 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXDomainBench: Diagnosing Reasoning Collapse in High-Dimensional Scientific Knowledge Composition
May 14, 2026Large Language Models (LLMs) are increasingly deployed for knowledge synthesis, yet their capacity for compositional generalization in scientific knowledge remains under-characterized. Existing benchmarks primarily focus on single-turn restricted scenarios, failing to capture the capability boundaries exposed by real-world interactive scientific workflows. To address this, we introduce XDomainBench, a diagnostic benchmark for interactive interdisciplinary scientific reasoning. We formalize the composition order and mixture structure to enable systematic stress-testing from single-discipline to inter-disciplinary, comprising 8,598 interactive sessions across 20 domains and 4 task categories, with 8 realistic trajectory patterns covering difficulty and domain-mixture dynamics, simulating real AI4S scenarios. Large-scale evaluation of LLMs reveals a systematic reasoning collapse as composition order increases, stemming from two root causes: (i) direct difficulty increases induced by domain composition, and (ii) indirect interaction-amplified failures where trajectory patterns trigger error accumulation, reasoning breaks, and domain confusion, ultimately leading to session collapse.
Certified Robustness under Heterogeneous Perturbations via Hybrid Randomized Smoothing
May 13, 2026Randomized smoothing provides strong, model-agnostic robustness certificates, but existing guarantees are limited to single modalities, treating continuous and discrete inputs in isolation. This limitation becomes critical in multimodal models, where decisions depend on cross-modal semantics and adversaries can jointly perturb heterogeneous inputs, rendering unimodal certificates insufficient. We introduce a unified randomized smoothing framework for mixed discrete--continuous inputs based on an analytically tractable Neyman--Pearson formulation of the joint worst-case problem. By analyzing the joint likelihood ordering induced by factorized discrete and continuous noise, our approach yields a closed-form, one-dimensional certificate that strictly generalizes both Gaussian (image-only) and discrete (text-only) randomized smoothing. We validate the framework on multimodal safety filtering, providing, to our knowledge, the first model-agnostic Neyman--Pearson certificate for joint discrete-token and continuous-image perturbations in interaction-dependent text--image safety filtering.
MPU: Towards Secure and Privacy-Preserving Knowledge Unlearning for Large Language Models
Feb 27, 2026Machine unlearning for large language models often faces a privacy dilemma in which strict constraints prohibit sharing either the server's parameters or the client's forget set. To address this dual non-disclosure constraint, we propose MPU, an algorithm-agnostic privacy-preserving Multiple Perturbed Copies Unlearning framework that primarily introduces two server-side modules: Pre-Process for randomized copy generation and Post-Process for update aggregation. In Pre-Process, the server distributes multiple perturbed and reparameterized model instances, allowing the client to execute unlearning locally on its private forget set without accessing the server's exact original parameters. After local unlearning, the server performs Post-Process by inverting the reparameterization and aggregating updates with a harmonic denoising procedure to alleviate the impact of perturbation. Experiments with seven unlearning algorithms show that MPU achieves comparable unlearning performance to noise-free baselines, with most algorithms' average degradation well below 1% under 10% noise, and can even outperform the noise-free baseline for some algorithms under 1% noise. Code is available at https://github.com/Tristan-SHU/MPU.
ICON: Indirect Prompt Injection Defense for Agents based on Inference-Time Correction
Feb 24, 2026Large Language Model (LLM) agents are susceptible to Indirect Prompt Injection (IPI) attacks, where malicious instructions in retrieved content hijack the agent's execution. Existing defenses typically rely on strict filtering or refusal mechanisms, which suffer from a critical limitation: over-refusal, prematurely terminating valid agentic workflows. We propose ICON, a probing-to-mitigation framework that neutralizes attacks while preserving task continuity. Our key insight is that IPI attacks leave distinct over-focusing signatures in the latent space. We introduce a Latent Space Trace Prober to detect attacks based on high intensity scores. Subsequently, a Mitigating Rectifier performs surgical attention steering that selectively manipulate adversarial query key dependencies while amplifying task relevant elements to restore the LLM's functional trajectory. Extensive evaluations on multiple backbones show that ICON achieves a competitive 0.4% ASR, matching commercial grade detectors, while yielding a over 50% task utility gain. Furthermore, ICON demonstrates robust Out of Distribution(OOD) generalization and extends effectively to multi-modal agents, establishing a superior balance between security and efficiency.
