 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Vision Language Models Understand Human Engagement in Games?
Mar 19, 2026Inferring human engagement from gameplay video is important for game design and player-experience research, yet it remains unclear whether vision--language models (VLMs) can infer such latent psychological states from visual cues alone. Using the GameVibe Few-Shot dataset across nine first-person shooter games, we evaluate three VLMs under six prompting strategies, including zero-shot prediction, theory-guided prompts grounded in Flow, GameFlow, Self-Determination Theory, and MDA, and retrieval-augmented prompting. We consider both pointwise engagement prediction and pairwise prediction of engagement change between consecutive windows. Results show that zero-shot VLM predictions are generally weak and often fail to outperform simple per-game majority-class baselines. Memory- or retrieval-augmented prompting improves pointwise prediction in some settings, whereas pairwise prediction remains consistently difficult across strategies. Theory-guided prompting alone does not reliably help and can instead reinforce surface-level shortcuts. These findings suggest a perception--understanding gap in current VLMs: although they can recognize visible gameplay cues, they still struggle to robustly infer human engagement across games.
Fairness or Fluency? An Investigation into Language Bias of Pairwise LLM-as-a-Judge
Jan 20, 2026Recent advances in Large Language Models (LLMs) have incentivized the development of LLM-as-a-judge, an application of LLMs where they are used as judges to decide the quality of a certain piece of text given a certain context. However, previous studies have demonstrated that LLM-as-a-judge can be biased towards different aspects of the judged texts, which often do not align with human preference. One of the identified biases is language bias, which indicates that the decision of LLM-as-a-judge can differ based on the language of the judged texts. In this paper, we study two types of language bias in pairwise LLM-as-a-judge: (1) performance disparity between languages when the judge is prompted to compare options from the same language, and (2) bias towards options written in major languages when the judge is prompted to compare options of two different languages. We find that for same-language judging, there exist significant performance disparities across language families, with European languages consistently outperforming African languages, and this bias is more pronounced in culturally-related subjects. For inter-language judging, we observe that most models favor English answers, and that this preference is influenced more by answer language than question language. Finally, we investigate whether language bias is in fact caused by low-perplexity bias, a previously identified bias of LLM-as-a-judge, and we find that while perplexity is slightly correlated with language bias, language bias cannot be fully explained by perplexity only.
Multimodal Generative Engine Optimization: Rank Manipulation for Vision-Language Model Rankers
Jan 18, 2026Vision-Language Models (VLMs) are rapidly replacing unimodal encoders in modern retrieval and recommendation systems. While their capabilities are well-documented, their robustness against adversarial manipulation in competitive ranking scenarios remains largely unexplored. In this paper, we uncover a critical vulnerability in VLM-based product search: multimodal ranking attacks. We present Multimodal Generative Engine Optimization (MGEO), a novel adversarial framework that enables a malicious actor to unfairly promote a target product by jointly optimizing imperceptible image perturbations and fluent textual suffixes. Unlike existing attacks that treat modalities in isolation, MGEO employs an alternating gradient-based optimization strategy to exploit the deep cross-modal coupling within the VLM. Extensive experiments on real-world datasets using state-of-the-art models demonstrate that our coordinated attack significantly outperforms text-only and image-only baselines. These findings reveal that multimodal synergy, typically a strength of VLMs, can be weaponized to compromise the integrity of search rankings without triggering conventional content filters.
Value-Action Alignment in Large Language Models under Privacy-Prosocial Conflict
Jan 07, 2026Large language models (LLMs) are increasingly used to simulate decision-making tasks involving personal data sharing, where privacy concerns and prosocial motivations can push choices in opposite directions. Existing evaluations often measure privacy-related attitudes or sharing intentions in isolation, which makes it difficult to determine whether a model's expressed values jointly predict its downstream data-sharing actions as in real human behaviors. We introduce a context-based assessment protocol that sequentially administers standardized questionnaires for privacy attitudes, prosocialness, and acceptance of data sharing within a bounded, history-carrying session. To evaluate value-action alignments under competing attitudes, we use multi-group structural equation modeling (MGSEM) to identify relations from privacy concerns and prosocialness to data sharing. We propose Value-Action Alignment Rate (VAAR), a human-referenced directional agreement metric that aggregates path-level evidence for expected signs. Across multiple LLMs, we observe stable but model-specific Privacy-PSA-AoDS profiles, and substantial heterogeneity in value-action alignment.
