 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafactory: A Scalable Agent Factory for Trustworthy Autonomous Intelligence
May 07, 2026As large models evolve from conversational assistants into autonomous agents, challenges increasingly arise from long-horizon decision making, tool use, and real environment interaction. Existing agenticinfrastructure remain fragmented across evaluation, data management, and agent evolution, making it difficult to discover risks systematically and improve models in a continuous closed loop. In this report, we present \textbf{Safactory}, a scalable agent factory for trustworthy autonomous intelligence. Safactory integrates three tightly coupled platforms: a \textbf{Parallel Simulation Platform} for trajectory generation, a \textbf{Trustworthy Data Platform} for trajectory storage and experience extraction, and an \textbf{Autonomous Evolution Platform} for asynchronous reinforcement learning and on-policy distillation. As far as we know, Safactory is the first framework to propose a unified evolutionary pipeline for next-generation trustworthy autonomous intelligence.
InkDrop: Invisible Backdoor Attacks Against Dataset Condensation
Mar 30, 2026Dataset Condensation (DC) is a data-efficient learning paradigm that synthesizes small yet informative datasets, enabling models to match the performance of full-data training. However, recent work exposes a critical vulnerability of DC to backdoor attacks, where malicious patterns (\textit{e.g.}, triggers) are implanted into the condensation dataset, inducing targeted misclassification on specific inputs. Existing attacks always prioritize attack effectiveness and model utility, overlooking the crucial dimension of stealthiness. To bridge this gap, we propose InkDrop, which enhances the imperceptibility of malicious manipulation without degrading attack effectiveness and model utility. InkDrop leverages the inherent uncertainty near model decision boundaries, where minor input perturbations can induce semantic shifts, to construct a stealthy and effective backdoor attack. Specifically, InkDrop first selects candidate samples near the target decision boundary that exhibit latent semantic affinity to the target class. It then learns instance-dependent perturbations constrained by perceptual and spatial consistency, embedding targeted malicious behavior into the condensed dataset. Extensive experiments across diverse datasets validate the overall effectiveness of InkDrop, demonstrating its ability to integrate adversarial intent into condensed datasets while preserving model utility and minimizing detectability. Our code is available at https://github.com/lvdongyi/InkDrop.
TCATSeg: A Tooth Center-Wise Attention Network for 3D Dental Model Semantic Segmentation
Mar 17, 2026Accurate semantic segmentation of 3D dental models is essential for digital dentistry applications such as orthodontics and dental implants. However, due to complex tooth arrangements and similarities in shape among adjacent teeth, existing methods struggle with accurate segmentation, because they often focus on local geometry while neglecting global contextual information. To address this, we propose TCATSeg, a novel framework that combines local geometric features with global semantic context. We introduce a set of sparse yet physically meaningful superpoints to capture global semantic relationships and enhance segmentation accuracy. Additionally, we present a new dataset of 400 dental models, including pre-orthodontic samples, to evaluate the generalization of our method. Extensive experiments demonstrate that TCATSeg outperforms state-of-the-art approaches.
SafeWork-R1: Coevolving Safety and Intelligence under the AI-45$^{\circ}$ Law
Jul 24, 2025



We introduce SafeWork-R1, a cutting-edge multimodal reasoning model that demonstrates the coevolution of capabilities and safety. It is developed by our proposed SafeLadder framework, which incorporates large-scale, progressive, safety-oriented reinforcement learning post-training, supported by a suite of multi-principled verifiers. Unlike previous alignment methods such as RLHF that simply learn human preferences, SafeLadder enables SafeWork-R1 to develop intrinsic safety reasoning and self-reflection abilities, giving rise to safety `aha' moments. Notably, SafeWork-R1 achieves an average improvement of $46.54\%$ over its base model Qwen2.5-VL-72B on safety-related benchmarks without compromising general capabilities, and delivers state-of-the-art safety performance compared to leading proprietary models such as GPT-4.1 and Claude Opus 4. To further bolster its reliability, we implement two distinct inference-time intervention methods and a deliberative search mechanism, enforcing step-level verification. Finally, we further develop SafeWork-R1-InternVL3-78B, SafeWork-R1-DeepSeek-70B, and SafeWork-R1-Qwen2.5VL-7B. All resulting models demonstrate that safety and capability can co-evolve synergistically, highlighting the generalizability of our framework in building robust, reliable, and trustworthy general-purpose AI.
