 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning for Stock Transactions
May 22, 2025



Much research has been done to analyze the stock market. After all, if one can determine a pattern in the chaotic frenzy of transactions, then they could make a hefty profit from capitalizing on these insights. As such, the goal of our project was to apply reinforcement learning (RL) to determine the best time to buy a stock within a given time frame. With only a few adjustments, our model can be extended to identify the best time to sell a stock as well. In order to use the format of free, real-world data to train the model, we define our own Markov Decision Process (MDP) problem. These two papers [5] [6] helped us in formulating the state space and the reward system of our MDP problem. We train a series of agents using Q-Learning, Q-Learning with linear function approximation, and deep Q-Learning. In addition, we try to predict the stock prices using machine learning regression and classification models. We then compare our agents to see if they converge on a policy, and if so, which one learned the best policy to maximize profit on the stock market.
On Vanishing Variance in Transformer Length Generalization
Apr 03, 2025It is a widely known issue that Transformers, when trained on shorter sequences, fail to generalize robustly to longer ones at test time. This raises the question of whether Transformer models are real reasoning engines, despite their impressive abilities in mathematical problem solving and code synthesis. In this paper, we offer a vanishing variance perspective on this issue. To the best of our knowledge, we are the first to demonstrate that even for today's frontier models, a longer sequence length results in a decrease in variance in the output of the multi-head attention modules. On the argmax retrieval and dictionary lookup tasks, our experiments show that applying layer normalization after the attention outputs leads to significantly better length generalization. Our analyses attribute this improvement to a reduction-though not a complete elimination-of the distribution shift caused by vanishing variance.
Stable Virtual Camera: Generative View Synthesis with Diffusion Models
Mar 18, 2025We present Stable Virtual Camera (Seva), a generalist diffusion model that creates novel views of a scene, given any number of input views and target cameras. Existing works struggle to generate either large viewpoint changes or temporally smooth samples, while relying on specific task configurations. Our approach overcomes these limitations through simple model design, optimized training recipe, and flexible sampling strategy that generalize across view synthesis tasks at test time. As a result, our samples maintain high consistency without requiring additional 3D representation-based distillation, thus streamlining view synthesis in the wild. Furthermore, we show that our method can generate high-quality videos lasting up to half a minute with seamless loop closure. Extensive benchmarking demonstrates that Seva outperforms existing methods across different datasets and settings.
Generative AI in Transportation Planning: A Survey
Mar 10, 2025

