 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Room 2.0: Seeing is Not Understanding for MLLMs
Nov 17, 2025Can multi-modal large language models (MLLMs) truly understand what they can see? Extending Searle's Chinese Room into the multi-modal domain, this paper proposes the Visual Room argument: MLLMs may describe every visual detail precisely yet fail to comprehend the underlying emotions and intentions, namely seeing is not understanding. Building on this, we introduce \textit{Visual Room} 2.0, a hierarchical benchmark for evaluating perception-cognition alignment of MLLMs. We model human perceptive and cognitive processes across three levels: low, middle, and high, covering 17 representative tasks. The perception component ranges from attribute recognition to scene understanding, while the cognition component extends from textual entailment to causal and social reasoning. The dataset contains 350 multi-modal samples, each with six progressive questions (2,100 in total) spanning perception to cognition. Evaluating 10 state-of-the-art (SoTA) MLLMs, we highlight three key findings: (1) MLLMs exhibit stronger perceptual competence than cognitive ability (8.0\%$\uparrow$); (2) cognition appears not causally dependent on perception-based reasoning; and (3) cognition scales with model size, but perception does not consistently improve with larger variants. This work operationalizes Seeing $\ne$ Understanding as a testable hypothesis, offering a new paradigm from perceptual processing to cognitive reasoning in MLLMs. Our dataset is available at https://huggingface.co/datasets/LHK2003/PCBench.
Guiding Quantitative MRI Reconstruction with Phase-wise Uncertainty
Feb 28, 2025



Quantitative magnetic resonance imaging (qMRI) requires multi-phase acqui-sition, often relying on reduced data sampling and reconstruction algorithms to accelerate scans, which inherently poses an ill-posed inverse problem. While many studies focus on measuring uncertainty during this process, few explore how to leverage it to enhance reconstruction performance. In this paper, we in-troduce PUQ, a novel approach that pioneers the use of uncertainty infor-mation for qMRI reconstruction. PUQ employs a two-stage reconstruction and parameter fitting framework, where phase-wise uncertainty is estimated during reconstruction and utilized in the fitting stage. This design allows uncertainty to reflect the reliability of different phases and guide information integration during parameter fitting. We evaluated PUQ on in vivo T1 and T2 mapping datasets from healthy subjects. Compared to existing qMRI reconstruction methods, PUQ achieved the state-of-the-art performance in parameter map-pings, demonstrating the effectiveness of uncertainty guidance. Our code is available at https://anonymous.4open.science/r/PUQ-75B2/.
From Informal to Formal -- Incorporating and Evaluating LLMs on Natural Language Requirements to Verifiable Formal Proofs
Jan 27, 2025The research in AI-based formal mathematical reasoning has shown an unstoppable growth trend. These studies have excelled in mathematical competitions like IMO, showing significant progress. However, these studies intertwined multiple skills simultaneously, i.e., problem-solving, reasoning, and writing formal specifications, making it hard to precisely identify the LLMs' strengths and weaknesses in each task. This paper focuses on formal verification, an immediate application scenario of formal reasoning, and decomposes it into six sub-tasks. We constructed 18k high-quality instruction-response pairs across five mainstream formal specification languages (Coq, Lean4, Dafny, ACSL, and TLA+) in six formal-verification-related tasks by distilling GPT-4o. They are split into a 14k+ fine-tuning dataset FM-alpaca and a 4k benchmark FM-Bench. We found that LLMs are good at writing proof segments when given either the code, or the detailed description of proof steps. Also, the fine-tuning brought about a nearly threefold improvement at most. Interestingly, we observed that fine-tuning with formal data also enhances mathematics, reasoning, and coding abilities. We hope our findings inspire further research. Fine-tuned models are released to facilitate subsequent studies
Core Context Aware Attention for Long Context Language Modeling
Dec 17, 2024



Transformer-based Large Language Models (LLMs) have exhibited remarkable success in various natural language processing tasks primarily attributed to self-attention mechanism, which requires a token to consider all preceding tokens as its context to compute the attention score. However, when the context length L becomes very large (e.g., 32K), more redundant context information will be included w.r.t. any tokens, making the self-attention suffer from two main limitations: 1) The computational and memory complexity scales quadratically w.r.t. L; 2) The presence of redundant context information may hamper the model to capture dependencies among crucial tokens, which may degrade the representation performance. In this paper, we propose a plug-and-play Core Context Aware (CCA) Attention for efficient long-range context modeling, which consists of two components: 1) Globality-pooling attention that divides input tokens into groups and then dynamically merges tokens within each group into one core token based on their significance; 2) Locality-preserved attention that incorporates neighboring tokens into the attention calculation. The two complementary attentions will then be fused to the final attention, maintaining comprehensive modeling ability as the full self-attention. In this way, the core context information w.r.t. a given token will be automatically focused and strengthened, while the context information in redundant groups will be diminished during the learning process. As a result, the computational and memory complexity will be significantly reduced. More importantly, the CCA-Attention can improve the long-context modeling ability by diminishing the redundant context information. Extensive experimental results demonstrate that our CCA-Attention significantly outperforms state-of-the-art models in terms of computational efficiency and long-context modeling ability.
