 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent-Condensed Transformer for Efficient Long Context Modeling
Apr 14, 2026Large language models (LLMs) face significant challenges in processing long contexts due to the linear growth of the key-value (KV) cache and quadratic complexity of self-attention. Existing approaches address these bottlenecks separately: Multi-head Latent Attention (MLA) reduces the KV cache by projecting tokens into a low-dimensional latent space, while sparse attention reduces computation. However, sparse methods cannot operate natively on MLA's compressed latent structure, missing opportunities for joint optimization. In this paper, we propose Latent-Condensed Attention (LCA), which directly condenses context within MLA's latent space, where the representation is disentangled into semantic latent vectors and positional keys. LCA separately aggregates semantic vectors via query-aware pooling and preserves positional keys via anchor selection. This approach jointly reduces both computational cost and KV cache without adding parameters. Beyond MLA, LCA's design is architecture-agnostic and readily extends to other attention mechanisms such as GQA. Theoretically, we prove a length-independent error bound. Experiments show LCA achieves up to 2.5$\times$ prefilling speedup and 90% KV cache reduction at 128K context while maintaining competitive performance.
Beyond Raw Detection Scores: Markov-Informed Calibration for Boosting Machine-Generated Text Detection
Feb 08, 2026While machine-generated texts (MGTs) offer great convenience, they also pose risks such as disinformation and phishing, highlighting the need for reliable detection. Metric-based methods, which extract statistically distinguishable features of MGTs, are often more practical than complex model-based methods that are prone to overfitting. Given their diverse designs, we first place representative metric-based methods within a unified framework, enabling a clear assessment of their advantages and limitations. Our analysis identifies a core challenge across these methods: the token-level detection score is easily biased by the inherent randomness of the MGTs generation process. To address this, we theoretically and empirically reveal two relationships of context detection scores that may aid calibration: Neighbor Similarity and Initial Instability. We then propose a Markov-informed score calibration strategy that models these relationships using Markov random fields, and implements it as a lightweight component via a mean-field approximation, allowing our method to be seamlessly integrated into existing detectors. Extensive experiments in various real-world scenarios, such as cross-LLM and paraphrasing attacks, demonstrate significant gains over baselines with negligible computational overhead. The code is available at https://github.com/tmlr-group/MRF_Calibration.
Training-free Context-adaptive Attention for Efficient Long Context Modeling
Dec 10, 2025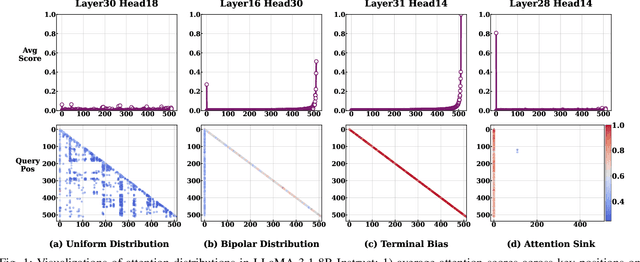
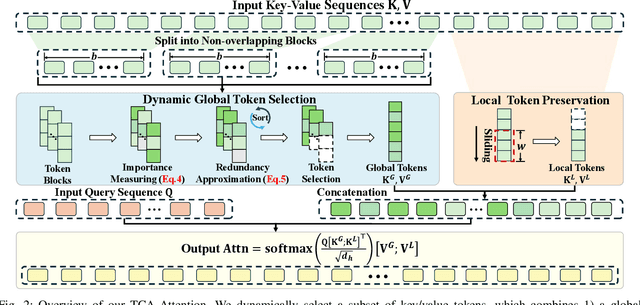
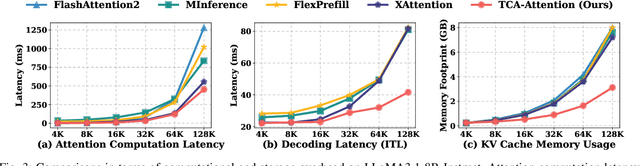
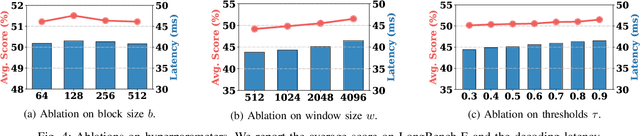
Large Language Models (LLMs) have demonstrated remarkable capabilities across a wide range of natural language processing tasks. These capabilities stem primarily from the self-attention mechanism, which enables modeling of long-range dependencies. However, the quadratic complexity of self-attention with respect to sequence length poses significant computational and memory challenges, especially as sequence length extends to extremes. While various sparse attention and KV cache compression methods have been proposed to improve efficiency, they often suffer from limitations such as reliance on fixed patterns, inability to handle both prefilling and decoding stages, or the requirement for additional training. In this paper, we propose Training-free Context-adaptive Attention (TCA-Attention), a training-free sparse attention mechanism that selectively attends to only the informative tokens for efficient long-context inference. Our method consists of two lightweight phases: i) an offline calibration phase that determines head-specific sparsity budgets via a single forward pass, and ii) an online token selection phase that adaptively retains core context tokens using a lightweight redundancy metric. TCA-Attention provides a unified solution that accelerates both prefilling and decoding while reducing KV cache memory footprint, without requiring parameter updates or architectural changes. Theoretical analysis shows that our approach maintains bounded approximation error. Extensive experiments demonstrate that TCA-Attention achieves a 2.8$\times$ speedup and reduces KV cache by 61% at 128K context length while maintaining performance comparable to full attention across various benchmarks, offering a practical plug-and-play solution for efficient long-context inference.
