 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoDistill: Language-aware Vision Distillation for Video Question Answering
Apr 01, 2024
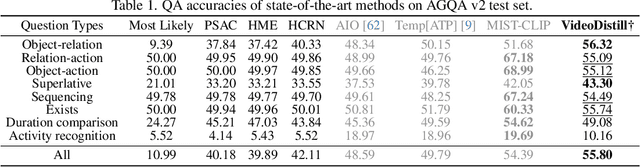
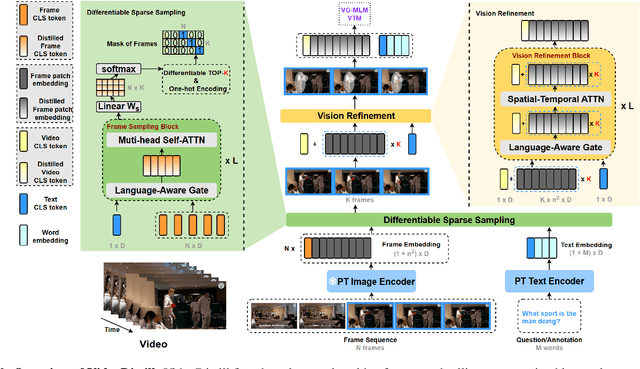
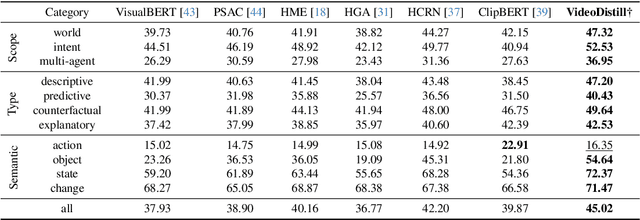
Significant advancements in video question answering (VideoQA) have been made thanks to thriving large image-language pretraining frameworks. Although these image-language models can efficiently represent both video and language branches, they typically employ a goal-free vision perception process and do not interact vision with language well during the answer generation, thus omitting crucial visual cues. In this paper, we are inspired by the human recognition and learning pattern and propose VideoDistill, a framework with language-aware (i.e., goal-driven) behavior in both vision perception and answer generation process. VideoDistill generates answers only from question-related visual embeddings and follows a thinking-observing-answering approach that closely resembles human behavior, distinguishing it from previous research. Specifically, we develop a language-aware gating mechanism to replace the standard cross-attention, avoiding language's direct fusion into visual representations. We incorporate this mechanism into two key components of the entire framework. The first component is a differentiable sparse sampling module, which selects frames containing the necessary dynamics and semantics relevant to the questions. The second component is a vision refinement module that merges existing spatial-temporal attention layers to ensure the extraction of multi-grained visual semantics associated with the questions. We conduct experimental evaluations on various challenging video question-answering benchmarks, and VideoDistill achieves state-of-the-art performance in both general and long-form VideoQA datasets. In Addition, we verify that VideoDistill can effectively alleviate the utilization of language shortcut solutions in the EgoTaskQA dataset.
LLaMA-Excitor: General Instruction Tuning via Indirect Feature Interaction
Apr 01, 2024Existing methods to fine-tune LLMs, like Adapter, Prefix-tuning, and LoRA, which introduce extra modules or additional input sequences to inject new skills or knowledge, may compromise the innate abilities of LLMs. In this paper, we propose LLaMA-Excitor, a lightweight method that stimulates the LLMs' potential to better follow instructions by gradually paying more attention to worthwhile information. Specifically, the LLaMA-Excitor does not directly change the intermediate hidden state during the self-attention calculation of the transformer structure. We designed the Excitor block as a bypass module for the similarity score computation in LLMs' self-attention to reconstruct keys and change the importance of values by learnable prompts. LLaMA-Excitor ensures a self-adaptive allocation of additional attention to input instructions, thus effectively preserving LLMs' pre-trained knowledge when fine-tuning LLMs on low-quality instruction-following datasets. Furthermore, we unify the modeling of multi-modal tuning and language-only tuning, extending LLaMA-Excitor to a powerful visual instruction follower without the need for complex multi-modal alignment. Our proposed approach is evaluated in language-only and multi-modal tuning experimental scenarios. Notably, LLaMA-Excitor is the only method that maintains basic capabilities while achieving a significant improvement (+6%) on the MMLU benchmark. In the visual instruction tuning, we achieve a new state-of-the-art image captioning performance of 157.5 CIDEr on MSCOCO, and a comparable performance (88.39%) on ScienceQA to cutting-edge models with more parameters and extensive vision-language pertaining.