AdapTools: Adaptive Tool-based Indirect Prompt Injection Attacks on Agentic LLMs
Feb 24, 2026The integration of external data services (e.g., Model Context Protocol, MCP) has made large language model-based agents increasingly powerful for complex task execution. However, this advancement introduces critical security vulnerabilities, particularly indirect prompt injection (IPI) attacks. Existing attack methods are limited by their reliance on static patterns and evaluation on simple language models, failing to address the fast-evolving nature of modern AI agents. We introduce AdapTools, a novel adaptive IPI attack framework that selects stealthier attack tools and generates adaptive attack prompts to create a rigorous security evaluation environment. Our approach comprises two key components: (1) Adaptive Attack Strategy Construction, which develops transferable adversarial strategies for prompt optimization, and (2) Attack Enhancement, which identifies stealthy tools capable of circumventing task-relevance defenses. Comprehensive experimental evaluation shows that AdapTools achieves a 2.13 times improvement in attack success rate while degrading system utility by a factor of 1.78. Notably, the framework maintains its effectiveness even against state-of-the-art defense mechanisms. Our method advances the understanding of IPI attacks and provides a useful reference for future research.
M-Loss: Quantifying Model Merging Compatibility with Limited Unlabeled Data
Feb 09, 2026Training of large-scale models is both computationally intensive and often constrained by the availability of labeled data. Model merging offers a compelling alternative by directly integrating the weights of multiple source models without requiring additional data or extensive training. However, conventional model merging techniques, such as parameter averaging, often suffer from the unintended combination of non-generalizable features, especially when source models exhibit significant weight disparities. Comparatively, model ensembling generally provides more stable and superior performance that aggregates multiple models by averaging outputs. However, it incurs higher inference costs and increased storage requirements. While previous studies experimentally showed the similarities between model merging and ensembling, theoretical evidence and evaluation metrics remain lacking. To address this gap, we introduce Merging-ensembling loss (M-Loss), a novel evaluation metric that quantifies the compatibility of merging source models using very limited unlabeled data. By measuring the discrepancy between parameter averaging and model ensembling at layer and node levels, M-Loss facilitates more effective merging strategies. Specifically, M-Loss serves both as a quantitative criterion of the theoretical feasibility of model merging, and a guide for parameter significance in model pruning. Our theoretical analysis and empirical evaluations demonstrate that incorporating M-Loss into the merging process significantly improves the alignment between merged models and model ensembling, providing a scalable and efficient framework for accurate model consolidation.
Advancing ESG Intelligence: An Expert-level Agent and Comprehensive Benchmark for Sustainable Finance
Jan 13, 2026Environmental, social, and governance (ESG) criteria are essential for evaluating corporate sustainability and ethical performance. However, professional ESG analysis is hindered by data fragmentation across unstructured sources, and existing large language models (LLMs) often struggle with the complex, multi-step workflows required for rigorous auditing. To address these limitations, we introduce ESGAgent, a hierarchical multi-agent system empowered by a specialized toolset, including retrieval augmentation, web search and domain-specific functions, to generate in-depth ESG analysis. Complementing this agentic system, we present a comprehensive three-level benchmark derived from 310 corporate sustainability reports, designed to evaluate capabilities ranging from atomic common-sense questions to the generation of integrated, in-depth analysis. Empirical evaluations demonstrate that ESGAgent outperforms state-of-the-art closed-source LLMs with an average accuracy of 84.15% on atomic question-answering tasks, and excels in professional report generation by integrating rich charts and verifiable references. These findings confirm the diagnostic value of our benchmark, establishing it as a vital testbed for assessing general and advanced agentic capabilities in high-stakes vertical domains.
