 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeCo-DETR: Decoupled Cognition DETR for efficient Open-Vocabulary Object Detection
Apr 03, 2026Open-vocabulary Object Detection (OVOD) enables models to recognize objects beyond predefined categories, but existing approaches remain limited in practical deployment. On the one hand, multimodal designs often incur substantial computational overhead due to their reliance on text encoders at inference time. On the other hand, tightly coupled training objectives introduce a trade-off between closed-set detection accuracy and open-world generalization. Thus, we propose Decoupled Cognition DETR (DeCo-DETR), a vision-centric framework that addresses these challenges through a unified decoupling paradigm. Instead of depending on online text encoding, DeCo-DETR constructs a hierarchical semantic prototype space from region-level descriptions generated by pre-trained LVLMs and aligned via CLIP, enabling efficient and reusable semantic representation. Building upon this representation, the framework further disentangles semantic reasoning from localization through a decoupled training strategy, which separates alignment and detection into parallel optimization streams. Extensive experiments on standard OVOD benchmarks demonstrate that DeCo-DETR achieves competitive zero-shot detection performance while significantly improving inference efficiency. These results highlight the effectiveness of decoupling semantic cognition from detection, offering a practical direction for scalable OVOD systems.
CME-CAD: Heterogeneous Collaborative Multi-Expert Reinforcement Learning for CAD Code Generation
Dec 29, 2025Computer-Aided Design (CAD) is essential in industrial design, but the complexity of traditional CAD modeling and workflows presents significant challenges for automating the generation of high-precision, editable CAD models. Existing methods that reconstruct 3D models from sketches often produce non-editable and approximate models that fall short of meeting the stringent requirements for precision and editability in industrial design. Moreover, the reliance on text or image-based inputs often requires significant manual annotation, limiting their scalability and applicability in industrial settings. To overcome these challenges, we propose the Heterogeneous Collaborative Multi-Expert Reinforcement Learning (CME-CAD) paradigm, a novel training paradigm for CAD code generation. Our approach integrates the complementary strengths of these models, facilitating collaborative learning and improving the model's ability to generate accurate, constraint-compatible, and fully editable CAD models. We introduce a two-stage training process: Multi-Expert Fine-Tuning (MEFT), and Multi-Expert Reinforcement Learning (MERL). Additionally, we present CADExpert, an open-source benchmark consisting of 17,299 instances, including orthographic projections with precise dimension annotations, expert-generated Chain-of-Thought (CoT) processes, executable CADQuery code, and rendered 3D models.
A Systematic Study of Model Extraction Attacks on Graph Foundation Models
Nov 14, 2025Graph machine learning has advanced rapidly in tasks such as link prediction, anomaly detection, and node classification. As models scale up, pretrained graph models have become valuable intellectual assets because they encode extensive computation and domain expertise. Building on these advances, Graph Foundation Models (GFMs) mark a major step forward by jointly pretraining graph and text encoders on massive and diverse data. This unifies structural and semantic understanding, enables zero-shot inference, and supports applications such as fraud detection and biomedical analysis. However, the high pretraining cost and broad cross-domain knowledge in GFMs also make them attractive targets for model extraction attacks (MEAs). Prior work has focused only on small graph neural networks trained on a single graph, leaving the security implications for large-scale and multimodal GFMs largely unexplored. This paper presents the first systematic study of MEAs against GFMs. We formalize a black-box threat model and define six practical attack scenarios covering domain-level and graph-specific extraction goals, architectural mismatch, limited query budgets, partial node access, and training data discrepancies. To instantiate these attacks, we introduce a lightweight extraction method that trains an attacker encoder using supervised regression of graph embeddings. Even without contrastive pretraining data, this method learns an encoder that stays aligned with the victim text encoder and preserves its zero-shot inference ability on unseen graphs. Experiments on seven datasets show that the attacker can approximate the victim model using only a tiny fraction of its original training cost, with almost no loss in accuracy. These findings reveal that GFMs greatly expand the MEA surface and highlight the need for deployment-aware security defenses in large-scale graph learning systems.