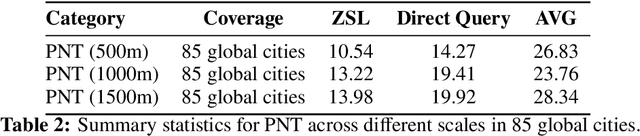
The integration of generative artificial intelligence (GenAI) into transportation planning has the potential to revolutionize tasks such as demand forecasting, infrastructure design, policy evaluation, and traffic simulation. However, there is a critical need for a systematic framework to guide the adoption of GenAI in this interdisciplinary domain. In this survey, we, a multidisciplinary team of researchers spanning computer science and transportation engineering, present the first comprehensive framework for leveraging GenAI in transportation planning. Specifically, we introduce a new taxonomy that categorizes existing applications and methodologies into two perspectives: transportation planning tasks and computational techniques. From the transportation planning perspective, we examine the role of GenAI in automating descriptive, predictive, generative, simulation, and explainable tasks to enhance mobility systems. From the computational perspective, we detail advancements in data preparation, domain-specific fine-tuning, and inference strategies, such as retrieval-augmented generation and zero-shot learning tailored to transportation applications. Additionally, we address critical challenges, including data scarcity, explainability, bias mitigation, and the development of domain-specific evaluation frameworks that align with transportation goals like sustainability, equity, and system efficiency. This survey aims to bridge the gap between traditional transportation planning methodologies and modern AI techniques, fostering collaboration and innovation. By addressing these challenges and opportunities, we seek to inspire future research that ensures ethical, equitable, and impactful use of generative AI in transportation planning.
Modeling Household Online Shopping Demand in the U.S.: A Machine Learning Approach and Comparative Investigation between 2009 and 2017
Jan 11, 2021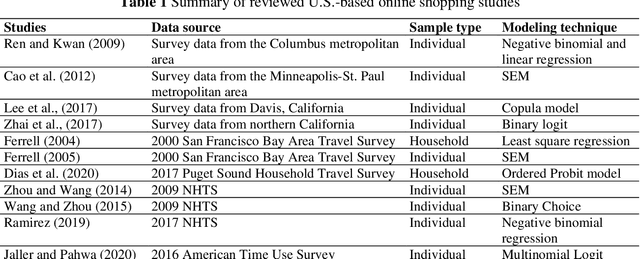
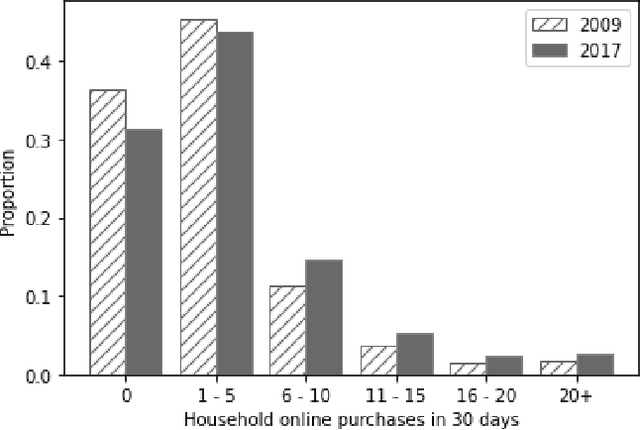
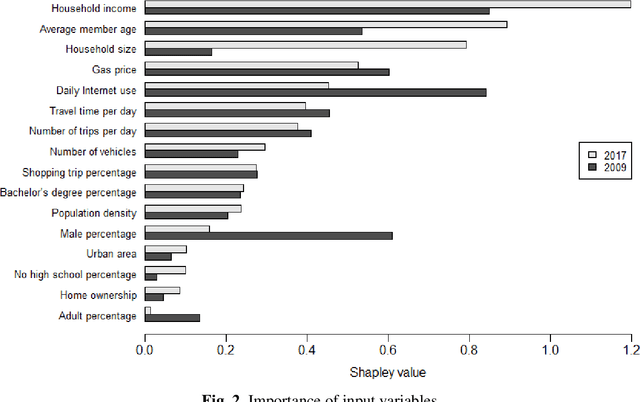
Despite the rapid growth of online shopping and research interest in the relationship between online and in-store shopping, national-level modeling and investigation of the demand for online shopping with a prediction focus remain limited in the literature. This paper differs from prior work and leverages two recent releases of the U.S. National Household Travel Survey (NHTS) data for 2009 and 2017 to develop machine learning (ML) models, specifically gradient boosting machine (GBM), for predicting household-level online shopping purchases. The NHTS data allow for not only conducting nationwide investigation but also at the level of households, which is more appropriate than at the individual level given the connected consumption and shopping needs of members in a household. We follow a systematic procedure for model development including employing Recursive Feature Elimination algorithm to select input variables (features) in order to reduce the risk of model overfitting and increase model explainability. Extensive post-modeling investigation is conducted in a comparative manner between 2009 and 2017, including quantifying the importance of each input variable in predicting online shopping demand, and characterizing value-dependent relationships between demand and the input variables. In doing so, two latest advances in machine learning techniques, namely Shapley value-based feature importance and Accumulated Local Effects plots, are adopted to overcome inherent drawbacks of the popular techniques in current ML modeling. The modeling and investigation are performed both at the national level and for three of the largest cities (New York, Los Angeles, and Houston). The models developed and insights gained can be used for online shopping-related freight demand generation and may also be considered for evaluating the potential impact of relevant policies on online shopping demand.
Bio-inspired Structure Identification in Language Embeddings
Sep 15, 2020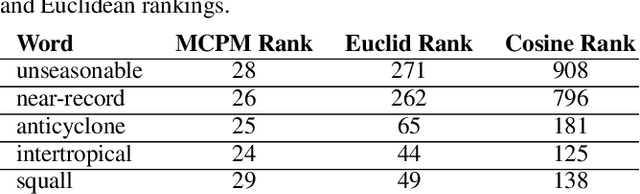
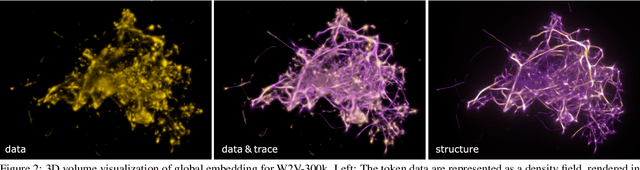

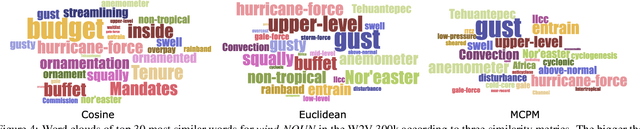
Word embeddings are a popular way to improve downstream performances in contemporary language modeling. However, the underlying geometric structure of the embedding space is not well understood. We present a series of explorations using bio-inspired methodology to traverse and visualize word embeddings, demonstrating evidence of discernible structure. Moreover, our model also produces word similarity rankings that are plausible yet very different from common similarity metrics, mainly cosine similarity and Euclidean distance. We show that our bio-inspired model can be used to investigate how different word embedding techniques result in different semantic outputs, which can emphasize or obscure particular interpretations in textual data.