 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlashBlock: Attention Caching for Efficient Long-Context Block Diffusion
Feb 05, 2026Generating long-form content, such as minute-long videos and extended texts, is increasingly important for modern generative models. Block diffusion improves inference efficiency via KV caching and block-wise causal inference and has been widely adopted in diffusion language models and video generation. However, in long-context settings, block diffusion still incurs substantial overhead from repeatedly computing attention over a growing KV cache. We identify an underexplored property of block diffusion: cross-step redundancy of attention within a block. Our analysis shows that attention outputs from tokens outside the current block remain largely stable across diffusion steps, while block-internal attention varies significantly. Based on this observation, we propose FlashBlock, a cached block-external attention mechanism that reuses stable attention output, reducing attention computation and KV cache access without modifying the diffusion process. Moreover, FlashBlock is orthogonal to sparse attention and can be combined as a complementary residual reuse strategy, substantially improving model accuracy under aggressive sparsification. Experiments on diffusion language models and video generation demonstrate up to 1.44$\times$ higher token throughput and up to 1.6$\times$ reduction in attention time, with negligible impact on generation quality. Project page: https://caesarhhh.github.io/FlashBlock/.
Frequency-Aware Autoregressive Modeling for Efficient High-Resolution Image Synthesis
Jul 28, 2025



Visual autoregressive modeling, based on the next-scale prediction paradigm, exhibits notable advantages in image quality and model scalability over traditional autoregressive and diffusion models. It generates images by progressively refining resolution across multiple stages. However, the computational overhead in high-resolution stages remains a critical challenge due to the substantial number of tokens involved. In this paper, we introduce SparseVAR, a plug-and-play acceleration framework for next-scale prediction that dynamically excludes low-frequency tokens during inference without requiring additional training. Our approach is motivated by the observation that tokens in low-frequency regions have a negligible impact on image quality in high-resolution stages and exhibit strong similarity with neighboring tokens. Additionally, we observe that different blocks in the next-scale prediction model focus on distinct regions, with some concentrating on high-frequency areas. SparseVAR leverages these insights by employing lightweight MSE-based metrics to identify low-frequency tokens while preserving the fidelity of excluded regions through a small set of uniformly sampled anchor tokens. By significantly reducing the computational cost while maintaining high image generation quality, SparseVAR achieves notable acceleration in both HART and Infinity. Specifically, SparseVAR achieves up to a 2 times speedup with minimal quality degradation in Infinity-2B.
R-Stitch: Dynamic Trajectory Stitching for Efficient Reasoning
Jul 23, 2025Chain-of-thought (CoT) reasoning enhances the problem-solving capabilities of large language models by encouraging step-by-step intermediate reasoning during inference. While effective, CoT introduces substantial computational overhead due to its reliance on autoregressive decoding over long token sequences. Existing acceleration strategies either reduce sequence length through early stopping or compressive reward designs, or improve decoding speed via speculative decoding with smaller models. However, speculative decoding suffers from limited speedup when the agreement between small and large models is low, and fails to exploit the potential advantages of small models in producing concise intermediate reasoning. In this paper, we present R-Stitch, a token-level, confidence-based hybrid decoding framework that accelerates CoT inference by switching between a small language model (SLM) and a large language model (LLM) along the reasoning trajectory. R-Stitch uses the SLM to generate tokens by default and delegates to the LLM only when the SLM's confidence falls below a threshold. This design avoids full-sequence rollback and selectively invokes the LLM on uncertain steps, preserving both efficiency and answer quality. R-Stitch is model-agnostic, training-free, and compatible with standard decoding pipelines. Experiments on math reasoning benchmarks demonstrate that R-Stitch achieves up to 85\% reduction in inference latency with negligible accuracy drop, highlighting its practical effectiveness in accelerating CoT reasoning.
Enhancing Perception Capabilities of Multimodal LLMs with Training-free Fusion
Dec 02, 2024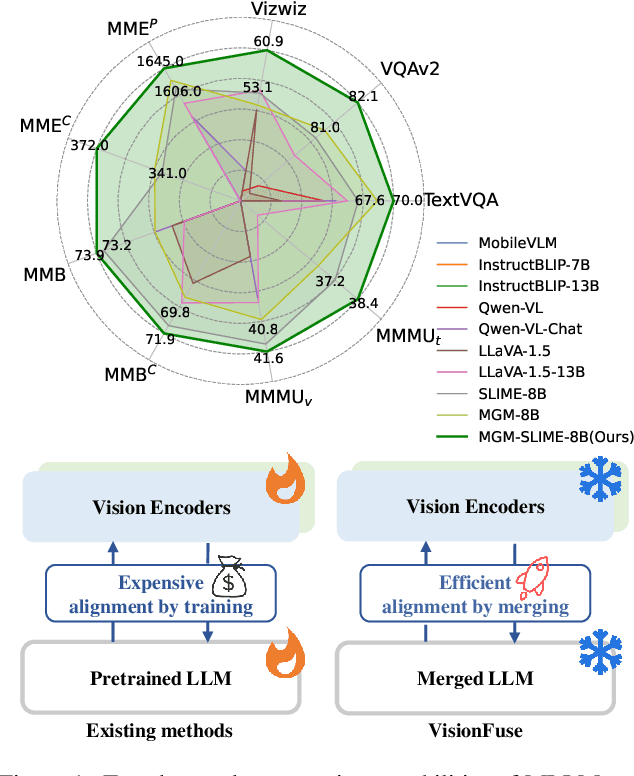
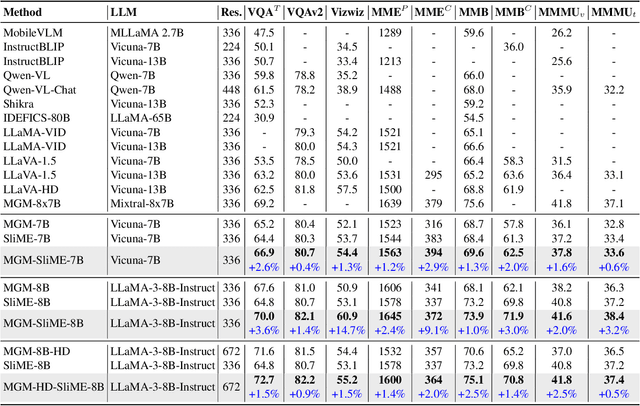