Graph Synthetic Out-of-Distribution Exposure with Large Language Models
Apr 29, 2025



Out-of-distribution (OOD) detection in graphs is critical for ensuring model robustness in open-world and safety-sensitive applications. Existing approaches to graph OOD detection typically involve training an in-distribution (ID) classifier using only ID data, followed by the application of post-hoc OOD scoring techniques. Although OOD exposure - introducing auxiliary OOD samples during training - has proven to be an effective strategy for enhancing detection performance, current methods in the graph domain generally assume access to a set of real OOD nodes. This assumption, however, is often impractical due to the difficulty and cost of acquiring representative OOD samples. In this paper, we introduce GOE-LLM, a novel framework that leverages Large Language Models (LLMs) for OOD exposure in graph OOD detection without requiring real OOD nodes. GOE-LLM introduces two pipelines: (1) identifying pseudo-OOD nodes from the initially unlabeled graph using zero-shot LLM annotations, and (2) generating semantically informative synthetic OOD nodes via LLM-prompted text generation. These pseudo-OOD nodes are then used to regularize the training of the ID classifier for improved OOD awareness. We evaluate our approach across multiple benchmark datasets, showing that GOE-LLM significantly outperforms state-of-the-art graph OOD detection methods that do not use OOD exposure and achieves comparable performance to those relying on real OOD data.
GLIP-OOD: Zero-Shot Graph OOD Detection with Foundation Model
Apr 29, 2025



Out-of-distribution (OOD) detection is critical for ensuring the safety and reliability of machine learning systems, particularly in dynamic and open-world environments. In the vision and text domains, zero-shot OOD detection - which requires no training on in-distribution (ID) data - has made significant progress through the use of large-scale pretrained models such as vision-language models (VLMs) and large language models (LLMs). However, zero-shot OOD detection in graph-structured data remains largely unexplored, primarily due to the challenges posed by complex relational structures and the absence of powerful, large-scale pretrained models for graphs. In this work, we take the first step toward enabling zero-shot graph OOD detection by leveraging a graph foundation model (GFM). We show that, when provided only with class label names, the GFM can perform OOD detection without any node-level supervision - outperforming existing supervised methods across multiple datasets. To address the more practical setting where OOD label names are unavailable, we introduce GLIP-OOD, a novel framework that employs LLMs to generate semantically informative pseudo-OOD labels from unlabeled data. These labels enable the GFM to capture nuanced semantic boundaries between ID and OOD classes and perform fine-grained OOD detection - without requiring any labeled nodes. Our approach is the first to enable node-level graph OOD detection in a fully zero-shot setting, and achieves state-of-the-art performance on four benchmark text-attributed graph datasets.
Few-Shot Graph Out-of-Distribution Detection with LLMs
Mar 28, 2025Existing methods for graph out-of-distribution (OOD) detection typically depend on training graph neural network (GNN) classifiers using a substantial amount of labeled in-distribution (ID) data. However, acquiring high-quality labeled nodes in text-attributed graphs (TAGs) is challenging and costly due to their complex textual and structural characteristics. Large language models (LLMs), known for their powerful zero-shot capabilities in textual tasks, show promise but struggle to naturally capture the critical structural information inherent to TAGs, limiting their direct effectiveness. To address these challenges, we propose LLM-GOOD, a general framework that effectively combines the strengths of LLMs and GNNs to enhance data efficiency in graph OOD detection. Specifically, we first leverage LLMs' strong zero-shot capabilities to filter out likely OOD nodes, significantly reducing the human annotation burden. To minimize the usage and cost of the LLM, we employ it only to annotate a small subset of unlabeled nodes. We then train a lightweight GNN filter using these noisy labels, enabling efficient predictions of ID status for all other unlabeled nodes by leveraging both textual and structural information. After obtaining node embeddings from the GNN filter, we can apply informativeness-based methods to select the most valuable nodes for precise human annotation. Finally, we train the target ID classifier using these accurately annotated ID nodes. Extensive experiments on four real-world TAG datasets demonstrate that LLM-GOOD significantly reduces human annotation costs and outperforms state-of-the-art baselines in terms of both ID classification accuracy and OOD detection performance.
