 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuided Trajectory Optimization with Sparse Scaling for Test-Time Diffusion
May 21, 2026The efficient Test-Time Scaling (TTS) paradigm offers a promising perspective for enhancing the generation performance of diffusion models. However, current solutions are limited to a static, pre-defined noise pool and suffer from inflexible noise exploration across the denoising trajectory. To bridge this gap, we propose RTS, a novel Reward-guided Trajectory Scaling method to fully unlock the generative potential of diffusion models. Unlike existing methods, RTS facilitates the synthesis of refined, high-fidelity images via two core innovations: 1) a reward-guided noise optimization strategy to actively direct the search towards promising regions; and 2) a sparse test-time scaling framework together with a PCA-driven curvature analysis scheme to prioritize key intermediate steps in the entire denoising space, effectively compressing the search space. Experiments show our approach outperforms baselines by 15.6% across GenEval Score, and a 60.4% enhancement in ImageReward score, setting a new SOTA while providing a practical guideline for more effective test-time scaling across diffusion-specific architectures.
ZOTTA: Test-Time Adaptation with Gradient-Free Zeroth-Order Optimization
Mar 15, 2026Test-time adaptation (TTA) aims to improve model robustness under distribution shifts by adapting to unlabeled test data, but most existing methods rely on backpropagation (BP), which is computationally costly and incompatible with non-differentiable models such as quantized models, limiting practical deployment on numerous edge devices. Recent BP-free approaches alleviate overhead but remain either architecture-specific or limited in optimization capacity to handle high-dimensional models. We propose ZOTTA, a fully BP-free TTA framework that performs efficient adaptation using only forward passes via Zeroth-Order Optimization (ZOO). While ZOO is theoretically appealing, naive application leads to slow convergence under high-dimensional parameter spaces and unstable optimization due to the lack of labels. ZOTTA overcomes these challenges through 1) Distribution-Robust Layer Selection, which automatically identifies and freezes layers that already extract distribution-invariant features, updating only domain-sensitive layers to reduce the optimization dimensionality and accelerate convergence; 2) Spatial Feature Aggregation Alignment, which stabilizes ZOO by aligning globally aggregated spatial features between source and target to reduce gradient variance. Together, these components enable architecture-agnostic and stable BP-free adaptation. Extensive experiments on ImageNet-C/R/Sketch/A show that ZOTTA outperforms or matches BP-based methods, e.g., it reduces memory usage by 84% and improves accuracy by 3.9% over SAR on ImageNet-C.
Adapt in the Wild: Test-Time Entropy Minimization with Sharpness and Feature Regularization
Sep 05, 2025Test-time adaptation (TTA) may fail to improve or even harm the model performance when test data have: 1) mixed distribution shifts, 2) small batch sizes, 3) online imbalanced label distribution shifts. This is often a key obstacle preventing existing TTA methods from being deployed in the real world. In this paper, we investigate the unstable reasons and find that the batch norm layer is a crucial factor hindering TTA stability. Conversely, TTA can perform more stably with batch-agnostic norm layers, i.e., group or layer norm. However, we observe that TTA with group and layer norms does not always succeed and still suffers many failure cases, i.e., the model collapses into trivial solutions by assigning the same class label for all samples. By digging into this, we find that, during the collapse process: 1) the model gradients often undergo an initial explosion followed by rapid degradation, suggesting that certain noisy test samples with large gradients may disrupt adaptation; and 2) the model representations tend to exhibit high correlations and classification bias. To address this, we first propose a sharpness-aware and reliable entropy minimization method, called SAR, for stabilizing TTA from two aspects: 1) remove partial noisy samples with large gradients, 2) encourage model weights to go to a flat minimum so that the model is robust to the remaining noisy samples. Based on SAR, we further introduce SAR^2 to prevent representation collapse with two regularizers: 1) a redundancy regularizer to reduce inter-dimensional correlations among centroid-invariant features; and 2) an inequity regularizer to maximize the prediction entropy of a prototype centroid, thereby penalizing biased representations toward any specific class. Promising results demonstrate that our methods perform more stably over prior methods and are computationally efficient under the above wild test scenarios.