Physics-Driven Spatiotemporal Modeling for AI-Generated Video Detection
Oct 09, 2025



AI-generated videos have achieved near-perfect visual realism (e.g., Sora), urgently necessitating reliable detection mechanisms. However, detecting such videos faces significant challenges in modeling high-dimensional spatiotemporal dynamics and identifying subtle anomalies that violate physical laws. In this paper, we propose a physics-driven AI-generated video detection paradigm based on probability flow conservation principles. Specifically, we propose a statistic called Normalized Spatiotemporal Gradient (NSG), which quantifies the ratio of spatial probability gradients to temporal density changes, explicitly capturing deviations from natural video dynamics. Leveraging pre-trained diffusion models, we develop an NSG estimator through spatial gradients approximation and motion-aware temporal modeling without complex motion decomposition while preserving physical constraints. Building on this, we propose an NSG-based video detection method (NSG-VD) that computes the Maximum Mean Discrepancy (MMD) between NSG features of the test and real videos as a detection metric. Last, we derive an upper bound of NSG feature distances between real and generated videos, proving that generated videos exhibit amplified discrepancies due to distributional shifts. Extensive experiments confirm that NSG-VD outperforms state-of-the-art baselines by 16.00% in Recall and 10.75% in F1-Score, validating the superior performance of NSG-VD. The source code is available at https://github.com/ZSHsh98/NSG-VD.
Deep Electromagnetic Structure Design Under Limited Evaluation Budgets
Jun 24, 2025Electromagnetic structure (EMS) design plays a critical role in developing advanced antennas and materials, but remains challenging due to high-dimensional design spaces and expensive evaluations. While existing methods commonly employ high-quality predictors or generators to alleviate evaluations, they are often data-intensive and struggle with real-world scale and budget constraints. To address this, we propose a novel method called Progressive Quadtree-based Search (PQS). Rather than exhaustively exploring the high-dimensional space, PQS converts the conventional image-like layout into a quadtree-based hierarchical representation, enabling a progressive search from global patterns to local details. Furthermore, to lessen reliance on highly accurate predictors, we introduce a consistency-driven sample selection mechanism. This mechanism quantifies the reliability of predictions, balancing exploitation and exploration when selecting candidate designs. We evaluate PQS on two real-world engineering tasks, i.e., Dual-layer Frequency Selective Surface and High-gain Antenna. Experimental results show that our method can achieve satisfactory designs under limited computational budgets, outperforming baseline methods. In particular, compared to generative approaches, it cuts evaluation costs by 75-85%, effectively saving 20.27-38.80 days of product designing cycle.
Curse of High Dimensionality Issue in Transformer for Long-context Modeling
May 28, 2025Transformer-based large language models (LLMs) excel in natural language processing tasks by capturing long-range dependencies through self-attention mechanisms. However, long-context modeling faces significant computational inefficiencies due to \textit{redundant} attention computations: while attention weights are often \textit{sparse}, all tokens consume \textit{equal} computational resources. In this paper, we reformulate traditional probabilistic sequence modeling as a \textit{supervised learning task}, enabling the separation of relevant and irrelevant tokens and providing a clearer understanding of redundancy. Based on this reformulation, we theoretically analyze attention sparsity, revealing that only a few tokens significantly contribute to predictions. Building on this, we formulate attention optimization as a linear coding problem and propose a \textit{group coding strategy}, theoretically showing its ability to improve robustness against random noise and enhance learning efficiency. Motivated by this, we propose \textit{Dynamic Group Attention} (DGA), which leverages the group coding to explicitly reduce redundancy by aggregating less important tokens during attention computation. Empirical results show that our DGA significantly reduces computational costs while maintaining competitive performance.Code is available at https://github.com/bolixinyu/DynamicGroupAttention.
