 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Model Scaling: Test-Time Intervention for Efficient Deep Reasoning
Jan 16, 2026Large Reasoning Models (LRMs) excel at multi-step reasoning but often suffer from inefficient reasoning processes like overthinking and overshoot, where excessive or misdirected reasoning increases computational cost and degrades performance. Existing efficient reasoning methods operate in a closed-loop manner, lacking mechanisms for external intervention to guide the reasoning process. To address this, we propose Think-with-Me, a novel test-time interactive reasoning paradigm that introduces external feedback intervention into the reasoning process. Our key insights are that transitional conjunctions serve as natural points for intervention, signaling phases of self-validation or exploration and using transitional words appropriately to prolong the reasoning enhances performance, while excessive use affects performance. Building on these insights, Think-with-Me pauses reasoning at these points for external feedback, adaptively extending or terminating reasoning to reduce redundancy while preserving accuracy. The feedback is generated via a multi-criteria evaluation (rationality and completeness) and comes from either human or LLM proxies. We train the target model using Group Relative Policy Optimization (GRPO) to adapt to this interactive mode. Experiments show that Think-with-Me achieves a superior balance between accuracy and reasoning length under limited context windows. On AIME24, Think-with-Me outperforms QwQ-32B by 7.19% in accuracy while reducing average reasoning length by 81% under an 8K window. The paradigm also benefits security and creative tasks.
Beyond Fast and Slow: Cognitive-Inspired Elastic Reasoning for Large Language Models
Dec 17, 2025Large language models (LLMs) have demonstrated impressive performance across various language tasks. However, existing LLM reasoning strategies mainly rely on the LLM itself with fast or slow mode (like o1 thinking) and thus struggle to balance reasoning efficiency and accuracy across queries of varying difficulties. In this paper, we propose Cognitive-Inspired Elastic Reasoning (CogER), a framework inspired by human hierarchical reasoning that dynamically selects the most suitable reasoning strategy for each query. Specifically, CogER first assesses the complexity of incoming queries and assigns them to one of several predefined levels, each corresponding to a tailored processing strategy, thereby addressing the challenge of unobservable query difficulty. To achieve automatic strategy selection, we model the process as a Markov Decision Process and train a CogER-Agent using reinforcement learning. The agent is guided by a reward function that balances solution quality and computational cost, ensuring resource-efficient reasoning. Moreover, for queries requiring external tools, we introduce Cognitive Tool-Assisted Reasoning, which enables the LLM to autonomously invoke external tools within its chain-of-thought. Extensive experiments demonstrate that CogER outperforms state-of-the-art Test-Time scaling methods, achieving at least a 13% relative improvement in average exact match on In-Domain tasks and an 8% relative gain on Out-of-Domain tasks.
Continual Knowledge Adaptation for Reinforcement Learning
Oct 22, 2025Reinforcement Learning enables agents to learn optimal behaviors through interactions with environments. However, real-world environments are typically non-stationary, requiring agents to continuously adapt to new tasks and changing conditions. Although Continual Reinforcement Learning facilitates learning across multiple tasks, existing methods often suffer from catastrophic forgetting and inefficient knowledge utilization. To address these challenges, we propose Continual Knowledge Adaptation for Reinforcement Learning (CKA-RL), which enables the accumulation and effective utilization of historical knowledge. Specifically, we introduce a Continual Knowledge Adaptation strategy, which involves maintaining a task-specific knowledge vector pool and dynamically using historical knowledge to adapt the agent to new tasks. This process mitigates catastrophic forgetting and enables efficient knowledge transfer across tasks by preserving and adapting critical model parameters. Additionally, we propose an Adaptive Knowledge Merging mechanism that combines similar knowledge vectors to address scalability challenges, reducing memory requirements while ensuring the retention of essential knowledge. Experiments on three benchmarks demonstrate that the proposed CKA-RL outperforms state-of-the-art methods, achieving an improvement of 4.20% in overall performance and 8.02% in forward transfer. The source code is available at https://github.com/Fhujinwu/CKA-RL.