A Personalized Conversational Benchmark: Towards Simulating Personalized Conversations
May 20, 2025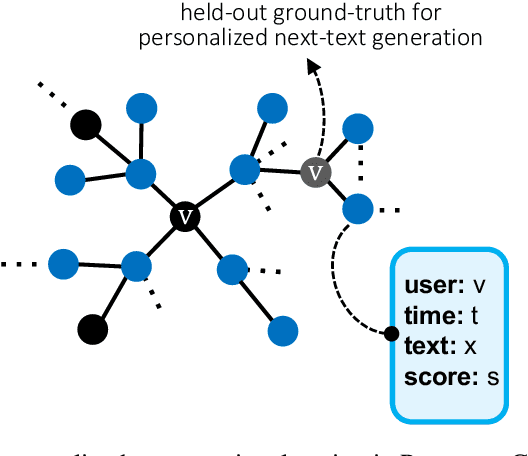
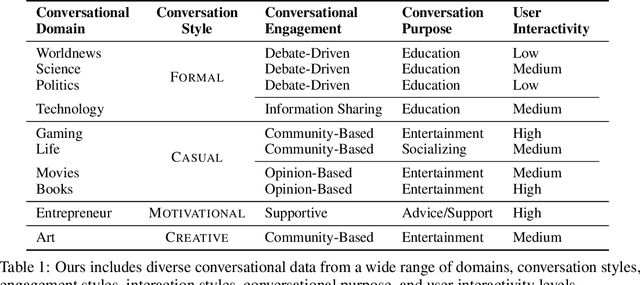
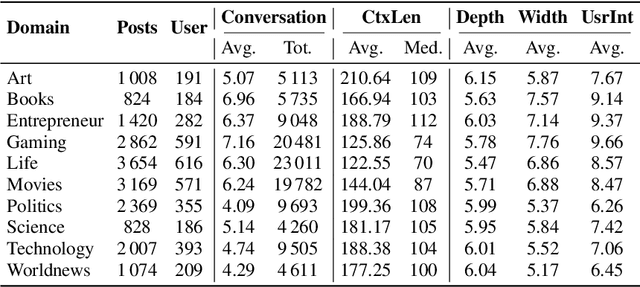
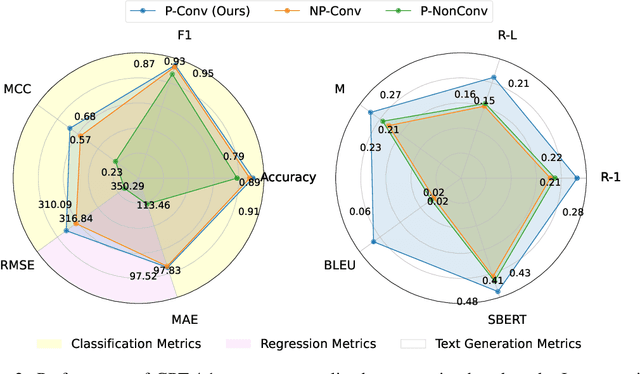
We present PersonaConvBench, a large-scale benchmark for evaluating personalized reasoning and generation in multi-turn conversations with large language models (LLMs). Unlike existing work that focuses on either personalization or conversational structure in isolation, PersonaConvBench integrates both, offering three core tasks: sentence classification, impact regression, and user-centric text generation across ten diverse Reddit-based domains. This design enables systematic analysis of how personalized conversational context shapes LLM outputs in realistic multi-user scenarios. We benchmark several commercial and open-source LLMs under a unified prompting setup and observe that incorporating personalized history yields substantial performance improvements, including a 198 percent relative gain over the best non-conversational baseline in sentiment classification. By releasing PersonaConvBench with evaluations and code, we aim to support research on LLMs that adapt to individual styles, track long-term context, and produce contextually rich, engaging responses.