Multimodal LLMs (MLLMs) equip language models with visual capabilities by aligning vision encoders with language models. Existing methods to enhance the visual perception of MLLMs often involve designing more powerful vision encoders, which requires exploring a vast design space and re-aligning each potential encoder with the language model, resulting in prohibitively high training costs. In this paper, we introduce VisionFuse, a novel integration framework that efficiently utilizes multiple vision encoders from off-the-shelf MLLMs to enhance visual perception without requiring additional training. Our approach is motivated by the observation that different MLLMs tend to focus on distinct regions given the same query and image. Moreover, we find that the feature distributions of vision encoders within an MLLM family, a group of MLLMs sharing the same pretrained LLM, are highly aligned. Building on these insights, VisionFuse enriches the visual context by concatenating the tokens generated by the vision encoders of selected MLLMs within a family. By merging the parameters of language models from these MLLMs, VisionFuse allows a single language model to align with various vision encoders, significantly reducing deployment overhead. We conduct comprehensive evaluations across multiple multimodal benchmarks using various MLLM combinations, demonstrating substantial improvements in multimodal tasks. Notably, when integrating MiniGemini-8B and SLIME-8B, VisionFuse achieves an average performance increase of over 4%.
Efficient Test-Time Adaptation for Super-Resolution with Second-Order Degradation and Reconstruction
Oct 29, 2023



Image super-resolution (SR) aims to learn a mapping from low-resolution (LR) to high-resolution (HR) using paired HR-LR training images. Conventional SR methods typically gather the paired training data by synthesizing LR images from HR images using a predetermined degradation model, e.g., Bicubic down-sampling. However, the realistic degradation type of test images may mismatch with the training-time degradation type due to the dynamic changes of the real-world scenarios, resulting in inferior-quality SR images. To address this, existing methods attempt to estimate the degradation model and train an image-specific model, which, however, is quite time-consuming and impracticable to handle rapidly changing domain shifts. Moreover, these methods largely concentrate on the estimation of one degradation type (e.g., blur degradation), overlooking other degradation types like noise and JPEG in real-world test-time scenarios, thus limiting their practicality. To tackle these problems, we present an efficient test-time adaptation framework for SR, named SRTTA, which is able to quickly adapt SR models to test domains with different/unknown degradation types. Specifically, we design a second-order degradation scheme to construct paired data based on the degradation type of the test image, which is predicted by a pre-trained degradation classifier. Then, we adapt the SR model by implementing feature-level reconstruction learning from the initial test image to its second-order degraded counterparts, which helps the SR model generate plausible HR images. Extensive experiments are conducted on newly synthesized corrupted DIV2K datasets with 8 different degradations and several real-world datasets, demonstrating that our SRTTA framework achieves an impressive improvement over existing methods with satisfying speed. The source code is available at https://github.com/DengZeshuai/SRTTA.