Exploring Audio Cues for Enhanced Test-Time Video Model Adaptation
Jun 14, 2025Test-time adaptation (TTA) aims to boost the generalization capability of a trained model by conducting self-/unsupervised learning during the testing phase. While most existing TTA methods for video primarily utilize visual supervisory signals, they often overlook the potential contribution of inherent audio data. To address this gap, we propose a novel approach that incorporates audio information into video TTA. Our method capitalizes on the rich semantic content of audio to generate audio-assisted pseudo-labels, a new concept in the context of video TTA. Specifically, we propose an audio-to-video label mapping method by first employing pre-trained audio models to classify audio signals extracted from videos and then mapping the audio-based predictions to video label spaces through large language models, thereby establishing a connection between the audio categories and video labels. To effectively leverage the generated pseudo-labels, we present a flexible adaptation cycle that determines the optimal number of adaptation iterations for each sample, based on changes in loss and consistency across different views. This enables a customized adaptation process for each sample. Experimental results on two widely used datasets (UCF101-C and Kinetics-Sounds-C), as well as on two newly constructed audio-video TTA datasets (AVE-C and AVMIT-C) with various corruption types, demonstrate the superiority of our approach. Our method consistently improves adaptation performance across different video classification models and represents a significant step forward in integrating audio information into video TTA. Code: https://github.com/keikeiqi/Audio-Assisted-TTA.
Self-Bootstrapping for Versatile Test-Time Adaptation
Apr 10, 2025In this paper, we seek to develop a versatile test-time adaptation (TTA) objective for a variety of tasks - classification and regression across image-, object-, and pixel-level predictions. We achieve this through a self-bootstrapping scheme that optimizes prediction consistency between the test image (as target) and its deteriorated view. The key challenge lies in devising effective augmentations/deteriorations that: i) preserve the image's geometric information, e.g., object sizes and locations, which is crucial for TTA on object/pixel-level tasks, and ii) provide sufficient learning signals for TTA. To this end, we analyze how common distribution shifts affect the image's information power across spatial frequencies in the Fourier domain, and reveal that low-frequency components carry high power and masking these components supplies more learning signals, while masking high-frequency components can not. In light of this, we randomly mask the low-frequency amplitude of an image in its Fourier domain for augmentation. Meanwhile, we also augment the image with noise injection to compensate for missing learning signals at high frequencies, by enhancing the information power there. Experiments show that, either independently or as a plug-and-play module, our method achieves superior results across classification, segmentation, and 3D monocular detection tasks with both transformer and CNN models.
DriveGEN: Generalized and Robust 3D Detection in Driving via Controllable Text-to-Image Diffusion Generation
Mar 14, 2025



In autonomous driving, vision-centric 3D detection aims to identify 3D objects from images. However, high data collection costs and diverse real-world scenarios limit the scale of training data. Once distribution shifts occur between training and test data, existing methods often suffer from performance degradation, known as Out-of-Distribution (OOD) problems. To address this, controllable Text-to-Image (T2I) diffusion offers a potential solution for training data enhancement, which is required to generate diverse OOD scenarios with precise 3D object geometry. Nevertheless, existing controllable T2I approaches are restricted by the limited scale of training data or struggle to preserve all annotated 3D objects. In this paper, we present DriveGEN, a method designed to improve the robustness of 3D detectors in Driving via Training-Free Controllable Text-to-Image Diffusion Generation. Without extra diffusion model training, DriveGEN consistently preserves objects with precise 3D geometry across diverse OOD generations, consisting of 2 stages: 1) Self-Prototype Extraction: We empirically find that self-attention features are semantic-aware but require accurate region selection for 3D objects. Thus, we extract precise object features via layouts to capture 3D object geometry, termed self-prototypes. 2) Prototype-Guided Diffusion: To preserve objects across various OOD scenarios, we perform semantic-aware feature alignment and shallow feature alignment during denoising. Extensive experiments demonstrate the effectiveness of DriveGEN in improving 3D detection. The code is available at https://github.com/Hongbin98/DriveGEN.