Disrupting Hierarchical Reasoning: Adversarial Protection for Geographic Privacy in Multimodal Reasoning Models
Dec 09, 2025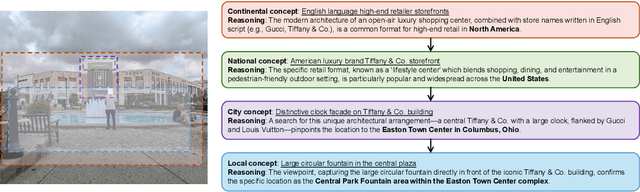
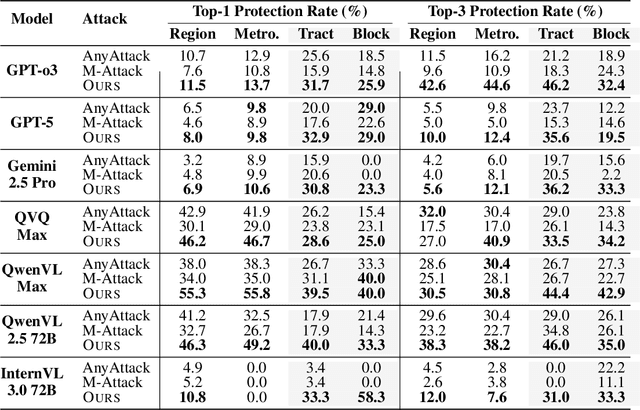
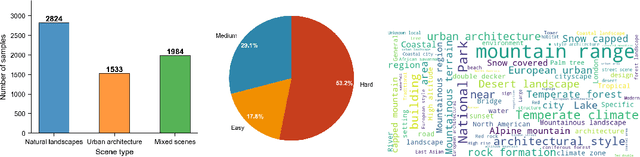
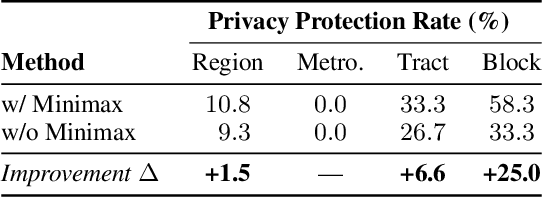
Multi-modal large reasoning models (MLRMs) pose significant privacy risks by inferring precise geographic locations from personal images through hierarchical chain-of-thought reasoning. Existing privacy protection techniques, primarily designed for perception-based models, prove ineffective against MLRMs' sophisticated multi-step reasoning processes that analyze environmental cues. We introduce \textbf{ReasonBreak}, a novel adversarial framework specifically designed to disrupt hierarchical reasoning in MLRMs through concept-aware perturbations. Our approach is founded on the key insight that effective disruption of geographic reasoning requires perturbations aligned with conceptual hierarchies rather than uniform noise. ReasonBreak strategically targets critical conceptual dependencies within reasoning chains, generating perturbations that invalidate specific inference steps and cascade through subsequent reasoning stages. To facilitate this approach, we contribute \textbf{GeoPrivacy-6K}, a comprehensive dataset comprising 6,341 ultra-high-resolution images ($\geq$2K) with hierarchical concept annotations. Extensive evaluation across seven state-of-the-art MLRMs (including GPT-o3, GPT-5, Gemini 2.5 Pro) demonstrates ReasonBreak's superior effectiveness, achieving a 14.4\% improvement in tract-level protection (33.8\% vs 19.4\%) and nearly doubling block-level protection (33.5\% vs 16.8\%). This work establishes a new paradigm for privacy protection against reasoning-based threats.