M2DA: Multi-Modal Fusion Transformer Incorporating Driver Attention for Autonomous Driving
Mar 19, 2024End-to-end autonomous driving has witnessed remarkable progress. However, the extensive deployment of autonomous vehicles has yet to be realized, primarily due to 1) inefficient multi-modal environment perception: how to integrate data from multi-modal sensors more efficiently; 2) non-human-like scene understanding: how to effectively locate and predict critical risky agents in traffic scenarios like an experienced driver. To overcome these challenges, in this paper, we propose a Multi-Modal fusion transformer incorporating Driver Attention (M2DA) for autonomous driving. To better fuse multi-modal data and achieve higher alignment between different modalities, a novel Lidar-Vision-Attention-based Fusion (LVAFusion) module is proposed. By incorporating driver attention, we empower the human-like scene understanding ability to autonomous vehicles to identify crucial areas within complex scenarios precisely and ensure safety. We conduct experiments on the CARLA simulator and achieve state-of-the-art performance with less data in closed-loop benchmarks. Source codes are available at https://anonymous.4open.science/r/M2DA-4772.
Boost Test-Time Performance with Closed-Loop Inference
Mar 26, 2022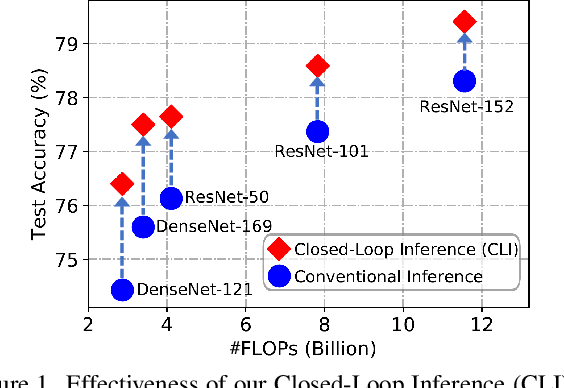
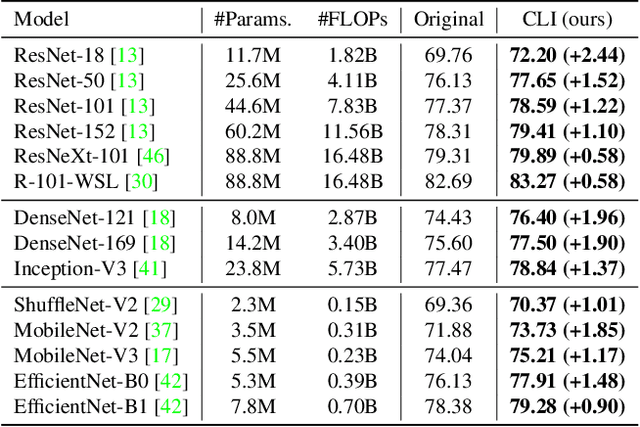
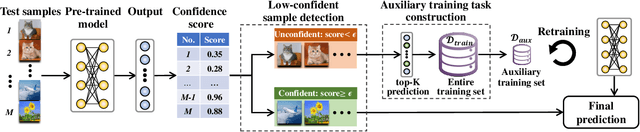
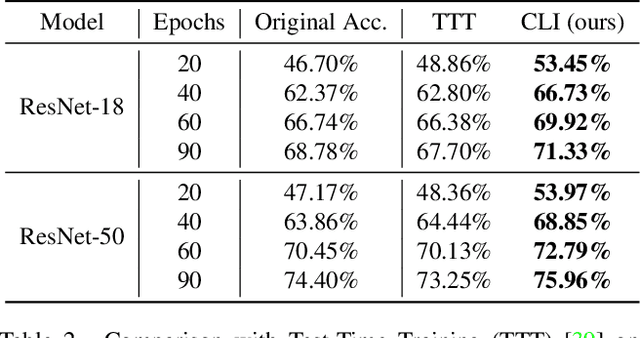
Conventional deep models predict a test sample with a single forward propagation, which, however, may not be sufficient for predicting hard-classified samples. On the contrary, we human beings may need to carefully check the sample many times before making a final decision. During the recheck process, one may refine/adjust the prediction by referring to related samples. Motivated by this, we propose to predict those hard-classified test samples in a looped manner to boost the model performance. However, this idea may pose a critical challenge: how to construct looped inference, so that the original erroneous predictions on these hard test samples can be corrected with little additional effort. To address this, we propose a general Closed-Loop Inference (CLI) method. Specifically, we first devise a filtering criterion to identify those hard-classified test samples that need additional inference loops. For each hard sample, we construct an additional auxiliary learning task based on its original top-$K$ predictions to calibrate the model, and then use the calibrated model to obtain the final prediction. Promising results on ImageNet (in-distribution test samples) and ImageNet-C (out-of-distribution test samples) demonstrate the effectiveness of CLI in improving the performance of any pre-trained model.