Test-Time Learning for Large Language Models
May 27, 2025
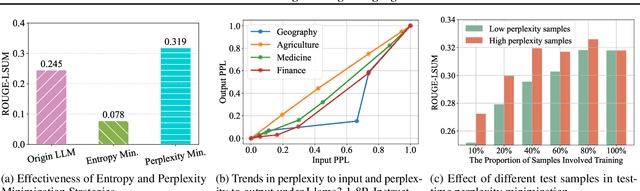
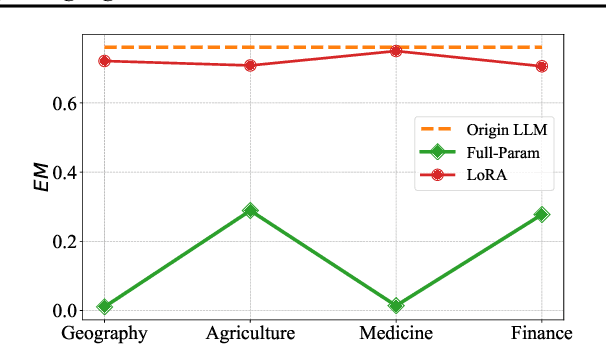
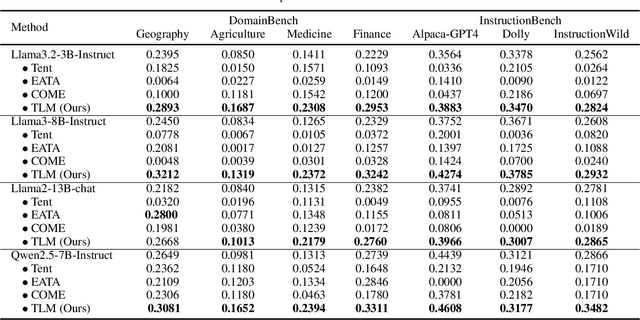
While Large Language Models (LLMs) have exhibited remarkable emergent capabilities through extensive pre-training, they still face critical limitations in generalizing to specialized domains and handling diverse linguistic variations, known as distribution shifts. In this paper, we propose a Test-Time Learning (TTL) paradigm for LLMs, namely TLM, which dynamically adapts LLMs to target domains using only unlabeled test data during testing. Specifically, we first provide empirical evidence and theoretical insights to reveal that more accurate predictions from LLMs can be achieved by minimizing the input perplexity of the unlabeled test data. Based on this insight, we formulate the Test-Time Learning process of LLMs as input perplexity minimization, enabling self-supervised enhancement of LLM performance. Furthermore, we observe that high-perplexity samples tend to be more informative for model optimization. Accordingly, we introduce a Sample Efficient Learning Strategy that actively selects and emphasizes these high-perplexity samples for test-time updates. Lastly, to mitigate catastrophic forgetting and ensure adaptation stability, we adopt Low-Rank Adaptation (LoRA) instead of full-parameter optimization, which allows lightweight model updates while preserving more original knowledge from the model. We introduce the AdaptEval benchmark for TTL and demonstrate through experiments that TLM improves performance by at least 20% compared to original LLMs on domain knowledge adaptation.
Enhancing User-Oriented Proactivity in Open-Domain Dialogues with Critic Guidance
May 18, 2025
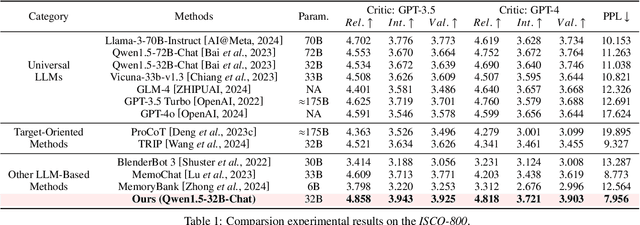
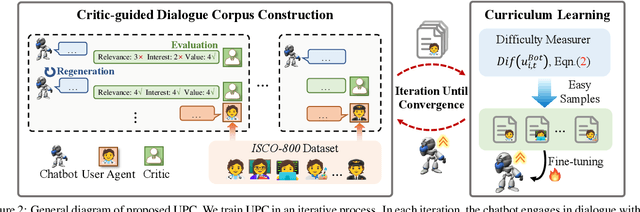

Open-domain dialogue systems aim to generate natural and engaging conversations, providing significant practical value in real applications such as social robotics and personal assistants. The advent of large language models (LLMs) has greatly advanced this field by improving context understanding and conversational fluency. However, existing LLM-based dialogue systems often fall short in proactively understanding the user's chatting preferences and guiding conversations toward user-centered topics. This lack of user-oriented proactivity can lead users to feel unappreciated, reducing their satisfaction and willingness to continue the conversation in human-computer interactions. To address this issue, we propose a User-oriented Proactive Chatbot (UPC) to enhance the user-oriented proactivity. Specifically, we first construct a critic to evaluate this proactivity inspired by the LLM-as-a-judge strategy. Given the scarcity of high-quality training data, we then employ the critic to guide dialogues between the chatbot and user agents, generating a corpus with enhanced user-oriented proactivity. To ensure the diversity of the user backgrounds, we introduce the ISCO-800, a diverse user background dataset for constructing user agents. Moreover, considering the communication difficulty varies among users, we propose an iterative curriculum learning method that trains the chatbot from easy-to-communicate users to more challenging ones, thereby gradually enhancing its performance. Experiments demonstrate that our proposed training method is applicable to different LLMs, improving user-oriented proactivity and attractiveness in open-domain dialogues.