LEGO-Learn: Label-Efficient Graph Open-Set Learning
Oct 21, 2024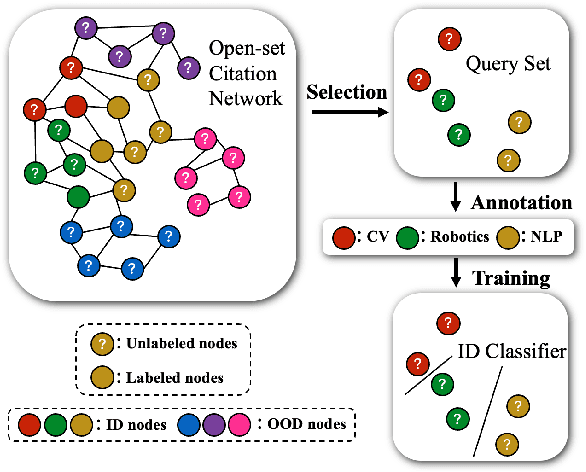
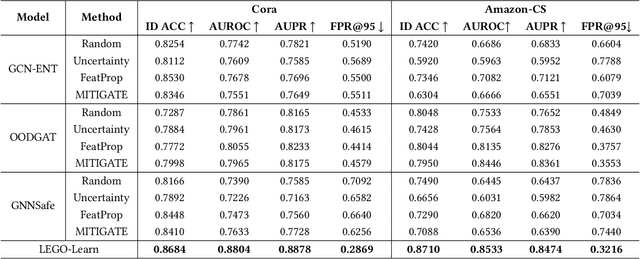
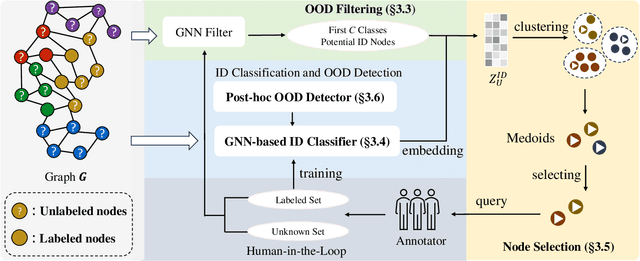
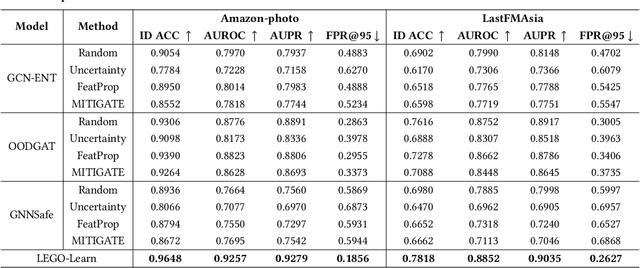
How can we train graph-based models to recognize unseen classes while keeping labeling costs low? Graph open-set learning (GOL) and out-of-distribution (OOD) detection aim to address this challenge by training models that can accurately classify known, in-distribution (ID) classes while identifying and handling previously unseen classes during inference. It is critical for high-stakes, real-world applications where models frequently encounter unexpected data, including finance, security, and healthcare. However, current GOL methods assume access to many labeled ID samples, which is unrealistic for large-scale graphs due to high annotation costs. In this paper, we propose LEGO-Learn (Label-Efficient Graph Open-set Learning), a novel framework that tackles open-set node classification on graphs within a given label budget by selecting the most informative ID nodes. LEGO-Learn employs a GNN-based filter to identify and exclude potential OOD nodes and then select highly informative ID nodes for labeling using the K-Medoids algorithm. To prevent the filter from discarding valuable ID examples, we introduce a classifier that differentiates between the C known ID classes and an additional class representing OOD nodes (hence, a C+1 classifier). This classifier uses a weighted cross-entropy loss to balance the removal of OOD nodes while retaining informative ID nodes. Experimental results on four real-world datasets demonstrate that LEGO-Learn significantly outperforms leading methods, with up to a 6.62% improvement in ID classification accuracy and a 7.49% increase in AUROC for OOD detection.
Task-Agnostic Federated Learning
Jun 25, 2024In the realm of medical imaging, leveraging large-scale datasets from various institutions is crucial for developing precise deep learning models, yet privacy concerns frequently impede data sharing. federated learning (FL) emerges as a prominent solution for preserving privacy while facilitating collaborative learning. However, its application in real-world scenarios faces several obstacles, such as task & data heterogeneity, label scarcity, non-identically distributed (non-IID) data, computational vaiation, etc. In real-world, medical institutions may not want to disclose their tasks to FL server and generalization challenge of out-of-network institutions with un-seen task want to join the on-going federated system. This study address task-agnostic and generalization problem on un-seen tasks by adapting self-supervised FL framework. Utilizing Vision Transformer (ViT) as consensus feature encoder for self-supervised pre-training, no initial labels required, the framework enabling effective representation learning across diverse datasets and tasks. Our extensive evaluations, using various real-world non-IID medical imaging datasets, validate our approach's efficacy, retaining 90\% of F1 accuracy with only 5\% of the training data typically required for centralized approaches and exhibiting superior adaptability to out-of-distribution task. The result indicate that federated learning architecture can be a potential approach toward multi-task foundation modeling.