 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Perception Capabilities of Multimodal LLMs with Training-free Fusion
Paper and Code
Dec 02, 2024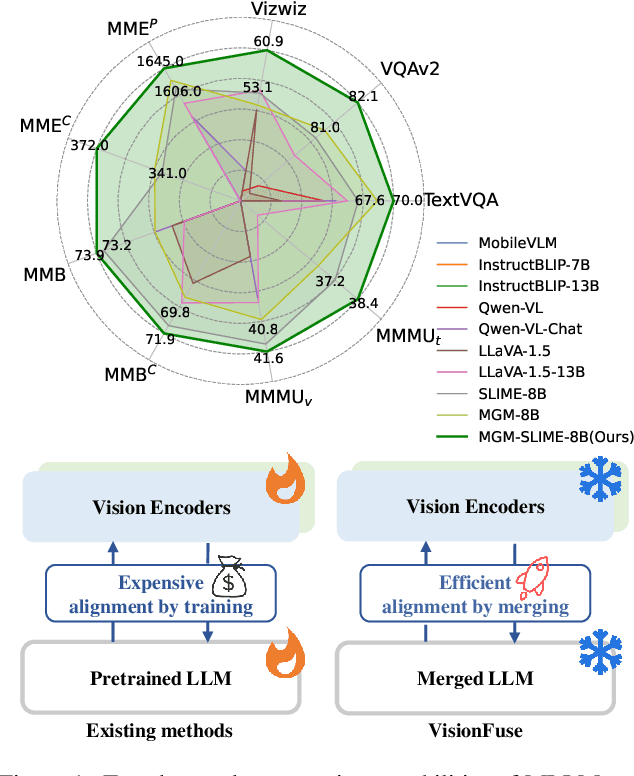
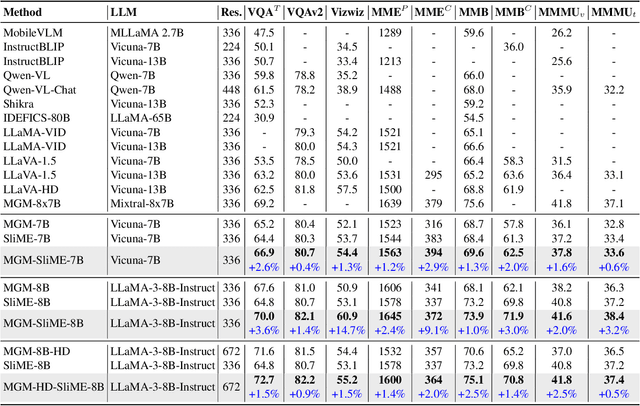


Multimodal LLMs (MLLMs) equip language models with visual capabilities by aligning vision encoders with language models. Existing methods to enhance the visual perception of MLLMs often involve designing more powerful vision encoders, which requires exploring a vast design space and re-aligning each potential encoder with the language model, resulting in prohibitively high training costs. In this paper, we introduce VisionFuse, a novel integration framework that efficiently utilizes multiple vision encoders from off-the-shelf MLLMs to enhance visual perception without requiring additional training. Our approach is motivated by the observation that different MLLMs tend to focus on distinct regions given the same query and image. Moreover, we find that the feature distributions of vision encoders within an MLLM family, a group of MLLMs sharing the same pretrained LLM, are highly aligned. Building on these insights, VisionFuse enriches the visual context by concatenating the tokens generated by the vision encoders of selected MLLMs within a family. By merging the parameters of language models from these MLLMs, VisionFuse allows a single language model to align with various vision encoders, significantly reducing deployment overhead. We conduct comprehensive evaluations across multiple multimodal benchmarks using various MLLM combinations, demonstrating substantial improvements in multimodal tasks. Notably, when integrating MiniGemini-8B and SLIME-8B, VisionFuse achieves an average performance increase of over 4%.