Dynamic Compressing Prompts for Efficient Inference of Large Language Models
Apr 15, 2025Large Language Models (LLMs) have shown outstanding performance across a variety of tasks, partly due to advanced prompting techniques. However, these techniques often require lengthy prompts, which increase computational costs and can hinder performance because of the limited context windows of LLMs. While prompt compression is a straightforward solution, existing methods confront the challenges of retaining essential information, adapting to context changes, and remaining effective across different tasks. To tackle these issues, we propose a task-agnostic method called Dynamic Compressing Prompts (LLM-DCP). Our method reduces the number of prompt tokens while aiming to preserve the performance as much as possible. We model prompt compression as a Markov Decision Process (MDP), enabling the DCP-Agent to sequentially remove redundant tokens by adapting to dynamic contexts and retaining crucial content. We develop a reward function for training the DCP-Agent that balances the compression rate, the quality of the LLM output, and the retention of key information. This allows for prompt token reduction without needing an external black-box LLM. Inspired by the progressive difficulty adjustment in curriculum learning, we introduce a Hierarchical Prompt Compression (HPC) training strategy that gradually increases the compression difficulty, enabling the DCP-Agent to learn an effective compression method that maintains information integrity. Experiments demonstrate that our method outperforms state-of-the-art techniques, especially at higher compression rates. The code for our approach will be available at https://github.com/Fhujinwu/DCP.
Harnessing Frequency Spectrum Insights for Image Copyright Protection Against Diffusion Models
Mar 17, 2025Diffusion models have achieved remarkable success in novel view synthesis, but their reliance on large, diverse, and often untraceable Web datasets has raised pressing concerns about image copyright protection. Current methods fall short in reliably identifying unauthorized image use, as they struggle to generalize across varied generation tasks and fail when the training dataset includes images from multiple sources with few identifiable (watermarked or poisoned) samples. In this paper, we present novel evidence that diffusion-generated images faithfully preserve the statistical properties of their training data, particularly reflected in their spectral features. Leveraging this insight, we introduce \emph{CoprGuard}, a robust frequency domain watermarking framework to safeguard against unauthorized image usage in diffusion model training and fine-tuning. CoprGuard demonstrates remarkable effectiveness against a wide range of models, from naive diffusion models to sophisticated text-to-image models, and is robust even when watermarked images comprise a mere 1\% of the training dataset. This robust and versatile approach empowers content owners to protect their intellectual property in the era of AI-driven image generation.
Generating Long-form Story Using Dynamic Hierarchical Outlining with Memory-Enhancement
Dec 18, 2024Long-form story generation task aims to produce coherent and sufficiently lengthy text, essential for applications such as novel writingand interactive storytelling. However, existing methods, including LLMs, rely on rigid outlines or lack macro-level planning, making it difficult to achieve both contextual consistency and coherent plot development in long-form story generation. To address this issues, we propose Dynamic Hierarchical Outlining with Memory-Enhancement long-form story generation method, named DOME, to generate the long-form story with coherent content and plot. Specifically, the Dynamic Hierarchical Outline(DHO) mechanism incorporates the novel writing theory into outline planning and fuses the plan and writing stages together, improving the coherence of the plot by ensuring the plot completeness and adapting to the uncertainty during story generation. A Memory-Enhancement Module (MEM) based on temporal knowledge graphs is introduced to store and access the generated content, reducing contextual conflicts and improving story coherence. Finally, we propose a Temporal Conflict Analyzer leveraging temporal knowledge graphs to automatically evaluate the contextual consistency of long-form story. Experiments demonstrate that DOME significantly improves the fluency, coherence, and overall quality of generated long stories compared to state-of-the-art methods.