AD-AGENT: A Multi-agent Framework for End-to-end Anomaly Detection
May 19, 2025

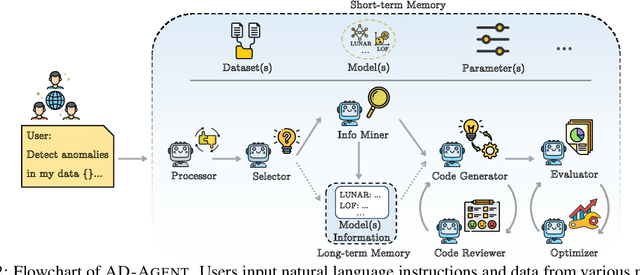

Anomaly detection (AD) is essential in areas such as fraud detection, network monitoring, and scientific research. However, the diversity of data modalities and the increasing number of specialized AD libraries pose challenges for non-expert users who lack in-depth library-specific knowledge and advanced programming skills. To tackle this, we present AD-AGENT, an LLM-driven multi-agent framework that turns natural-language instructions into fully executable AD pipelines. AD-AGENT coordinates specialized agents for intent parsing, data preparation, library and model selection, documentation mining, and iterative code generation and debugging. Using a shared short-term workspace and a long-term cache, the agents integrate popular AD libraries like PyOD, PyGOD, and TSLib into a unified workflow. Experiments demonstrate that AD-AGENT produces reliable scripts and recommends competitive models across libraries. The system is open-sourced to support further research and practical applications in AD.
Graph Synthetic Out-of-Distribution Exposure with Large Language Models
Apr 29, 2025



Out-of-distribution (OOD) detection in graphs is critical for ensuring model robustness in open-world and safety-sensitive applications. Existing approaches to graph OOD detection typically involve training an in-distribution (ID) classifier using only ID data, followed by the application of post-hoc OOD scoring techniques. Although OOD exposure - introducing auxiliary OOD samples during training - has proven to be an effective strategy for enhancing detection performance, current methods in the graph domain generally assume access to a set of real OOD nodes. This assumption, however, is often impractical due to the difficulty and cost of acquiring representative OOD samples. In this paper, we introduce GOE-LLM, a novel framework that leverages Large Language Models (LLMs) for OOD exposure in graph OOD detection without requiring real OOD nodes. GOE-LLM introduces two pipelines: (1) identifying pseudo-OOD nodes from the initially unlabeled graph using zero-shot LLM annotations, and (2) generating semantically informative synthetic OOD nodes via LLM-prompted text generation. These pseudo-OOD nodes are then used to regularize the training of the ID classifier for improved OOD awareness. We evaluate our approach across multiple benchmark datasets, showing that GOE-LLM significantly outperforms state-of-the-art graph OOD detection methods that do not use OOD exposure and achieves comparable performance to those relying on real OOD data.
StealthRank: LLM Ranking Manipulation via Stealthy Prompt Optimization
Apr 08, 2025
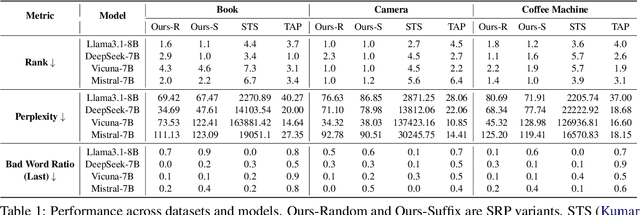


The integration of large language models (LLMs) into information retrieval systems introduces new attack surfaces, particularly for adversarial ranking manipulations. We present StealthRank, a novel adversarial ranking attack that manipulates LLM-driven product recommendation systems while maintaining textual fluency and stealth. Unlike existing methods that often introduce detectable anomalies, StealthRank employs an energy-based optimization framework combined with Langevin dynamics to generate StealthRank Prompts (SRPs)-adversarial text sequences embedded within product descriptions that subtly yet effectively influence LLM ranking mechanisms. We evaluate StealthRank across multiple LLMs, demonstrating its ability to covertly boost the ranking of target products while avoiding explicit manipulation traces that can be easily detected. Our results show that StealthRank consistently outperforms state-of-the-art adversarial ranking baselines in both effectiveness and stealth, highlighting critical vulnerabilities in LLM-driven recommendation systems.
