 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIG to Heal: Scaling General-purpose Agent Collaboration via Explainable Dynamic Decision Paths
Feb 27, 2026The increasingly popular agentic AI paradigm promises to harness the power of multiple, general-purpose large language model (LLM) agents to collaboratively complete complex tasks. While many agentic AI systems utilize predefined workflows or agent roles in order to reduce complexity, ideally these agents would be truly autonomous, able to achieve emergent collaboration even as the number of collaborating agents increases. Yet in practice, such unstructured interactions can lead to redundant work and cascading failures that are difficult to interpret or correct. In this work, we study multi-agent systems composed of general-purpose LLM agents that operate without predefined roles, control flow, or communication constraints, relying instead on emergent collaboration to solve problems. We introduce the Dynamic Interaction Graph (DIG), which captures emergent collaboration as a time-evolving causal network of agent activations and interactions. DIG makes emergent collaboration observable and explainable for the first time, enabling real-time identification, explanation, and correction of collaboration-induced error patterns directly from agents' collaboration paths. Thus, DIG fills a critical gap in understanding how general LLM agents solve problems together in truly agentic multi-agent systems. The project webpage can be found at: https://happyeureka.github.io/dig.
TestNUC: Enhancing Test-Time Computing Approaches through Neighboring Unlabeled Data Consistency
Feb 26, 2025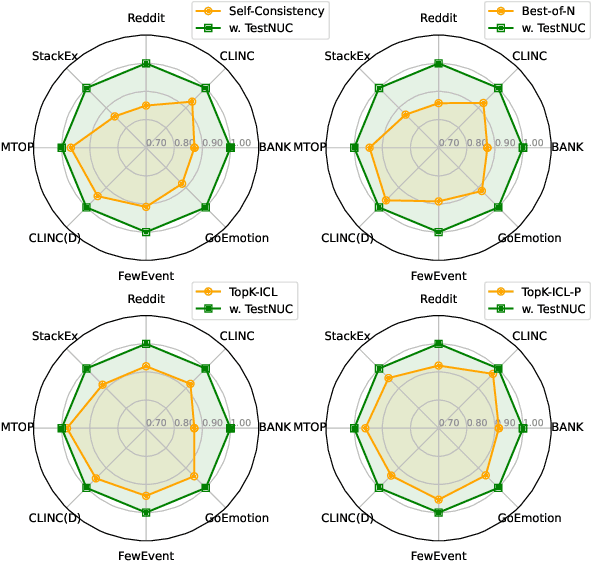
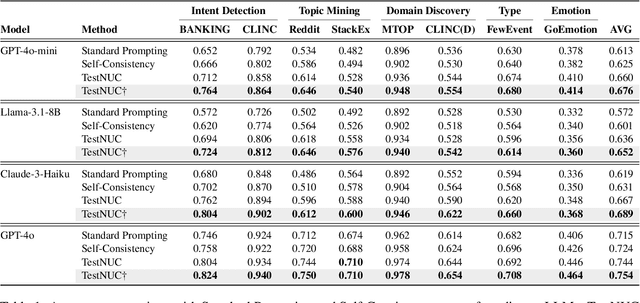
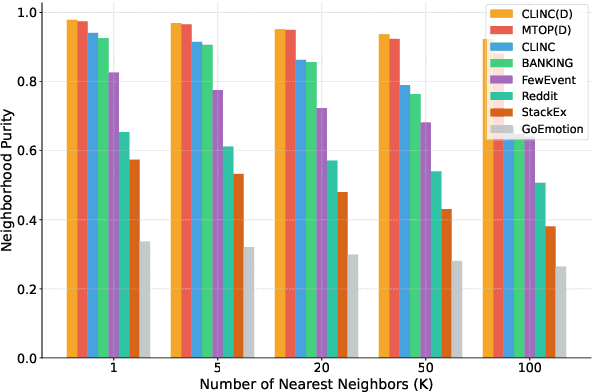
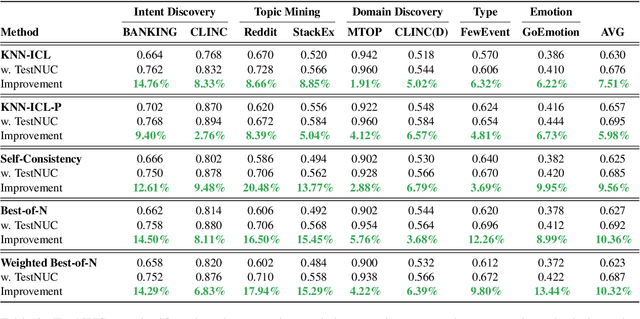
Test-time computing approaches, which leverage additional computational resources during inference, have been proven effective in enhancing large language model performance. This work introduces a novel, linearly scaling approach, TestNUC, that improves test-time predictions by leveraging the local consistency of neighboring unlabeled data-it classifies an input instance by considering not only the model's prediction on that instance but also on neighboring unlabeled instances. We evaluate TestNUC across eight diverse datasets, spanning intent classification, topic mining, domain discovery, and emotion detection, demonstrating its consistent superiority over baseline methods such as standard prompting and self-consistency. Furthermore, TestNUC can be seamlessly integrated with existing test-time computing approaches, substantially boosting their performance. Our analysis reveals that TestNUC scales effectively with increasing amounts of unlabeled data and performs robustly across different embedding models, making it practical for real-world applications. Our code is available at https://github.com/HenryPengZou/TestNUC.
TGTOD: A Global Temporal Graph Transformer for Outlier Detection at Scale
Dec 01, 2024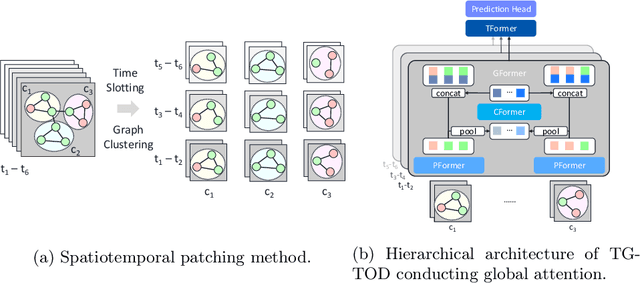