Teeth-SEG: An Efficient Instance Segmentation Framework for Orthodontic Treatment based on Anthropic Prior Knowledge
Apr 01, 2024



Teeth localization, segmentation, and labeling in 2D images have great potential in modern dentistry to enhance dental diagnostics, treatment planning, and population-based studies on oral health. However, general instance segmentation frameworks are incompetent due to 1) the subtle differences between some teeth' shapes (e.g., maxillary first premolar and second premolar), 2) the teeth's position and shape variation across subjects, and 3) the presence of abnormalities in the dentition (e.g., caries and edentulism). To address these problems, we propose a ViT-based framework named TeethSEG, which consists of stacked Multi-Scale Aggregation (MSA) blocks and an Anthropic Prior Knowledge (APK) layer. Specifically, to compose the two modules, we design 1) a unique permutation-based upscaler to ensure high efficiency while establishing clear segmentation boundaries with 2) multi-head self/cross-gating layers to emphasize particular semantics meanwhile maintaining the divergence between token embeddings. Besides, we collect 3) the first open-sourced intraoral image dataset IO150K, which comprises over 150k intraoral photos, and all photos are annotated by orthodontists using a human-machine hybrid algorithm. Experiments on IO150K demonstrate that our TeethSEG outperforms the state-of-the-art segmentation models on dental image segmentation.
Modeling Household Online Shopping Demand in the U.S.: A Machine Learning Approach and Comparative Investigation between 2009 and 2017
Jan 11, 2021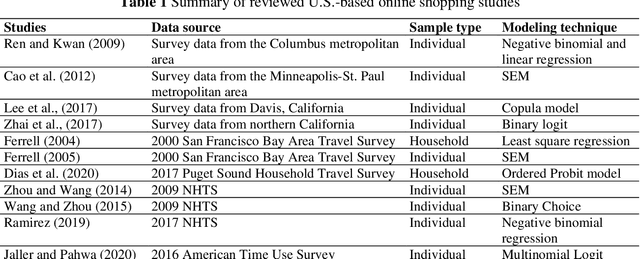
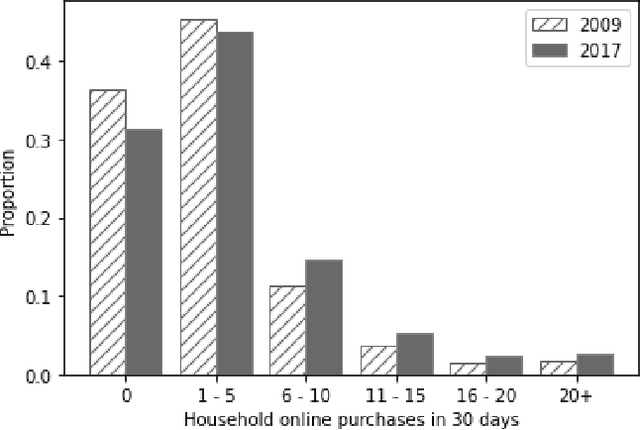
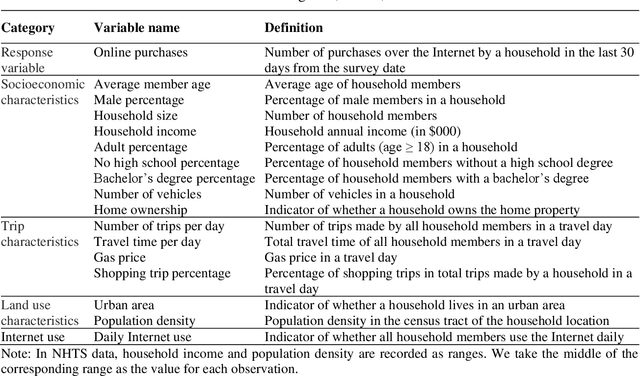
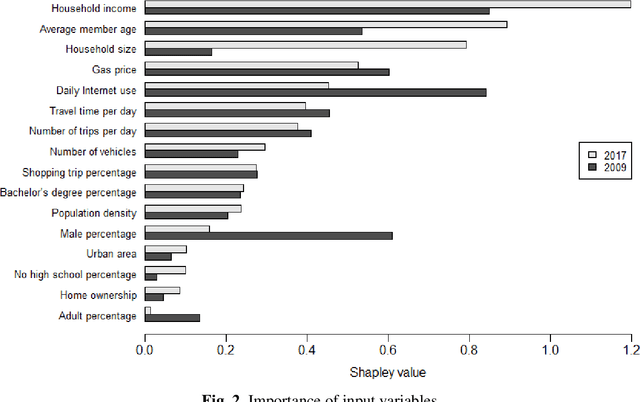
Despite the rapid growth of online shopping and research interest in the relationship between online and in-store shopping, national-level modeling and investigation of the demand for online shopping with a prediction focus remain limited in the literature. This paper differs from prior work and leverages two recent releases of the U.S. National Household Travel Survey (NHTS) data for 2009 and 2017 to develop machine learning (ML) models, specifically gradient boosting machine (GBM), for predicting household-level online shopping purchases. The NHTS data allow for not only conducting nationwide investigation but also at the level of households, which is more appropriate than at the individual level given the connected consumption and shopping needs of members in a household. We follow a systematic procedure for model development including employing Recursive Feature Elimination algorithm to select input variables (features) in order to reduce the risk of model overfitting and increase model explainability. Extensive post-modeling investigation is conducted in a comparative manner between 2009 and 2017, including