 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafeWork-R1: Coevolving Safety and Intelligence under the AI-45$^{\circ}$ Law
Jul 24, 2025



We introduce SafeWork-R1, a cutting-edge multimodal reasoning model that demonstrates the coevolution of capabilities and safety. It is developed by our proposed SafeLadder framework, which incorporates large-scale, progressive, safety-oriented reinforcement learning post-training, supported by a suite of multi-principled verifiers. Unlike previous alignment methods such as RLHF that simply learn human preferences, SafeLadder enables SafeWork-R1 to develop intrinsic safety reasoning and self-reflection abilities, giving rise to safety `aha' moments. Notably, SafeWork-R1 achieves an average improvement of $46.54\%$ over its base model Qwen2.5-VL-72B on safety-related benchmarks without compromising general capabilities, and delivers state-of-the-art safety performance compared to leading proprietary models such as GPT-4.1 and Claude Opus 4. To further bolster its reliability, we implement two distinct inference-time intervention methods and a deliberative search mechanism, enforcing step-level verification. Finally, we further develop SafeWork-R1-InternVL3-78B, SafeWork-R1-DeepSeek-70B, and SafeWork-R1-Qwen2.5VL-7B. All resulting models demonstrate that safety and capability can co-evolve synergistically, highlighting the generalizability of our framework in building robust, reliable, and trustworthy general-purpose AI.
Fast and Slow Gradient Approximation for Binary Neural Network Optimization
Dec 16, 2024



Binary Neural Networks (BNNs) have garnered significant attention due to their immense potential for deployment on edge devices. However, the non-differentiability of the quantization function poses a challenge for the optimization of BNNs, as its derivative cannot be backpropagated. To address this issue, hypernetwork based methods, which utilize neural networks to learn the gradients of non-differentiable quantization functions, have emerged as a promising approach due to their adaptive learning capabilities to reduce estimation errors. However, existing hypernetwork based methods typically rely solely on current gradient information, neglecting the influence of historical gradients. This oversight can lead to accumulated gradient errors when calculating gradient momentum during optimization. To incorporate historical gradient information, we design a Historical Gradient Storage (HGS) module, which models the historical gradient sequence to generate the first-order momentum required for optimization. To further enhance gradient generation in hypernetworks, we propose a Fast and Slow Gradient Generation (FSG) method. Additionally, to produce more precise gradients, we introduce Layer Recognition Embeddings (LRE) into the hypernetwork, facilitating the generation of layer-specific fine gradients. Extensive comparative experiments on the CIFAR-10 and CIFAR-100 datasets demonstrate that our method achieves faster convergence and lower loss values, outperforming existing baselines.Code is available at http://github.com/two-tiger/FSG .
SR-CIS: Self-Reflective Incremental System with Decoupled Memory and Reasoning
Aug 04, 2024The ability of humans to rapidly learn new knowledge while retaining old memories poses a significant challenge for current deep learning models. To handle this challenge, we draw inspiration from human memory and learning mechanisms and propose the Self-Reflective Complementary Incremental System (SR-CIS). Comprising the deconstructed Complementary Inference Module (CIM) and Complementary Memory Module (CMM), SR-CIS features a small model for fast inference and a large model for slow deliberation in CIM, enabled by the Confidence-Aware Online Anomaly Detection (CA-OAD) mechanism for efficient collaboration. CMM consists of task-specific Short-Term Memory (STM) region and a universal Long-Term Memory (LTM) region. By setting task-specific Low-Rank Adaptive (LoRA) and corresponding prototype weights and biases, it instantiates external storage for parameter and representation memory, thus deconstructing the memory module from the inference module. By storing textual descriptions of images during training and combining them with the Scenario Replay Module (SRM) post-training for memory combination, along with periodic short-to-long-term memory restructuring, SR-CIS achieves stable incremental memory with limited storage requirements. Balancing model plasticity and memory stability under constraints of limited storage and low data resources, SR-CIS surpasses existing competitive baselines on multiple standard and few-shot incremental learning benchmarks.