Oblivionis: A Lightweight Learning and Unlearning Framework for Federated Large Language Models
Aug 12, 2025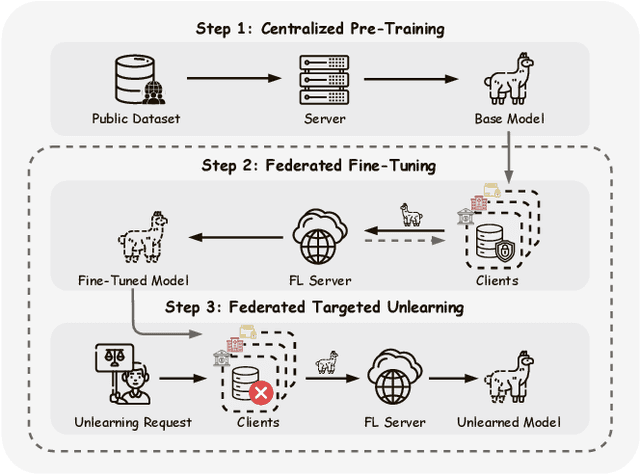
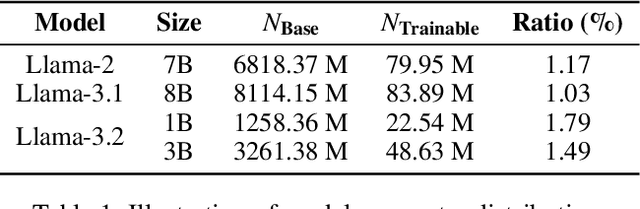
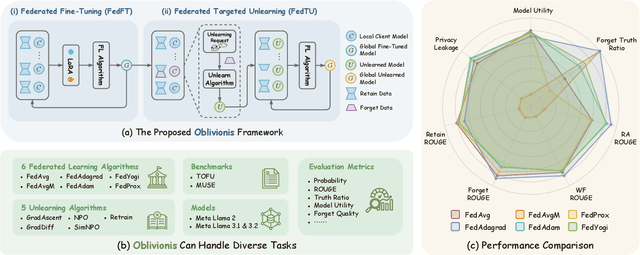
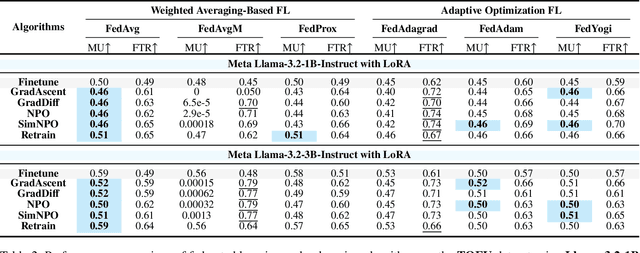
Large Language Models (LLMs) increasingly leverage Federated Learning (FL) to utilize private, task-specific datasets for fine-tuning while preserving data privacy. However, while federated LLM frameworks effectively enable collaborative training without raw data sharing, they critically lack built-in mechanisms for regulatory compliance like GDPR's right to be forgotten. Integrating private data heightens concerns over data quality and long-term governance, yet existing distributed training frameworks offer no principled way to selectively remove specific client contributions post-training. Due to distributed data silos, stringent privacy constraints, and the intricacies of interdependent model aggregation, federated LLM unlearning is significantly more complex than centralized LLM unlearning. To address this gap, we introduce Oblivionis, a lightweight learning and unlearning framework that enables clients to selectively remove specific private data during federated LLM training, enhancing trustworthiness and regulatory compliance. By unifying FL and unlearning as a dual optimization objective, we incorporate 6 FL and 5 unlearning algorithms for comprehensive evaluation and comparative analysis, establishing a robust pipeline for federated LLM unlearning. Extensive experiments demonstrate that Oblivionis outperforms local training, achieving a robust balance between forgetting efficacy and model utility, with cross-algorithm comparisons providing clear directions for future LLM development.
SacFL: Self-Adaptive Federated Continual Learning for Resource-Constrained End Devices
May 01, 2025



The proliferation of end devices has led to a distributed computing paradigm, wherein on-device machine learning models continuously process diverse data generated by these devices. The dynamic nature of this data, characterized by continuous changes or data drift, poses significant challenges for on-device models. To address this issue, continual learning (CL) is proposed, enabling machine learning models to incrementally update their knowledge and mitigate catastrophic forgetting. However, the traditional centralized approach to CL is unsuitable for end devices due to privacy and data volume concerns. In this context, federated continual learning (FCL) emerges as a promising solution, preserving user data locally while enhancing models through collaborative updates. Aiming at the challenges of limited storage resources for CL, poor autonomy in task shift detection, and difficulty in coping with new adversarial tasks in FCL scenario, we propose a novel FCL framework named SacFL. SacFL employs an Encoder-Decoder architecture to separate task-robust and task-sensitive components, significantly reducing storage demands by retaining lightweight task-sensitive components for resource-constrained end devices. Moreover, $\rm{SacFL}$ leverages contrastive learning to introduce an autonomous data shift detection mechanism, enabling it to discern whether a new task has emerged and whether it is a benign task. This capability ultimately allows the device to autonomously trigger CL or attack defense strategy without additional information, which is more practical for end devices. Comprehensive experiments conducted on multiple text and image datasets, such as Cifar100 and THUCNews, have validated the effectiveness of $\rm{SacFL}$ in both class-incremental and domain-incremental scenarios. Furthermore, a demo system has been developed to verify its practicality.