 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtoDCS: Towards Robust and Efficient Open-Set Test-Time Adaptation for Vision-Language Models
Feb 27, 2026Large-scale Vision-Language Models (VLMs) exhibit strong zero-shot recognition, yet their real-world deployment is challenged by distribution shifts. While Test-Time Adaptation (TTA) can mitigate this, existing VLM-based TTA methods operate under a closed-set assumption, failing in open-set scenarios where test streams contain both covariate-shifted in-distribution (csID) and out-of-distribution (csOOD) data. This leads to a critical difficulty: the model must discriminate unknown csOOD samples to avoid interference while simultaneously adapting to known csID classes for accuracy. Current open-set TTA (OSTTA) methods rely on hard thresholds for separation and entropy minimization for adaptation. These strategies are brittle, often misclassifying ambiguous csOOD samples and inducing overconfident predictions, and their parameter-update mechanism is computationally prohibitive for VLMs. To address these limitations, we propose Prototype-based Double-Check Separation (ProtoDCS), a robust framework for OSTTA that effectively separates csID and csOOD samples, enabling safe and efficient adaptation of VLMs to csID data. Our main contributions are: (1) a novel double-check separation mechanism employing probabilistic Gaussian Mixture Model (GMM) verification to replace brittle thresholding; and (2) an evidence-driven adaptation strategy utilizing uncertainty-aware loss and efficient prototype-level updates, mitigating overconfidence and reducing computational overhead. Extensive experiments on CIFAR-10/100-C and Tiny-ImageNet-C demonstrate that ProtoDCS achieves state-of-the-art performance, significantly boosting both known-class accuracy and OOD detection metrics. Code will be available at https://github.com/O-YangF/ProtoDCS.
Enhancing Perception Capabilities of Multimodal LLMs with Training-free Fusion
Dec 02, 2024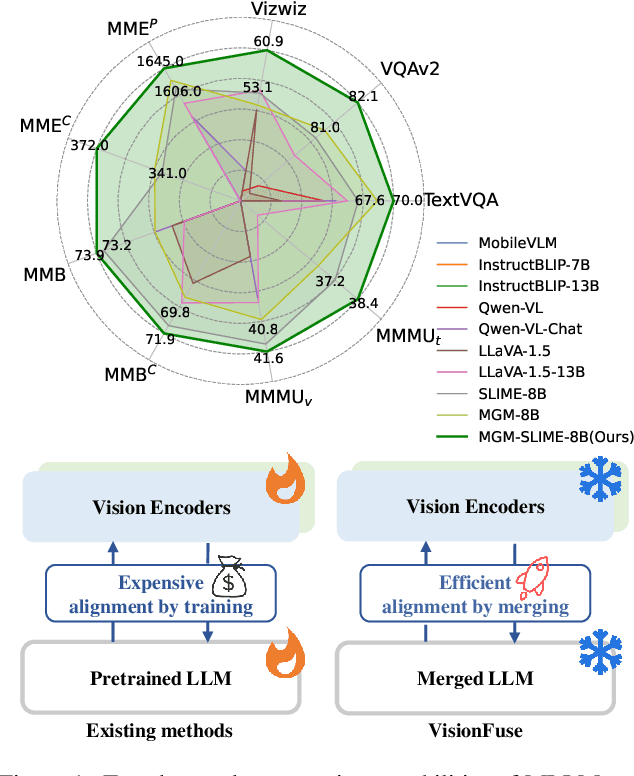
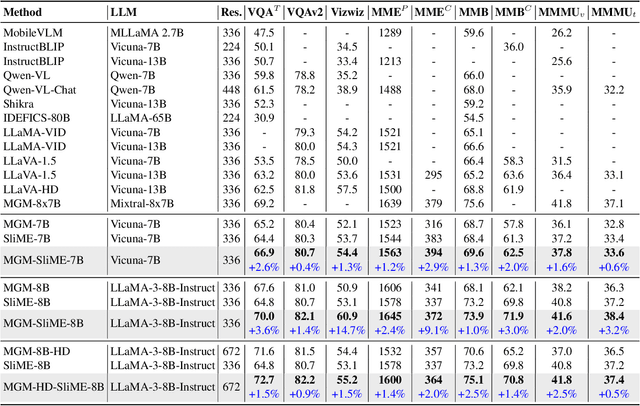


Multimodal LLMs (MLLMs) equip language models with visual capabilities by aligning vision encoders with language models. Existing methods to enhance the visual perception of MLLMs often involve designing more powerful vision encoders, which requires exploring a vast design space and re-aligning each potential encoder with the language model, resulting in prohibitively high training costs. In this paper, we introduce VisionFuse, a novel integration framework that efficiently utilizes multiple vision encoders from off-the-shelf MLLMs to enhance visual perception without requiring additional training. Our approach is motivated by the observation that different MLLMs tend to focus on distinct regions given the same query and image. Moreover, we find that the feature distributions of vision encoders within an MLLM family, a group of MLLMs sharing the same pretrained LLM, are highly aligned. Building on these insights, VisionFuse enriches the visual context by concatenating the tokens generated by the vision encoders of selected MLLMs within a family. By merging the parameters of language models from these MLLMs, VisionFuse allows a single language model to align with various vision encoders, significantly reducing deployment overhead. We conduct comprehensive evaluations across multiple multimodal benchmarks using various MLLM combinations, demonstrating substantial improvements in multimodal tasks. Notably, when integrating MiniGemini-8B and SLIME-8B, VisionFuse achieves an average performance increase of over 4%.
