 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuiding Quantitative MRI Reconstruction with Phase-wise Uncertainty
Feb 28, 2025



Quantitative magnetic resonance imaging (qMRI) requires multi-phase acqui-sition, often relying on reduced data sampling and reconstruction algorithms to accelerate scans, which inherently poses an ill-posed inverse problem. While many studies focus on measuring uncertainty during this process, few explore how to leverage it to enhance reconstruction performance. In this paper, we in-troduce PUQ, a novel approach that pioneers the use of uncertainty infor-mation for qMRI reconstruction. PUQ employs a two-stage reconstruction and parameter fitting framework, where phase-wise uncertainty is estimated during reconstruction and utilized in the fitting stage. This design allows uncertainty to reflect the reliability of different phases and guide information integration during parameter fitting. We evaluated PUQ on in vivo T1 and T2 mapping datasets from healthy subjects. Compared to existing qMRI reconstruction methods, PUQ achieved the state-of-the-art performance in parameter map-pings, demonstrating the effectiveness of uncertainty guidance. Our code is available at https://anonymous.4open.science/r/PUQ-75B2/.
Graph Image Prior for Unsupervised Dynamic MRI Reconstruction
Mar 23, 2024The inductive bias of the convolutional neural network (CNN) can act as a strong prior for image restoration, which is known as the Deep Image Prior (DIP). In recent years, DIP has been utilized in unsupervised dynamic MRI reconstruction, which adopts a generative model from the latent space to the image space. However, existing methods usually utilize a single pyramid-shaped CNN architecture to parameterize the generator, which cannot effectively exploit the spatio-temporal correlations within the dynamic data. In this work, we propose a novel scheme to exploit the DIP prior for dynamic MRI reconstruction, named ``Graph Image Prior'' (GIP). The generative model is decomposed into two stages: image recovery and manifold discovery, which is bridged by a graph convolutional network to exploit the spatio-temporal correlations. In addition, we devise an ADMM algorithm to alternately optimize the images and the network parameters to further improve the reconstruction performance. Experimental results demonstrate that GIP outperforms compressed sensing methods and unsupervised methods over different sampling trajectories, and significantly reduces the performance gap with the state-of-art supervised deep-learning methods. Moreover, GIP displays superior generalization ability when transferred to a different reconstruction setting, without the need for any additional data.
Compound Attention and Neighbor Matching Network for Multi-contrast MRI Super-resolution
Jul 24, 2023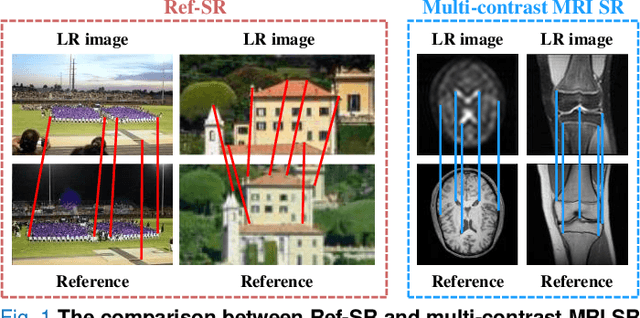
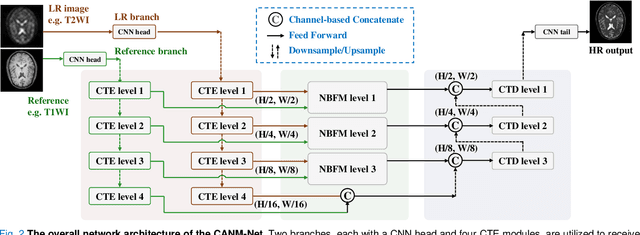

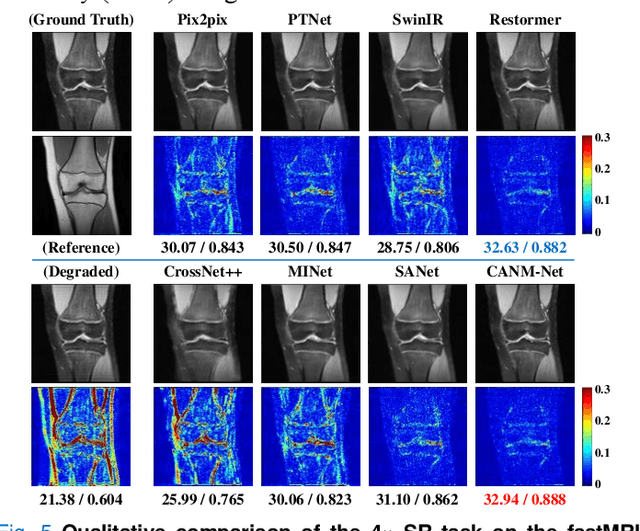
Multi-contrast magnetic resonance imaging (MRI) reflects information about human tissue from different perspectives and has many clinical applications. By utilizing the complementary information among different modalities, multi-contrast super-resolution (SR) of MRI can achieve better results than single-image super-resolution. However, existing methods of multi-contrast MRI SR have the following shortcomings that may limit their performance: First, existing methods either simply concatenate the reference and degraded features or exploit global feature-matching between them, which are unsuitable for multi-contrast MRI SR. Second, although many recent methods employ transformers to capture long-range dependencies in the spatial dimension, they neglect that self-attention in the channel dimension is also important for low-level vision tasks. To address these shortcomings, we proposed a novel network architecture with compound-attention and neighbor matching (CANM-Net) for multi-contrast MRI SR: The compound self-attention mechanism effectively captures the dependencies in both spatial and channel dimension; the neighborhood-based feature-matching modules are exploited to match degraded features and adjacent reference features and then fuse them to obtain the high-quality images. We conduct experiments of SR tasks on the IXI, fastMRI, and real-world scanning datasets. The CANM-Net outperforms state-of-the-art approaches in both retrospective and prospective experiments. Moreover, the robustness study in our work shows that the CANM-Net still achieves good performance when the reference and degraded images are imperfectly registered, proving good potential in clinical applications.
