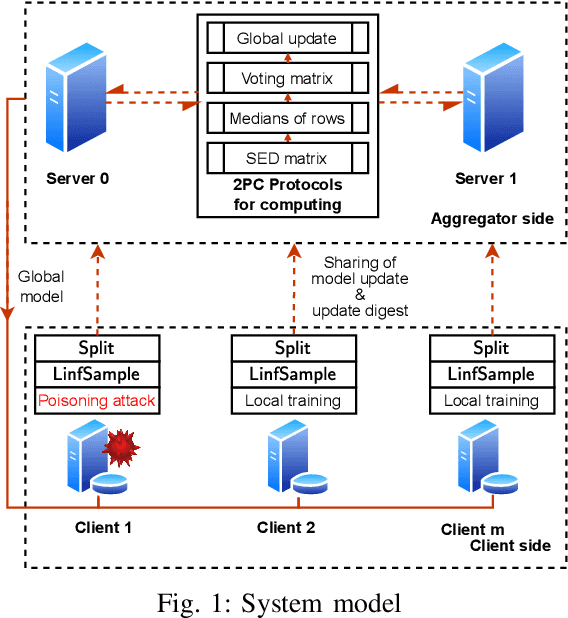
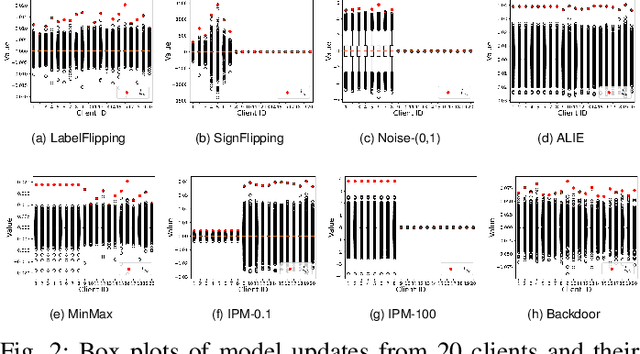
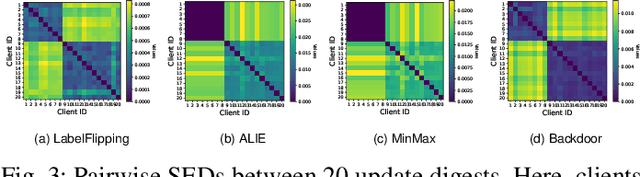
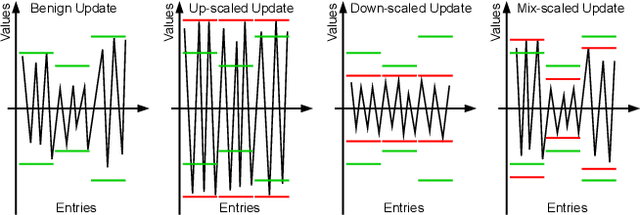
Federated Learning (FL) is a promising privacy-preserving machine learning paradigm that allows data owners to collaboratively train models while keeping their data localized. Despite its potential, FL faces challenges related to the trustworthiness of both clients and servers, especially in the presence of curious or malicious adversaries. In this paper, we introduce a novel framework named \underline{\textbf{F}}ederated \underline{\textbf{L}}earning with \underline{\textbf{U}}pdate \underline{\textbf{D}}igest (FLUD), which addresses the critical issues of privacy preservation and resistance to Byzantine attacks within distributed learning environments. FLUD utilizes an innovative approach, the $\mathsf{LinfSample}$ method, allowing clients to compute the $l_{\infty}$ norm across sliding windows of updates as an update digest. This digest enables the server to calculate a shared distance matrix, significantly reducing the overhead associated with Secure Multi-Party Computation (SMPC) by three orders of magnitude while effectively distinguishing between benign and malicious updates. Additionally, FLUD integrates a privacy-preserving, voting-based defense mechanism that employs optimized SMPC protocols to minimize communication rounds. Our comprehensive experiments demonstrate FLUD's effectiveness in countering Byzantine adversaries while incurring low communication and runtime overhead. FLUD offers a scalable framework for secure and reliable FL in distributed environments, facilitating its application in scenarios requiring robust data management and security.
AlphaMath Almost Zero: process Supervision without process
May 06, 2024



Recent advancements in large language models (LLMs) have substantially enhanced their mathematical reasoning abilities. However, these models still struggle with complex problems that require multiple reasoning steps, frequently leading to logical or numerical errors. While numerical mistakes can largely be addressed by integrating a code interpreter, identifying logical errors within intermediate steps is more challenging. Moreover, manually annotating these steps for training is not only expensive but also demands specialized expertise. In this study, we introduce an innovative approach that eliminates the need for manual annotation by leveraging the Monte Carlo Tree Search (MCTS) framework to generate both the process supervision and evaluation signals automatically. Essentially, when a LLM is well pre-trained, only the mathematical questions and their final answers are required to generate our training data, without requiring the solutions. We proceed to train a step-level value model designed to improve the LLM's inference process in mathematical domains. Our experiments indicate that using automatically generated solutions by LLMs enhanced with MCTS significantly improves the model's proficiency in dealing with intricate mathematical reasoning tasks.