Learning to Generate Gradients for Test-Time Adaptation via Test-Time Training Layers
Dec 22, 2024
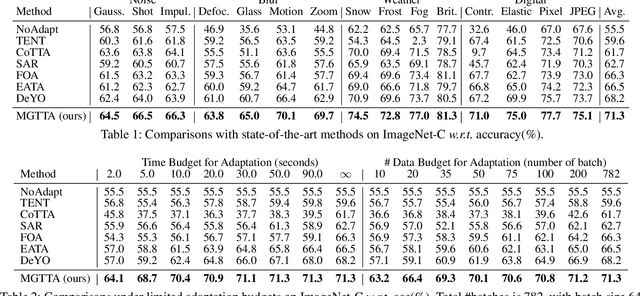
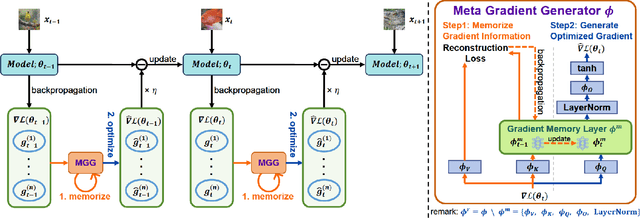
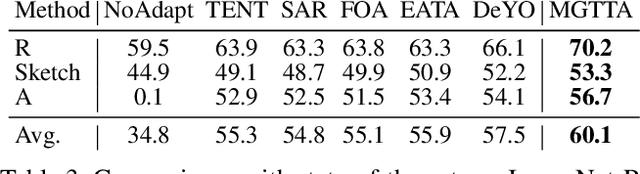
Test-time adaptation (TTA) aims to fine-tune a trained model online using unlabeled testing data to adapt to new environments or out-of-distribution data, demonstrating broad application potential in real-world scenarios. However, in this optimization process, unsupervised learning objectives like entropy minimization frequently encounter noisy learning signals. These signals produce unreliable gradients, which hinder the model ability to converge to an optimal solution quickly and introduce significant instability into the optimization process. In this paper, we seek to resolve these issues from the perspective of optimizer design. Unlike prior TTA using manually designed optimizers like SGD, we employ a learning-to-optimize approach to automatically learn an optimizer, called Meta Gradient Generator (MGG). Specifically, we aim for MGG to effectively utilize historical gradient information during the online optimization process to optimize the current model. To this end, in MGG, we design a lightweight and efficient sequence modeling layer -- gradient memory layer. It exploits a self-supervised reconstruction loss to compress historical gradient information into network parameters, thereby enabling better memorization ability over a long-term adaptation process. We only need a small number of unlabeled samples to pre-train MGG, and then the trained MGG can be deployed to process unseen samples. Promising results on ImageNet-C, R, Sketch, and A indicate that our method surpasses current state-of-the-art methods with fewer updates, less data, and significantly shorter adaptation iterations. Compared with a previous SOTA method SAR, we achieve 7.4% accuracy improvement and 4.2 times faster adaptation speed on ImageNet-C.