quantifying the importance of each input variable in predicting online shopping demand, and characterizing value-dependent relationships between demand and the input variables. In doing so, two latest advances in machine learning techniques, namely Shapley value-based feature importance and Accumulated Local Effects plots, are adopted to overcome inherent drawbacks of the popular techniques in current ML modeling. The modeling and investigation are performed both at the national level and for three of the largest cities (New York, Los Angeles, and Houston). The models developed and insights gained can be used for online shopping-related freight demand generation and may also be considered for evaluating the potential impact of relevant policies on online shopping demand.
Deep Reinforcement Learning for Crowdsourced Urban Delivery: System States Characterization, Heuristics-guided Action Choice, and Rule-Interposing Integration
Nov 29, 2020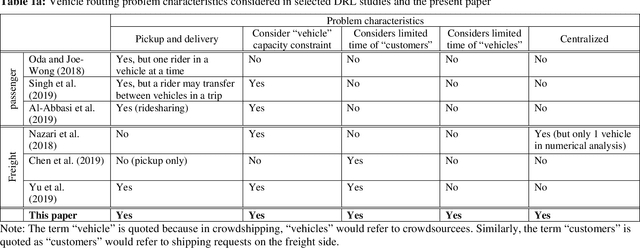
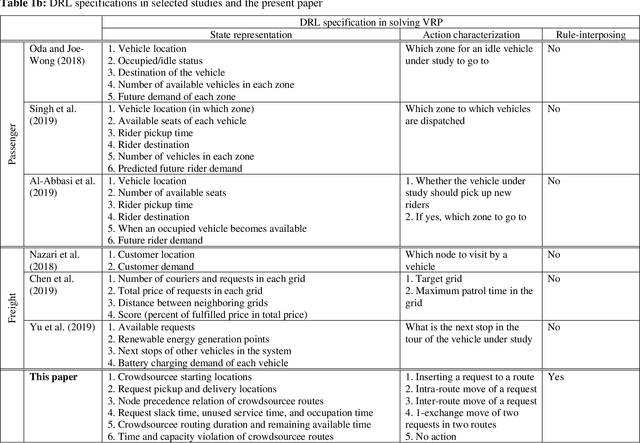


This paper investigates the problem of assigning shipping requests to ad hoc couriers in the context of crowdsourced urban delivery. The shipping requests are spatially distributed each with a limited time window between the earliest time for pickup and latest time for delivery. The ad hoc couriers, termed crowdsourcees, also have limited time availability and carrying capacity. We propose a new deep reinforcement learning (DRL)-based approach to tackling this assignment problem. A deep Q network (DQN) algorithm is trained which entails two salient features of experience replay and target network that enhance the efficiency, convergence, and stability of DRL training. More importantly, this paper makes three methodological contributions: 1) presenting a comprehensive and novel characterization of crowdshipping system states that encompasses spatial-temporal and capacity information of crowdsourcees and requests; 2) embedding heuristics that leverage the information offered by the state representation and are based on intuitive reasoning to guide specific actions to take, to preserve tractability and enhance efficiency of training; and 3) integrating rule-interposing to prevent repeated visiting of the same routes and node sequences during routing improvement, thereby further enhancing the training efficiency by accelerating learning. The effectiveness of the proposed approach is demonstrated through extensive numerical analysis. The results show the benefits brought by the heuristics-guided action choice and rule-interposing in DRL training, and the superiority of the proposed approach over existing heuristics in both solution quality, time, and scalability. Besides the potential to improve the efficiency of crowdshipping operation planning, the proposed approach also provides a new avenue and generic framework for other problems in the vehicle routing context.