Core Context Aware Attention for Long Context Language Modeling
Dec 17, 2024



Transformer-based Large Language Models (LLMs) have exhibited remarkable success in various natural language processing tasks primarily attributed to self-attention mechanism, which requires a token to consider all preceding tokens as its context to compute the attention score. However, when the context length L becomes very large (e.g., 32K), more redundant context information will be included w.r.t. any tokens, making the self-attention suffer from two main limitations: 1) The computational and memory complexity scales quadratically w.r.t. L; 2) The presence of redundant context information may hamper the model to capture dependencies among crucial tokens, which may degrade the representation performance. In this paper, we propose a plug-and-play Core Context Aware (CCA) Attention for efficient long-range context modeling, which consists of two components: 1) Globality-pooling attention that divides input tokens into groups and then dynamically merges tokens within each group into one core token based on their significance; 2) Locality-preserved attention that incorporates neighboring tokens into the attention calculation. The two complementary attentions will then be fused to the final attention, maintaining comprehensive modeling ability as the full self-attention. In this way, the core context information w.r.t. a given token will be automatically focused and strengthened, while the context information in redundant groups will be diminished during the learning process. As a result, the computational and memory complexity will be significantly reduced. More importantly, the CCA-Attention can improve the long-context modeling ability by diminishing the redundant context information. Extensive experimental results demonstrate that our CCA-Attention significantly outperforms state-of-the-art models in terms of computational efficiency and long-context modeling ability.
Adversarial Purification by Consistency-aware Latent Space Optimization on Data Manifolds
Dec 11, 2024



Deep neural networks (DNNs) are vulnerable to adversarial samples crafted by adding imperceptible perturbations to clean data, potentially leading to incorrect and dangerous predictions. Adversarial purification has been an effective means to improve DNNs robustness by removing these perturbations before feeding the data into the model. However, it faces significant challenges in preserving key structural and semantic information of data, as the imperceptible nature of adversarial perturbations makes it hard to avoid over-correcting, which can destroy important information and degrade model performance. In this paper, we break away from traditional adversarial purification methods by focusing on the clean data manifold. To this end, we reveal that samples generated by a well-trained generative model are close to clean ones but far from adversarial ones. Leveraging this insight, we propose Consistency Model-based Adversarial Purification (CMAP), which optimizes vectors within the latent space of a pre-trained consistency model to generate samples for restoring clean data. Specifically, 1) we propose a \textit{Perceptual consistency restoration} mechanism by minimizing the discrepancy between generated samples and input samples in both pixel and perceptual spaces. 2) To maintain the optimized latent vectors within the valid data manifold, we introduce a \textit{Latent distribution consistency constraint} strategy to align generated samples with the clean data distribution. 3) We also apply a \textit{Latent vector consistency prediction} scheme via an ensemble approach to enhance prediction reliability. CMAP fundamentally addresses adversarial perturbations at their source, providing a robust purification. Extensive experiments on CIFAR-10 and ImageNet-100 show that our CMAP significantly enhances robustness against strong adversarial attacks while preserving high natural accuracy.
Dynamic Ensemble Reasoning for LLM Experts
Dec 10, 2024



Ensemble reasoning for the strengths of different LLM experts is critical to achieving consistent and satisfactory performance on diverse inputs across a wide range of tasks. However, existing LLM ensemble methods are either computationally intensive or incapable of leveraging complementary knowledge among LLM experts for various inputs. In this paper, we propose a Dynamic Ensemble Reasoning paradigm, called DER to integrate the strengths of multiple LLM experts conditioned on dynamic inputs. Specifically, we model the LLM ensemble reasoning problem as a Markov Decision Process (MDP), wherein an agent sequentially takes inputs to request knowledge from an LLM candidate and passes the output to a subsequent LLM candidate. Moreover, we devise a reward function to train a DER-Agent to dynamically select an optimal answering route given the input questions, aiming to achieve the highest performance with as few computational resources as possible. Last, to fully transfer the expert knowledge from the prior LLMs, we develop a Knowledge Transfer Prompt (KTP) that enables the subsequent LLM candidates to transfer complementary knowledge effectively. Experiments demonstrate that our method uses fewer computational resources to achieve better performance compared to state-of-the-art baselines.
HiLo: Detailed and Robust 3D Clothed Human Reconstruction with High-and Low-Frequency Information of Parametric Models
Apr 07, 2024Reconstructing 3D clothed human involves creating a detailed geometry of individuals in clothing, with applications ranging from virtual try-on, movies, to games. To enable practical and widespread applications, recent advances propose to generate a clothed human from an RGB image. However, they struggle to reconstruct detailed and robust avatars simultaneously. We empirically find that the high-frequency (HF) and low-frequency (LF) information from a parametric model has the potential to enhance geometry details and improve robustness to noise, respectively. Based on this, we propose HiLo, namely clothed human reconstruction with high- and low-frequency information, which contains two components. 1) To recover detailed geometry using HF information, we propose a progressive HF Signed Distance Function to enhance the detailed 3D geometry of a clothed human. We analyze that our progressive learning manner alleviates large gradients that hinder model convergence. 2) To achieve robust reconstruction against inaccurate estimation of the parametric model by using LF information, we propose a spatial interaction implicit function. This function effectively exploits the complementary spatial information from a low-resolution voxel grid of the parametric model. Experimental results demonstrate that HiLo outperforms the state-of-the-art methods by 10.43% and 9.54% in terms of Chamfer distance on the Thuman2.0 and CAPE datasets, respectively. Additionally, HiLo demonstrates robustness to noise from the parametric model, challenging poses, and various clothing styles.