 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEGO-Learn: Label-Efficient Graph Open-Set Learning
Paper and Code
Oct 21, 2024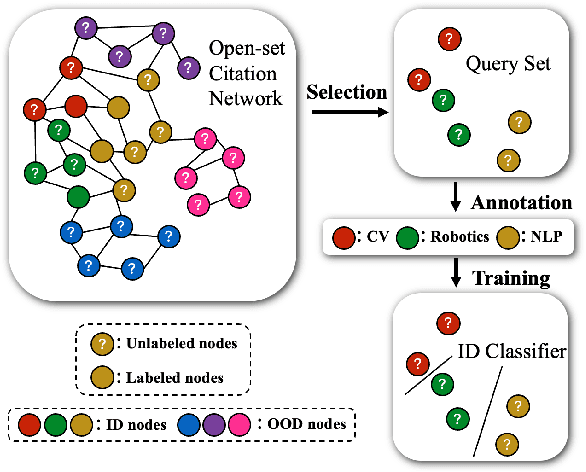
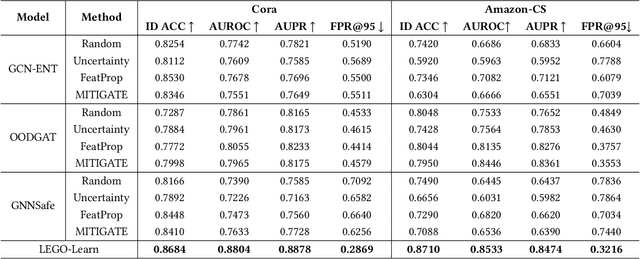
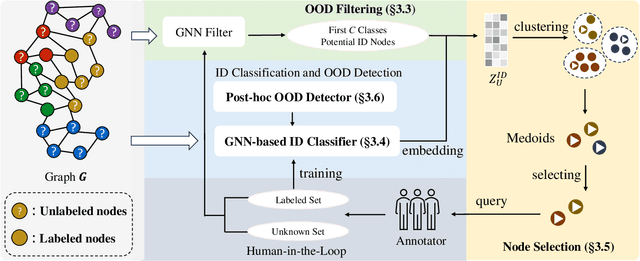
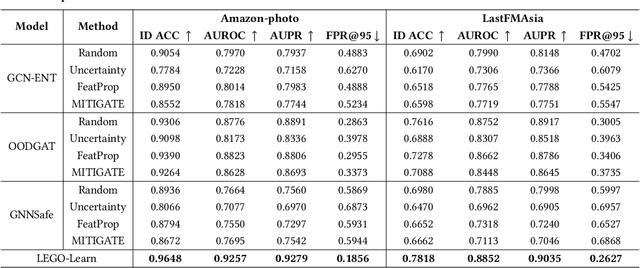
How can we train graph-based models to recognize unseen classes while keeping labeling costs low? Graph open-set learning (GOL) and out-of-distribution (OOD) detection aim to address this challenge by training models that can accurately classify known, in-distribution (ID) classes while identifying and handling previously unseen classes during inference. It is critical for high-stakes, real-world applications where models frequently encounter unexpected data, including finance, security, and healthcare. However, current GOL methods assume access to many labeled ID samples, which is unrealistic for large-scale graphs due to high annotation costs. In this paper, we propose LEGO-Learn (Label-Efficient Graph Open-set Learning), a novel framework that tackles open-set node classification on graphs within a given label budget by selecting the most informative ID nodes. LEGO-Learn employs a GNN-based filter to identify and exclude potential OOD nodes and then select highly informative ID nodes for labeling using the K-Medoids algorithm. To prevent the filter from discarding valuable ID examples, we introduce a classifier that differentiates between the C known ID classes and an additional class representing OOD nodes (hence, a C+1 classifier). This classifier uses a weighted cross-entropy loss to balance the removal of OOD nodes while retaining informative ID nodes. Experimental results on four real-world datasets demonstrate that LEGO-Learn significantly outperforms leading methods, with up to a 6.62% improvement in ID classification accuracy and a 7.49% increase in AUROC for OOD detection.