Deep Reinforcement Learning and Transportation Research: A Comprehensive Review
Oct 13, 2020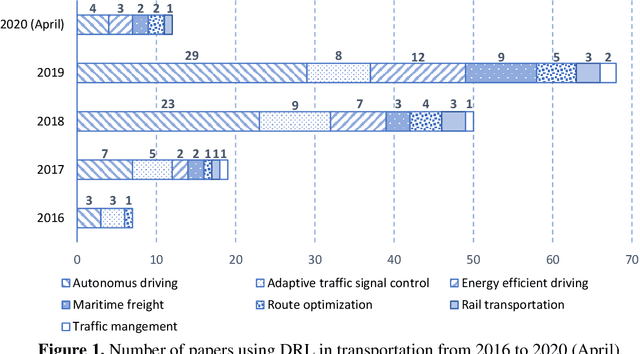
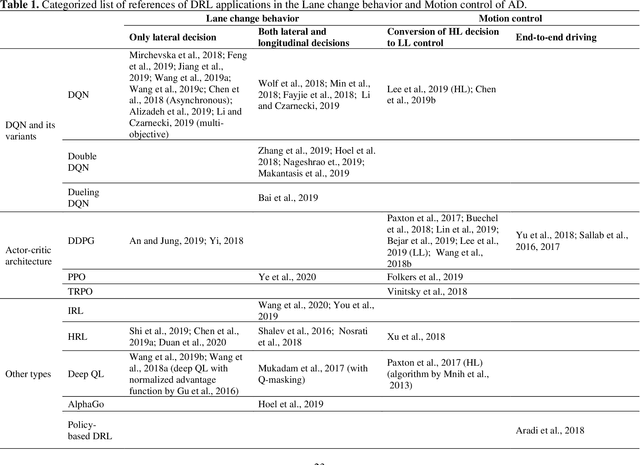
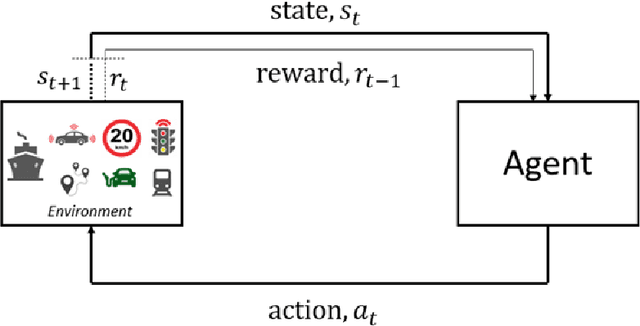
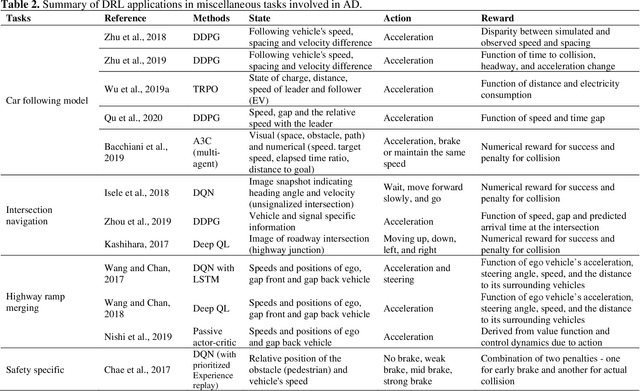
Deep reinforcement learning (DRL) is an emerging methodology that is transforming the way many complicated transportation decision-making problems are tackled. Researchers have been increasingly turning to this powerful learning-based methodology to solve challenging problems across transportation fields. While many promising applications have been reported in the literature, there remains a lack of comprehensive synthesis of the many DRL algorithms and their uses and adaptations. The objective of this paper is to fill this gap by conducting a comprehensive, synthesized review of DRL applications in transportation. We start by offering an overview of the DRL mathematical background, popular and promising DRL algorithms, and some highly effective DRL extensions. Building on this overview, a systematic investigation of about 150 DRL studies that have appeared in the transportation literature, divided into seven different categories, is performed. Building on this review, we continue to examine the applicability, strengths, shortcomings, and common and application-specific issues of DRL techniques with regard to their applications in transportation. In the end, we recommend directions for future research and present available resources for actually implementing DRL.