Peer-Assisted Robotic Learning: A Data-Driven Collaborative Learning Approach for Cloud Robotic Systems
Oct 16, 2020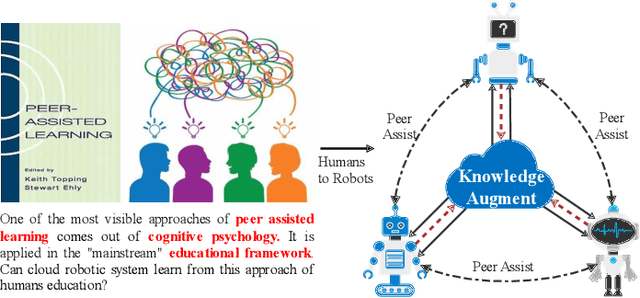
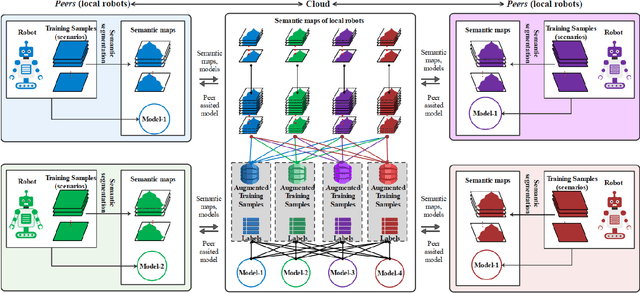
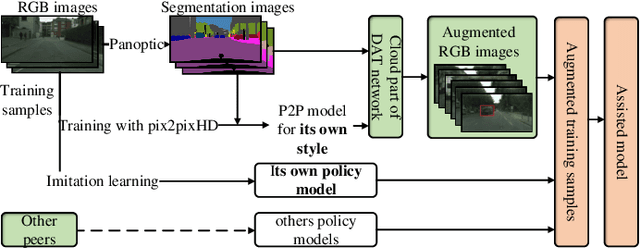
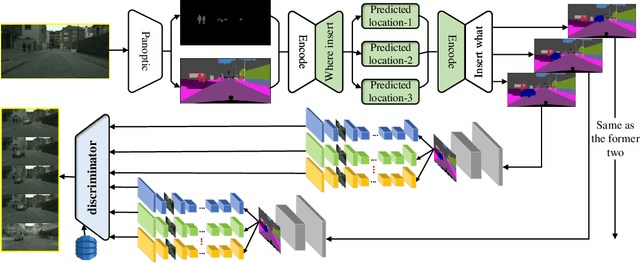
A technological revolution is occurring in the field of robotics with the data-driven deep learning technology. However, building datasets for each local robot is laborious. Meanwhile, data islands between local robots make data unable to be utilized collaboratively. To address this issue, the work presents Peer-Assisted Robotic Learning (PARL) in robotics, which is inspired by the peer-assisted learning in cognitive psychology and pedagogy. PARL implements data collaboration with the framework of cloud robotic systems. Both data and models are shared by robots to the cloud after semantic computing and training locally. The cloud converges the data and performs augmentation, integration, and transferring. Finally, fine tune this larger shared dataset in the cloud to local robots. Furthermore, we propose the DAT Network (Data Augmentation and Transferring Network) to implement the data processing in PARL. DAT Network can realize the augmentation of data from multi-local robots. We conduct experiments on a simplified self-driving task for robots (cars). DAT Network has a significant improvement in the augmentation in self-driving scenarios. Along with this, the self-driving experimental results also demonstrate that PARL is capable of improving learning effects with data collaboration of local robots.