* 3 figures, 11 tables
Enhancing Federated Domain Adaptation with Multi-Domain Prototype-Based Federated Fine-Tuning
Oct 10, 2024
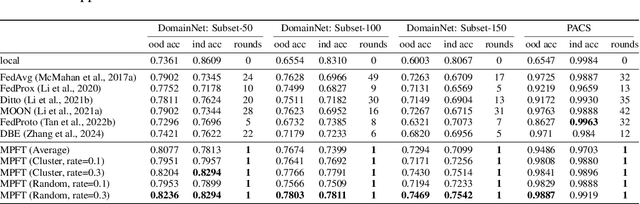

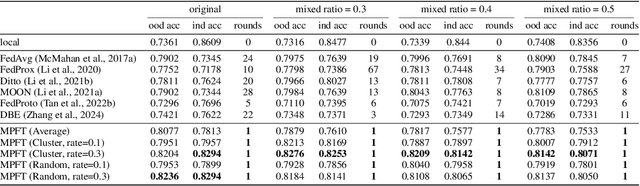
Federated Domain Adaptation (FDA) is a Federated Learning (FL) scenario where models are trained across multiple clients with unique data domains but a shared category space, without transmitting private data. The primary challenge in FDA is data heterogeneity, which causes significant divergences in gradient updates when using conventional averaging-based aggregation methods, reducing the efficacy of the global model. This further undermines both in-domain and out-of-domain performance (within the same federated system but outside the local client). To address this, we propose a novel framework called \textbf{M}ulti-domain \textbf{P}rototype-based \textbf{F}ederated Fine-\textbf{T}uning (MPFT). MPFT fine-tunes a pre-trained model using multi-domain prototypes, i.e., pretrained representations enriched with domain-specific information from category-specific local data. This enables supervised learning on the server to derive a globally optimized adapter that is subsequently distributed to local clients, without the intrusion of data privacy. Empirical results show that MPFT significantly improves both in-domain and out-of-domain accuracy over conventional methods, enhancing knowledge preservation and adaptation in FDA. Notably, MPFT achieves convergence within a single communication round, greatly reducing computation and communication costs. To ensure privacy, MPFT applies differential privacy to protect the prototypes. Additionally, we develop a prototype-based feature space hijacking attack to evaluate robustness, confirming that raw data samples remain unrecoverable even after extensive training epochs. The complete implementation of MPFL is available at \url{https://anonymous.4open.science/r/DomainFL/}.
Fully Test-Time Adaptation for Monocular 3D Object Detection
May 30, 2024Monocular 3D object detection (Mono 3Det) aims to identify 3D objects from a single RGB image. However, existing methods often assume training and test data follow the same distribution, which may not hold in real-world test scenarios. To address the out-of-distribution (OOD) problems, we explore a new adaptation paradigm for Mono 3Det, termed Fully Test-time Adaptation. It aims to adapt a well-trained model to unlabeled test data by handling potential data distribution shifts at test time without access to training data and test labels. However, applying this paradigm in Mono 3Det poses significant challenges due to OOD test data causing a remarkable decline in object detection scores. This decline conflicts with the pre-defined score thresholds of existing detection methods, leading to severe object omissions (i.e., rare positive detections and many false negatives). Consequently, the limited positive detection and plenty of noisy predictions cause test-time adaptation to fail in Mono 3Det. To handle this problem, we propose a novel Monocular Test-Time Adaptation (MonoTTA) method, based on two new strategies. 1) Reliability-driven adaptation: we empirically find that high-score objects are still reliable and the optimization of high-score objects can enhance confidence across all detections. Thus, we devise a self-adaptive strategy to identify reliable objects for model adaptation, which discovers potential objects and alleviates omissions. 2) Noise-guard adaptation: since high-score objects may be scarce, we develop a negative regularization term to exploit the numerous low-score objects via negative learning, preventing overfitting to noise and trivial solutions. Experimental results show that MonoTTA brings significant performance gains for Mono 3Det models in OOD test scenarios, approximately 190% gains by average on KITTI and 198% gains on nuScenes.
Test-Time Model Adaptation with Only Forward Passes
Apr 02, 2024



Test-time adaptation has proven effective in adapting a given trained model to unseen test samples with potential distribution shifts. However, in real-world scenarios, models are usually deployed on resource-limited devices, e.g., FPGAs, and are often quantized and hard-coded with non-modifiable parameters for acceleration. In light of this, existing methods are often infeasible since they heavily depend on computation-intensive backpropagation for model updating that may be not supported. To address this, we propose a test-time Forward-Only Adaptation (FOA) method. In FOA, we seek to solely learn a newly added prompt (as model's input) via a derivative-free covariance matrix adaptation evolution strategy. To make this strategy work stably under our online unsupervised setting, we devise a novel fitness function by measuring test-training statistic discrepancy and model prediction entropy. Moreover, we design an activation shifting scheme that directly tunes the model activations for shifted test samples, making them align with the source training domain, thereby further enhancing adaptation performance. Without using any backpropagation and altering model weights, FOA runs on quantized 8-bit ViT outperforms gradient-based TENT on full-precision 32-bit ViT, while achieving an up to 24-fold memory reduction on ImageNet-C. The source code will be released.