BESA: Boosting Encoder Stealing Attack with Perturbation Recovery
Jun 05, 2025To boost the encoder stealing attack under the perturbation-based defense that hinders the attack performance, we propose a boosting encoder stealing attack with perturbation recovery named BESA. It aims to overcome perturbation-based defenses. The core of BESA consists of two modules: perturbation detection and perturbation recovery, which can be combined with canonical encoder stealing attacks. The perturbation detection module utilizes the feature vectors obtained from the target encoder to infer the defense mechanism employed by the service provider. Once the defense mechanism is detected, the perturbation recovery module leverages the well-designed generative model to restore a clean feature vector from the perturbed one. Through extensive evaluations based on various datasets, we demonstrate that BESA significantly enhances the surrogate encoder accuracy of existing encoder stealing attacks by up to 24.63\% when facing state-of-the-art defenses and combinations of multiple defenses.
Guiding Quantitative MRI Reconstruction with Phase-wise Uncertainty
Feb 28, 2025



Quantitative magnetic resonance imaging (qMRI) requires multi-phase acqui-sition, often relying on reduced data sampling and reconstruction algorithms to accelerate scans, which inherently poses an ill-posed inverse problem. While many studies focus on measuring uncertainty during this process, few explore how to leverage it to enhance reconstruction performance. In this paper, we in-troduce PUQ, a novel approach that pioneers the use of uncertainty infor-mation for qMRI reconstruction. PUQ employs a two-stage reconstruction and parameter fitting framework, where phase-wise uncertainty is estimated during reconstruction and utilized in the fitting stage. This design allows uncertainty to reflect the reliability of different phases and guide information integration during parameter fitting. We evaluated PUQ on in vivo T1 and T2 mapping datasets from healthy subjects. Compared to existing qMRI reconstruction methods, PUQ achieved the state-of-the-art performance in parameter map-pings, demonstrating the effectiveness of uncertainty guidance. Our code is available at https://anonymous.4open.science/r/PUQ-75B2/.
Static Batching of Irregular Workloads on GPUs: Framework and Application to Efficient MoE Model Inference
Jan 27, 2025
It has long been a problem to arrange and execute irregular workloads on massively parallel devices. We propose a general framework for statically batching irregular workloads into a single kernel with a runtime task mapping mechanism on GPUs. We further apply this framework to Mixture-of-Experts (MoE) model inference and implement an optimized and efficient CUDA kernel. Our MoE kernel achieves up to 91% of the peak Tensor Core throughput on NVIDIA H800 GPU and 95% on NVIDIA H20 GPU.
Teeth-SEG: An Efficient Instance Segmentation Framework for Orthodontic Treatment based on Anthropic Prior Knowledge
Apr 01, 2024



Teeth localization, segmentation, and labeling in 2D images have great potential in modern dentistry to enhance dental diagnostics, treatment planning, and population-based studies on oral health. However, general instance segmentation frameworks are incompetent due to 1) the subtle differences between some teeth' shapes (e.g., maxillary first premolar and second premolar), 2) the teeth's position and shape variation across subjects, and 3) the presence of abnormalities in the dentition (e.g., caries and edentulism). To address these problems, we propose a ViT-based framework named TeethSEG, which consists of stacked Multi-Scale Aggregation (MSA) blocks and an Anthropic Prior Knowledge (APK) layer. Specifically, to compose the two modules, we design 1) a unique permutation-based upscaler to ensure high efficiency while establishing clear segmentation boundaries with 2) multi-head self/cross-gating layers to emphasize particular semantics meanwhile maintaining the divergence between token embeddings. Besides, we collect 3) the first open-sourced intraoral image dataset IO150K, which comprises over 150k intraoral photos, and all photos are annotated by orthodontists using a human-machine hybrid algorithm. Experiments on IO150K demonstrate that our TeethSEG outperforms the state-of-the-art segmentation models on dental image segmentation.