Synchronization Clustering based on a Linearized Version of Vicsek model
Nov 02, 2014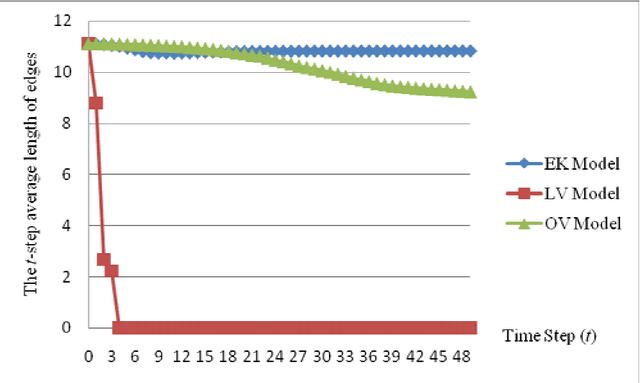
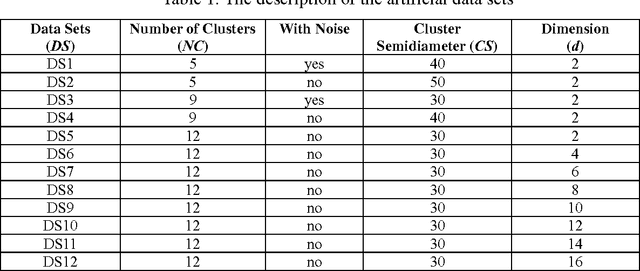
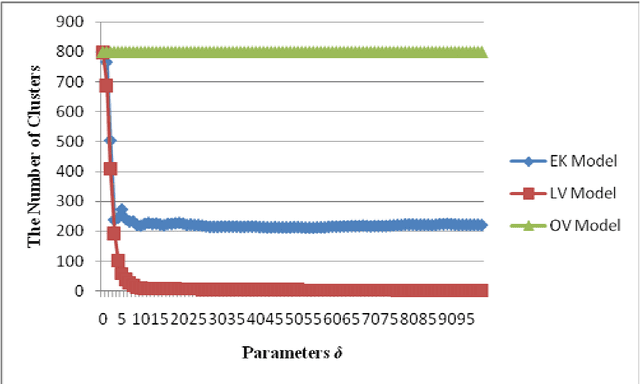
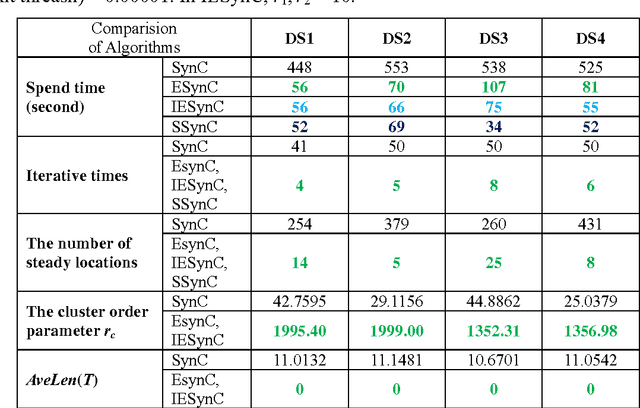
This paper presents a kind of effective synchronization clustering method based on a linearized version of Vicsek model. This method can be represented by an Effective Synchronization Clustering algorithm (ESynC), an Improved version of ESynC algorithm (IESynC), a Shrinking Synchronization Clustering algorithm based on another linear Vicsek model (SSynC), and an effective Multi-level Synchronization Clustering algorithm (MSynC). After some analysis and comparisions, we find that ESynC algorithm based on the Linearized version of the Vicsek model has better synchronization effect than SynC algorithm based on an extensive Kuramoto model and a similar synchronization clustering algorithm based on the original Vicsek model. By simulated experiments of some artificial data sets, we observe that ESynC algorithm, IESynC algorithm, and SSynC algorithm can get better synchronization effect although it needs less iterative times and less time than SynC algorithm. In some simulations, we also observe that IESynC algorithm and SSynC algorithm can get some improvements in time cost than ESynC algorithm. At last, it gives some research expectations to popularize this algorithm.