Towards Generalizable Medical Image Segmentation with Pixel-wise Uncertainty Estimation
May 13, 2023Deep neural networks (DNNs) achieve promising performance in visual recognition under the independent and identically distributed (IID) hypothesis. In contrast, the IID hypothesis is not universally guaranteed in numerous real-world applications, especially in medical image analysis. Medical image segmentation is typically formulated as a pixel-wise classification task in which each pixel is classified into a category. However, this formulation ignores the hard-to-classified pixels, e.g., some pixels near the boundary area, as they usually confuse DNNs. In this paper, we first explore that hard-to-classified pixels are associated with high uncertainty. Based on this, we propose a novel framework that utilizes uncertainty estimation to highlight hard-to-classified pixels for DNNs, thereby improving its generalization. We evaluate our method on two popular benchmarks: prostate and fundus datasets. The results of the experiment demonstrate that our method outperforms state-of-the-art methods.
Prototype Knowledge Distillation for Medical Segmentation with Missing Modality
Mar 17, 2023Multi-modality medical imaging is crucial in clinical treatment as it can provide complementary information for medical image segmentation. However, collecting multi-modal data in clinical is difficult due to the limitation of the scan time and other clinical situations. As such, it is clinically meaningful to develop an image segmentation paradigm to handle this missing modality problem. In this paper, we propose a prototype knowledge distillation (ProtoKD) method to tackle the challenging problem, especially for the toughest scenario when only single modal data can be accessed. Specifically, our ProtoKD can not only distillate the pixel-wise knowledge of multi-modality data to single-modality data but also transfer intra-class and inter-class feature variations, such that the student model could learn more robust feature representation from the teacher model and inference with only one single modality data. Our method achieves state-of-the-art performance on BraTS benchmark.
Accelerated partial separable model using dimension-reduced optimization technique for ultra-fast cardiac MRI
Oct 02, 2022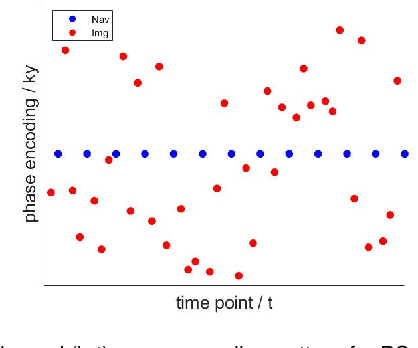
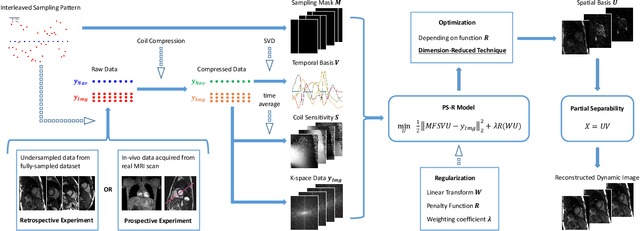
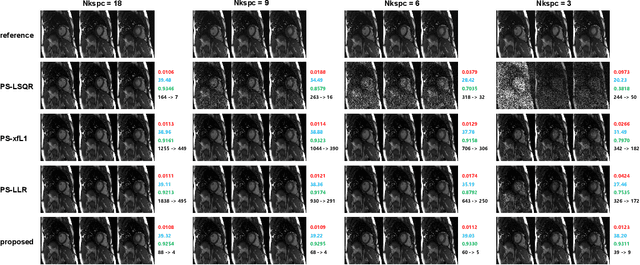
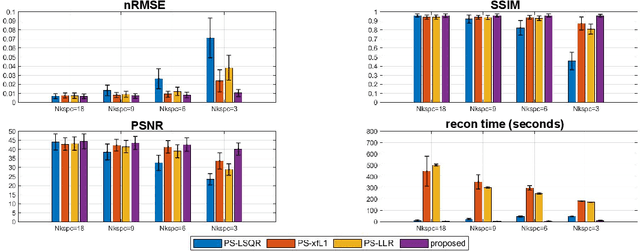
Partial separable(PS) model is a powerful model for dynamic magnetic resonance imaging (MRI). PS model explicitly reduces the degree of freedom in the reconstruction problem, which is beneficial for high temporal resolution applications. However, long acquisition time and even longer reconstruction time prohibit the acceptance of PS model in daily practice. In this work, we propose to fully exploit the dimension-reduction property to accelerate the PS model. We optimize the data consistency term, and use a Tikhonov regularization term based on Frobenius norm of temporal difference, resulting in a totally dimension-reduced optimization technique. The proposed method is used for accelerating the free-running cardiac MRI. We have performed both retrospective experiments on public dataset and prospective experiments on in-vivo data, and compared the proposed method with least-square method and another two popular regularized PS model methods. The results show that the proposed method has robust performance against shortened acquisition time or suboptimal hyper-parameter settings, and achieves superior image quality over all other competing algorithms. The proposed method is 20-fold faster than the widely accepted PS+Sparse method, enabling data acquisition and image reconstruction to be completed in just a few seconds.