Towards Transferable Adversarial Attacks with Centralized Perturbation
Dec 23, 2023
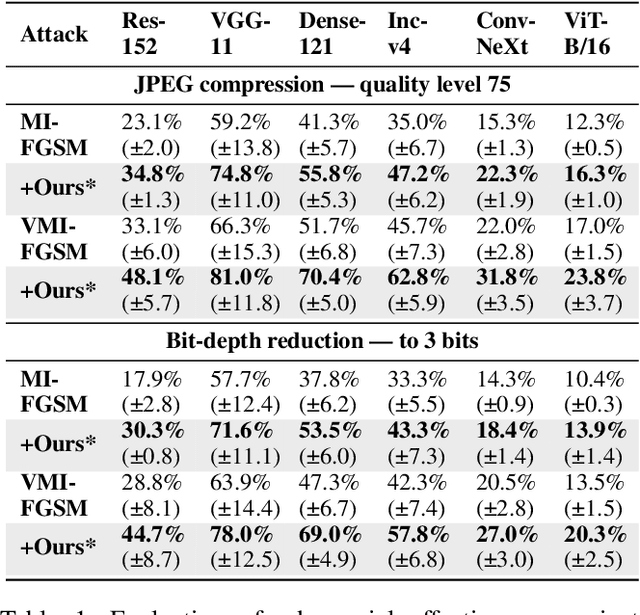
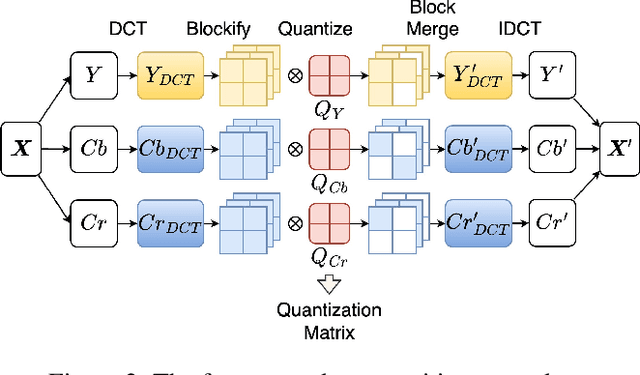
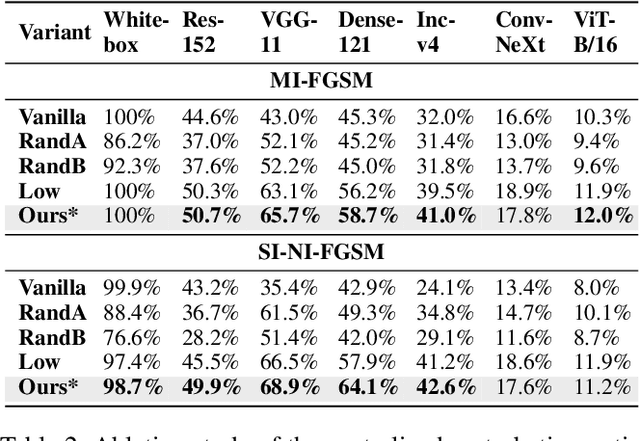
Adversarial transferability enables black-box attacks on unknown victim deep neural networks (DNNs), rendering attacks viable in real-world scenarios. Current transferable attacks create adversarial perturbation over the entire image, resulting in excessive noise that overfit the source model. Concentrating perturbation to dominant image regions that are model-agnostic is crucial to improving adversarial efficacy. However, limiting perturbation to local regions in the spatial domain proves inadequate in augmenting transferability. To this end, we propose a transferable adversarial attack with fine-grained perturbation optimization in the frequency domain, creating centralized perturbation. We devise a systematic pipeline to dynamically constrain perturbation optimization to dominant frequency coefficients. The constraint is optimized in parallel at each iteration, ensuring the directional alignment of perturbation optimization with model prediction. Our approach allows us to centralize perturbation towards sample-specific important frequency features, which are shared by DNNs, effectively mitigating source model overfitting. Experiments demonstrate that by dynamically centralizing perturbation on dominating frequency coefficients, crafted adversarial examples exhibit stronger transferability, and allowing them to bypass various defenses.