Generative AI in Transportation Planning: A Survey
Mar 10, 2025

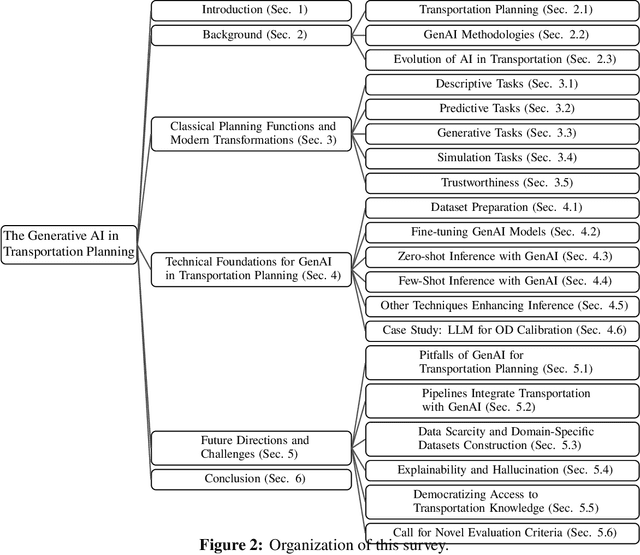
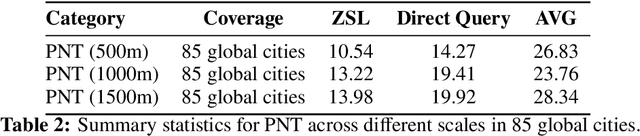
The integration of generative artificial intelligence (GenAI) into transportation planning has the potential to revolutionize tasks such as demand forecasting, infrastructure design, policy evaluation, and traffic simulation. However, there is a critical need for a systematic framework to guide the adoption of GenAI in this interdisciplinary domain. In this survey, we, a multidisciplinary team of researchers spanning computer science and transportation engineering, present the first comprehensive framework for leveraging GenAI in transportation planning. Specifically, we introduce a new taxonomy that categorizes existing applications and methodologies into two perspectives: transportation planning tasks and computational techniques. From the transportation planning perspective, we examine the role of GenAI in automating descriptive, predictive, generative, simulation, and explainable tasks to enhance mobility systems. From the computational perspective, we detail advancements in data preparation, domain-specific fine-tuning, and inference strategies, such as retrieval-augmented generation and zero-shot learning tailored to transportation applications. Additionally, we address critical challenges, including data scarcity, explainability, bias mitigation, and the development of domain-specific evaluation frameworks that align with transportation goals like sustainability, equity, and system efficiency. This survey aims to bridge the gap between traditional transportation planning methodologies and modern AI techniques, fostering collaboration and innovation. By addressing these challenges and opportunities, we seek to inspire future research that ensures ethical, equitable, and impactful use of generative AI in transportation planning.
Secure On-Device Video OOD Detection Without Backpropagation
Mar 08, 2025Out-of-Distribution (OOD) detection is critical for ensuring the reliability of machine learning models in safety-critical applications such as autonomous driving and medical diagnosis. While deploying personalized OOD detection directly on edge devices is desirable, it remains challenging due to large model sizes and the computational infeasibility of on-device training. Federated learning partially addresses this but still requires gradient computation and backpropagation, exceeding the capabilities of many edge devices. To overcome these challenges, we propose SecDOOD, a secure cloud-device collaboration framework for efficient on-device OOD detection without requiring device-side backpropagation. SecDOOD utilizes cloud resources for model training while ensuring user data privacy by retaining sensitive information on-device. Central to SecDOOD is a HyperNetwork-based personalized parameter generation module, which adapts cloud-trained models to device-specific distributions by dynamically generating local weight adjustments, effectively combining central and local information without local fine-tuning. Additionally, our dynamic feature sampling and encryption strategy selectively encrypts only the most informative feature channels, largely reducing encryption overhead without compromising detection performance. Extensive experiments across multiple datasets and OOD scenarios demonstrate that SecDOOD achieves performance comparable to fully fine-tuned models, enabling secure, efficient, and personalized OOD detection on resource-limited edge devices. To enhance accessibility and reproducibility, our code is publicly available at https://github.com/Dystopians/SecDOOD.