Generative Low-bitwidth Data Free Quantization
Mar 07, 2020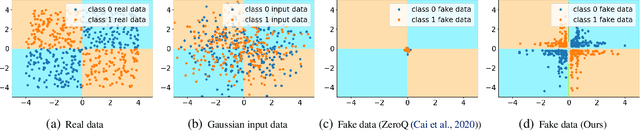
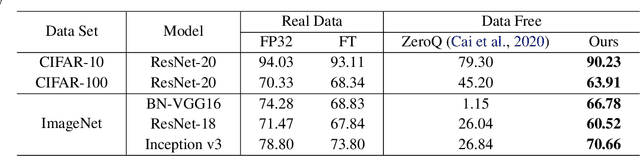
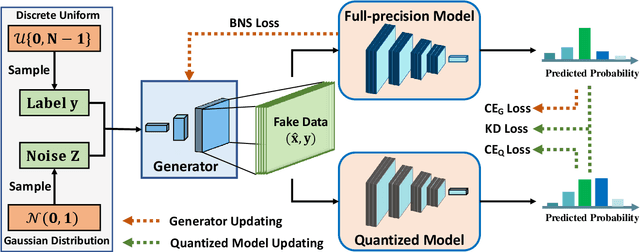
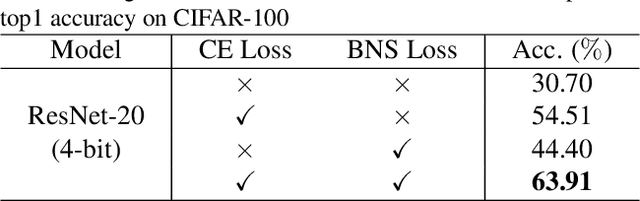
Neural network quantization is an effective way to compress deep models and improve the execution latency and energy efficiency, so that they can be deployed on mobile or embedded devices. Existing quantization methods require original data for calibration or fine-tuning to get better performance. However, in many real-world scenarios, the data may not be available due to confidential or private issues, making existing quantization methods not applicable. Moreover, due to the absence of original data, the recently developed generative adversarial networks (GANs) can not be applied to generate data. Although the full precision model may contain the entire data information, such information alone is hard to exploit for recovering the original data or generating new meaningful data. In this paper, we investigate a simple-yet-effective method called Generative Low-bitwidth Data Free Quantization to remove the data dependence burden. Specifically, we propose a Knowledge Matching Generator to produce meaningful fake data by exploiting classification boundary knowledge and distribution information in the pre-trained model. With the help of generated data, we are able to quantize a model by learning knowledge from the pre-trained model. Extensive experiments on three data sets demonstrate the effectiveness of our method. More critically, our method achieves much higher accuracy on 4-bit quantization than the existing data free quantization method.
Solving Satisfiability of Polynomial Formulas By Sample-Cell Projection
Mar 04, 2020
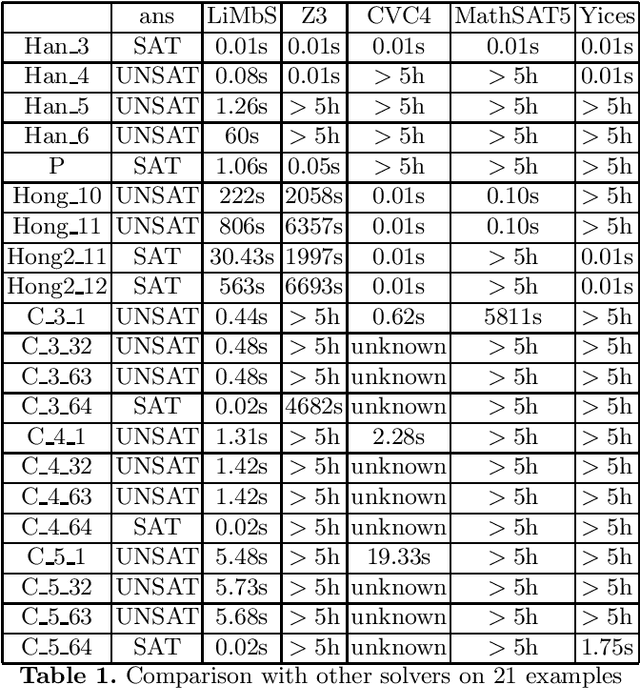
A new algorithm for deciding the satisfiability of polynomial formulas over the reals is proposed. The key point of the algorithm is a new projection operator, called sample-cell projection operator, custom-made for Conflict-Driven Clause Learning (CDCL)-style search. Although the new operator is also a CAD (Cylindrical Algebraic Decomposition)-like projection operator which computes the cell (not necessarily cylindrical) containing a given sample such that each polynomial from the problem is sign-invariant on the cell, it is of singly exponential time complexity. The sample-cell projection operator can efficiently guide CDCL-style search away from conflicting states. Experiments show the effectiveness of the new algorithm.