A Fast Synchronization Clustering Algorithm
Jul 23, 2014
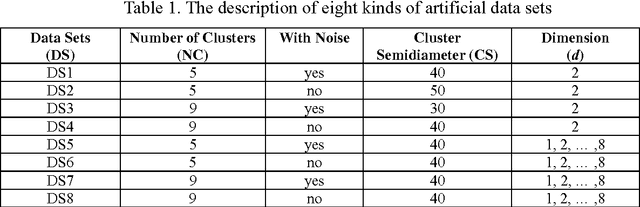
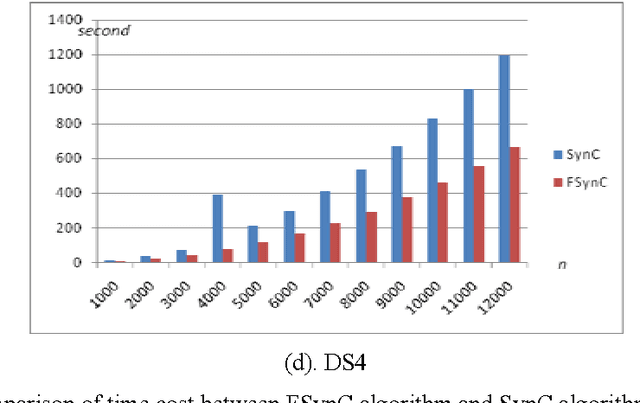
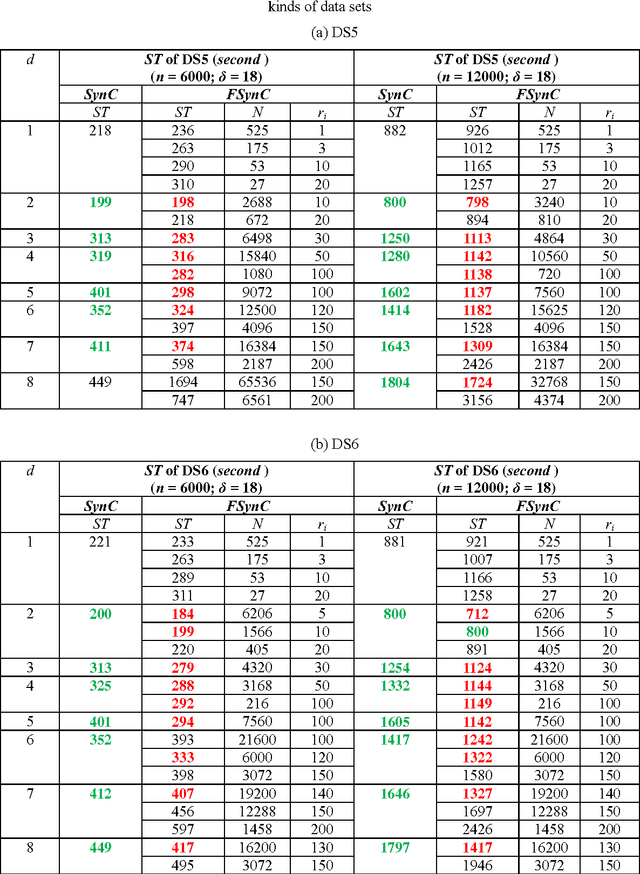
This paper presents a Fast Synchronization Clustering algorithm (FSynC), which is an improved version of SynC algorithm. In order to decrease the time complexity of the original SynC algorithm, we combine grid cell partitioning method and Red-Black tree to construct the near neighbor point set of every point. By simulated experiments of some artificial data sets and several real data sets, we observe that FSynC algorithm can often get less time than SynC algorithm for many kinds of data sets. At last, it gives some research expectations to popularize this algorithm.