HiLo: Detailed and Robust 3D Clothed Human Reconstruction with High-and Low-Frequency Information of Parametric Models
Apr 07, 2024Reconstructing 3D clothed human involves creating a detailed geometry of individuals in clothing, with applications ranging from virtual try-on, movies, to games. To enable practical and widespread applications, recent advances propose to generate a clothed human from an RGB image. However, they struggle to reconstruct detailed and robust avatars simultaneously. We empirically find that the high-frequency (HF) and low-frequency (LF) information from a parametric model has the potential to enhance geometry details and improve robustness to noise, respectively. Based on this, we propose HiLo, namely clothed human reconstruction with high- and low-frequency information, which contains two components. 1) To recover detailed geometry using HF information, we propose a progressive HF Signed Distance Function to enhance the detailed 3D geometry of a clothed human. We analyze that our progressive learning manner alleviates large gradients that hinder model convergence. 2) To achieve robust reconstruction against inaccurate estimation of the parametric model by using LF information, we propose a spatial interaction implicit function. This function effectively exploits the complementary spatial information from a low-resolution voxel grid of the parametric model. Experimental results demonstrate that HiLo outperforms the state-of-the-art methods by 10.43% and 9.54% in terms of Chamfer distance on the Thuman2.0 and CAPE datasets, respectively. Additionally, HiLo demonstrates robustness to noise from the parametric model, challenging poses, and various clothing styles.
Efficient Test-Time Adaptation for Super-Resolution with Second-Order Degradation and Reconstruction
Oct 29, 2023



Image super-resolution (SR) aims to learn a mapping from low-resolution (LR) to high-resolution (HR) using paired HR-LR training images. Conventional SR methods typically gather the paired training data by synthesizing LR images from HR images using a predetermined degradation model, e.g., Bicubic down-sampling. However, the realistic degradation type of test images may mismatch with the training-time degradation type due to the dynamic changes of the real-world scenarios, resulting in inferior-quality SR images. To address this, existing methods attempt to estimate the degradation model and train an image-specific model, which, however, is quite time-consuming and impracticable to handle rapidly changing domain shifts. Moreover, these methods largely concentrate on the estimation of one degradation type (e.g., blur degradation), overlooking other degradation types like noise and JPEG in real-world test-time scenarios, thus limiting their practicality. To tackle these problems, we present an efficient test-time adaptation framework for SR, named SRTTA, which is able to quickly adapt SR models to test domains with different/unknown degradation types. Specifically, we design a second-order degradation scheme to construct paired data based on the degradation type of the test image, which is predicted by a pre-trained degradation classifier. Then, we adapt the SR model by implementing feature-level reconstruction learning from the initial test image to its second-order degraded counterparts, which helps the SR model generate plausible HR images. Extensive experiments are conducted on newly synthesized corrupted DIV2K datasets with 8 different degradations and several real-world datasets, demonstrating that our SRTTA framework achieves an impressive improvement over existing methods with satisfying speed. The source code is available at https://github.com/DengZeshuai/SRTTA.