Dynamic Ensemble Reasoning for LLM Experts
Dec 10, 2024



Ensemble reasoning for the strengths of different LLM experts is critical to achieving consistent and satisfactory performance on diverse inputs across a wide range of tasks. However, existing LLM ensemble methods are either computationally intensive or incapable of leveraging complementary knowledge among LLM experts for various inputs. In this paper, we propose a Dynamic Ensemble Reasoning paradigm, called DER to integrate the strengths of multiple LLM experts conditioned on dynamic inputs. Specifically, we model the LLM ensemble reasoning problem as a Markov Decision Process (MDP), wherein an agent sequentially takes inputs to request knowledge from an LLM candidate and passes the output to a subsequent LLM candidate. Moreover, we devise a reward function to train a DER-Agent to dynamically select an optimal answering route given the input questions, aiming to achieve the highest performance with as few computational resources as possible. Last, to fully transfer the expert knowledge from the prior LLMs, we develop a Knowledge Transfer Prompt (KTP) that enables the subsequent LLM candidates to transfer complementary knowledge effectively. Experiments demonstrate that our method uses fewer computational resources to achieve better performance compared to state-of-the-art baselines.
Enhancing Perception Capabilities of Multimodal LLMs with Training-free Fusion
Dec 02, 2024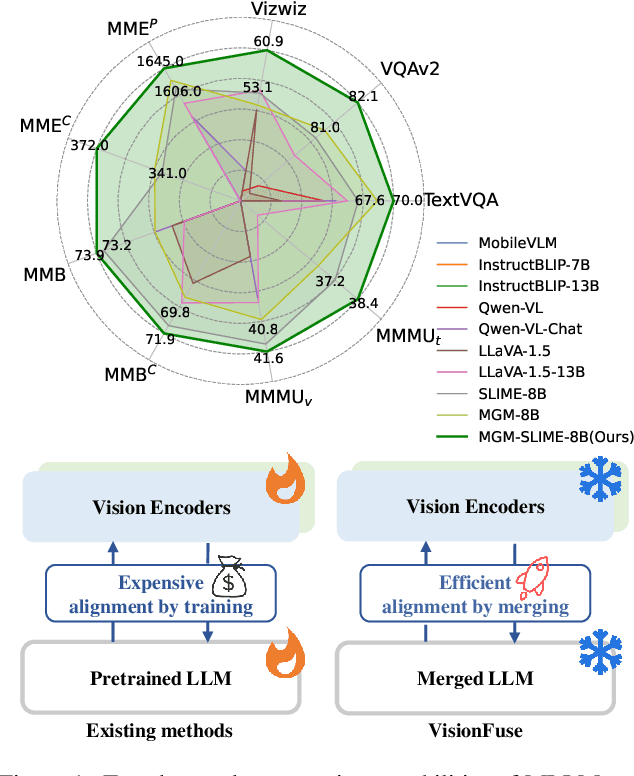
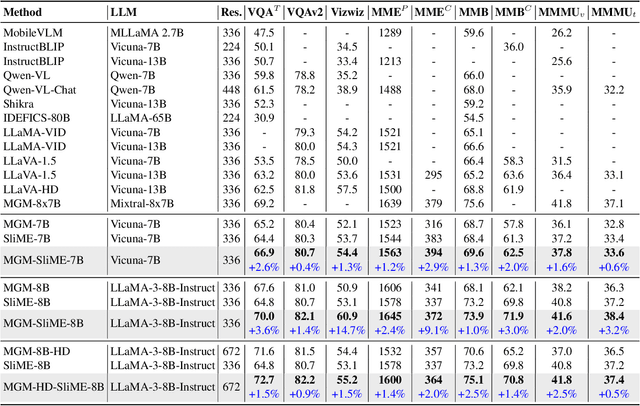


Multimodal LLMs (MLLMs) equip language models with visual capabilities by aligning vision encoders with language models. Existing methods to enhance the visual perception of MLLMs often involve designing more powerful vision encoders, which requires exploring a vast design space and re-aligning each potential encoder with the language model, resulting in prohibitively high training costs. In this paper, we introduce VisionFuse, a novel integration framework that efficiently utilizes multiple vision encoders from off-the-shelf MLLMs to enhance visual perception without requiring additional training. Our approach is motivated by the observation that different MLLMs tend to focus on distinct regions given the same query and image. Moreover, we find that the feature distributions of vision encoders within an MLLM family, a group of MLLMs sharing the same pretrained LLM, are highly aligned. Building on these insights, VisionFuse enriches the visual context by concatenating the tokens generated by the vision encoders of selected MLLMs within a family. By merging the parameters of language models from these MLLMs, VisionFuse allows a single language model to align with various vision encoders, significantly reducing deployment overhead. We conduct comprehensive evaluations across multiple multimodal benchmarks using various MLLM combinations, demonstrating substantial improvements in multimodal tasks. Notably, when integrating MiniGemini-8B and SLIME-8B, VisionFuse achieves an average performance increase of over 4%.