Unified High-binding Watermark for Unconditional Image Generation Models
Oct 14, 2023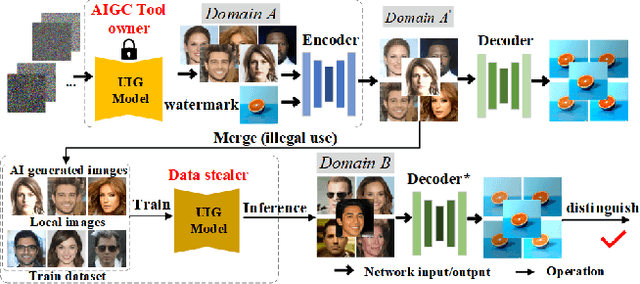
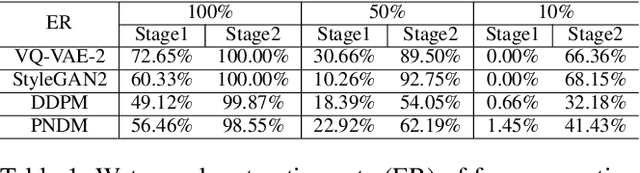
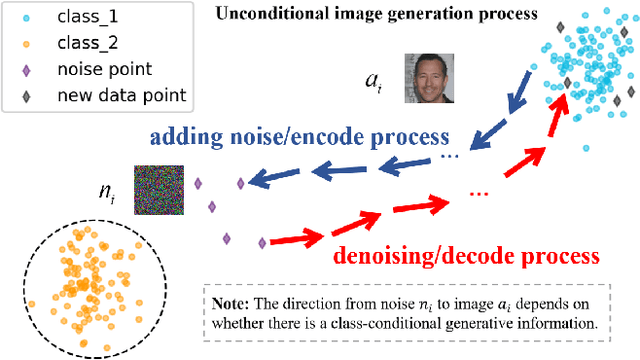
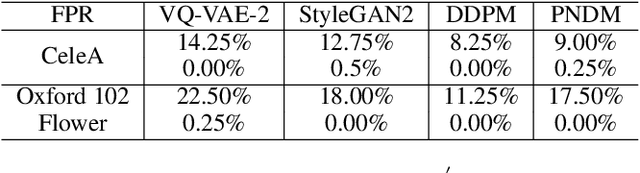
Deep learning techniques have implemented many unconditional image generation (UIG) models, such as GAN, Diffusion model, etc. The extremely realistic images (also known as AI-Generated Content, AIGC for short) produced by these models bring urgent needs for intellectual property protection such as data traceability and copyright certification. An attacker can steal the output images of the target model and use them as part of the training data to train a private surrogate UIG model. The implementation mechanisms of UIG models are diverse and complex, and there is no unified and effective protection and verification method at present. To address these issues, we propose a two-stage unified watermark verification mechanism with high-binding effects for such models. In the first stage, we use an encoder to invisibly write the watermark image into the output images of the original AIGC tool, and reversely extract the watermark image through the corresponding decoder. In the second stage, we design the decoder fine-tuning process, and the fine-tuned decoder can make correct judgments on whether the suspicious model steals the original AIGC tool data. Experiments demonstrate our method can complete the verification work with almost zero false positive rate under the condition of only using the model output images. Moreover, the proposed method can achieve data steal verification across different types of UIG models, which further increases the practicality of the method.