Towards Lightweight Super-Resolution with Dual Regression Learning
Jul 21, 2022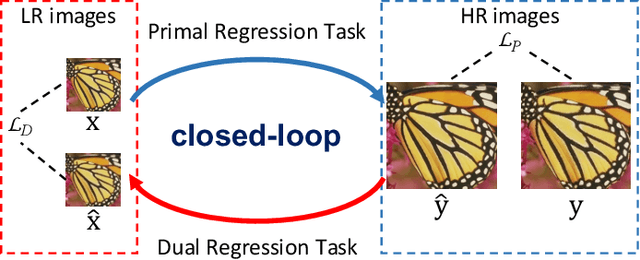
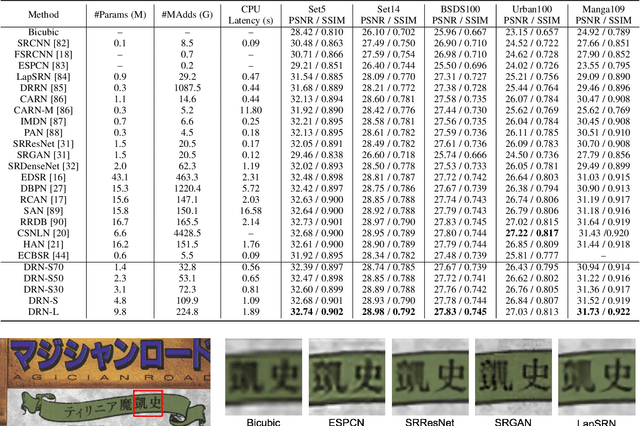
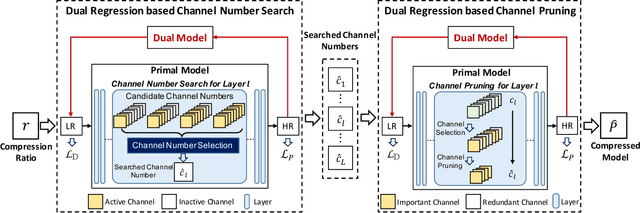
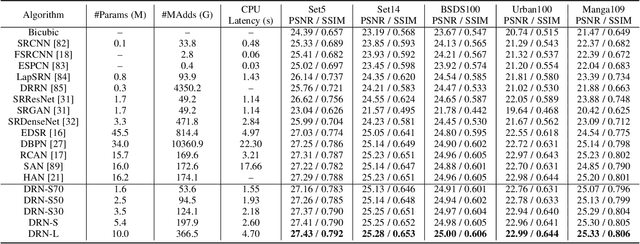
Deep neural networks have exhibited remarkable performance in image super-resolution (SR) tasks by learning a mapping from low-resolution (LR) images to high-resolution (HR) images. However, the SR problem is typically an ill-posed problem and existing methods would come with several limitations. First, the possible mapping space of SR can be extremely large since there may exist many different HR images that can be downsampled to the same LR image. As a result, it is hard to directly learn a promising SR mapping from such a large space. Second, it is often inevitable to develop very large models with extremely high computational cost to yield promising SR performance. In practice, one can use model compression techniques to obtain compact models by reducing model redundancy. Nevertheless, it is hard for existing model compression methods to accurately identify the redundant components due to the extremely large SR mapping space. To alleviate the first challenge, we propose a dual regression learning scheme to reduce the space of possible SR mappings. Specifically, in addition to the mapping from LR to HR images, we learn an additional dual regression mapping to estimate the downsampling kernel and reconstruct LR images. In this way, the dual mapping acts as a constraint to reduce the space of possible mappings. To address the second challenge, we propose a lightweight dual regression compression method to reduce model redundancy in both layer-level and channel-level based on channel pruning. Specifically, we first develop a channel number search method that minimizes the dual regression loss to determine the redundancy of each layer. Given the searched channel numbers, we further exploit the dual regression manner to evaluate the importance of channels and prune the redundant ones. Extensive experiments show the effectiveness of our method in obtaining accurate and efficient SR models.
Closed-loop Matters: Dual Regression Networks for Single Image Super-Resolution
Mar 16, 2020

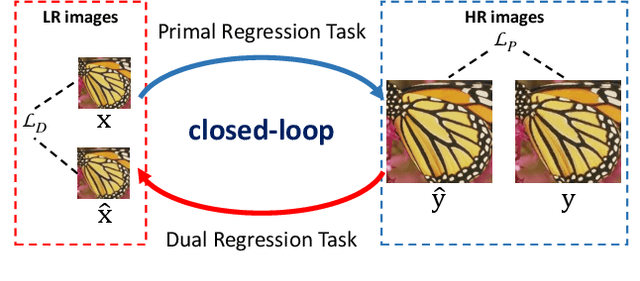
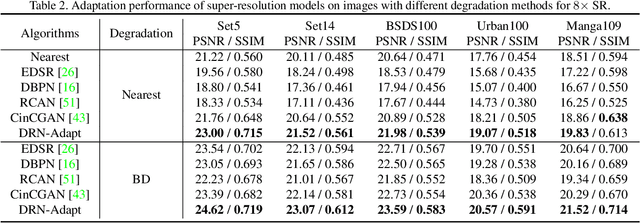
Deep neural networks have exhibited promising performance in image super-resolution (SR) by learning a nonlinear mapping function from low-resolution (LR) images to high-resolution (HR) images. However, there are two underlying limitations to existing SR methods. First, learning the mapping function from LR to HR images is typically an ill-posed problem, because there exist infinite HR images that can be downsampled to the same LR image. As a result, the space of the possible functions can be extremely large, which makes it hard to find a good solution. Second, the paired LR-HR data may be unavailable in real-world applications and the underlying degradation method is often unknown. For such a more general case, existing SR models often incur the adaptation problem and yield poor performance. To address the above issues, we propose a dual regression scheme by introducing an additional constraint on LR data to reduce the space of the possible functions. Specifically, besides the mapping from LR to HR images, we learn an additional dual regression mapping estimates the down-sampling kernel and reconstruct LR images, which forms a closed-loop to provide additional supervision. More critically, since the dual regression process does not depend on HR images, we can directly learn from LR images. In this sense, we can easily adapt SR models to real-world data, e.g., raw video frames from YouTube. Extensive experiments with paired training data and unpaired real-world data demonstrate our superiority over existing methods.