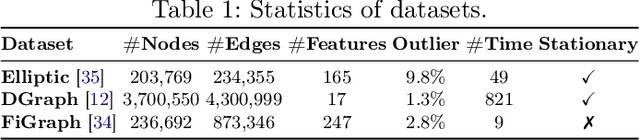
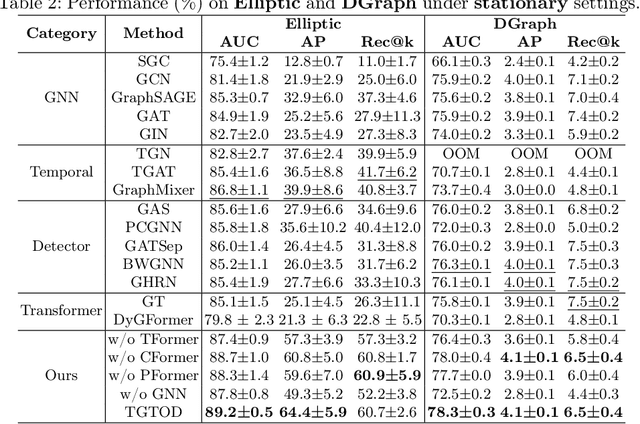
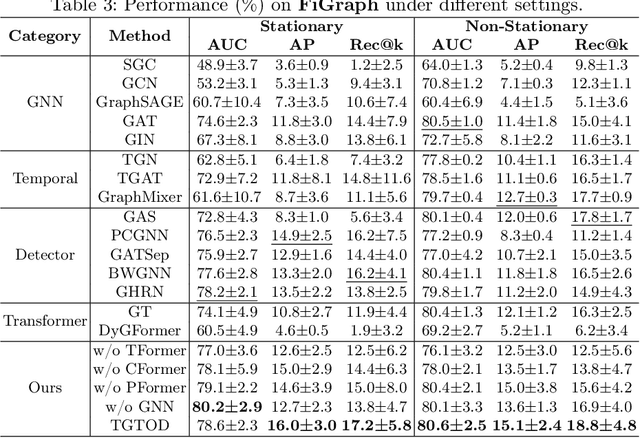
While Transformers have revolutionized machine learning on various data, existing Transformers for temporal graphs face limitations in (1) restricted receptive fields, (2) overhead of subgraph extraction, and (3) suboptimal generalization capability beyond link prediction. In this paper, we rethink temporal graph Transformers and propose TGTOD, a novel end-to-end Temporal Graph Transformer for Outlier Detection. TGTOD employs global attention to model both structural and temporal dependencies within temporal graphs. To tackle scalability, our approach divides large temporal graphs into spatiotemporal patches, which are then processed by a hierarchical Transformer architecture comprising Patch Transformer, Cluster Transformer, and Temporal Transformer. We evaluate TGTOD on three public datasets under two settings, comparing with a wide range of baselines. Our experimental results demonstrate the effectiveness of TGTOD, achieving AP improvement of 61% on Elliptic. Furthermore, our efficiency evaluation shows that TGTOD reduces training time by 44x compared to existing Transformers for temporal graphs. To foster reproducibility, we make our implementation publicly available at https://github.com/kayzliu/tgtod.
LEGO-Learn: Label-Efficient Graph Open-Set Learning
Oct 21, 2024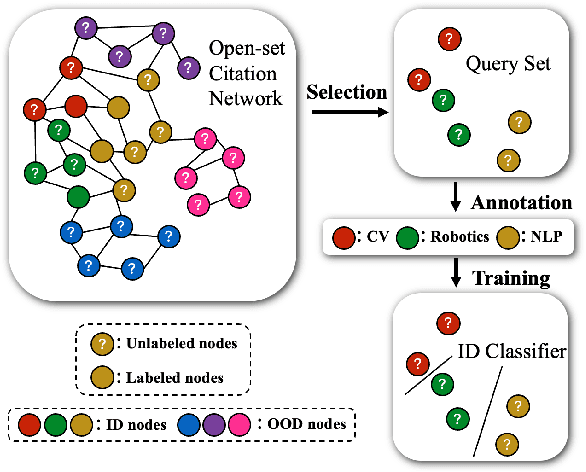
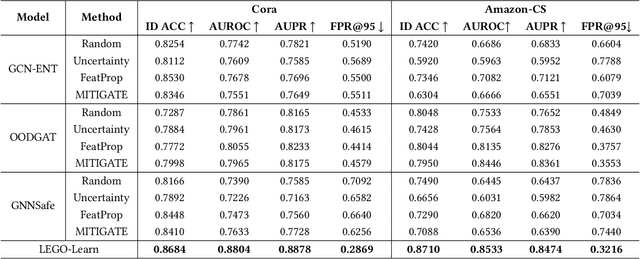
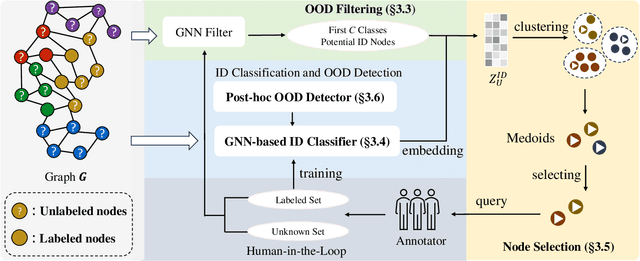
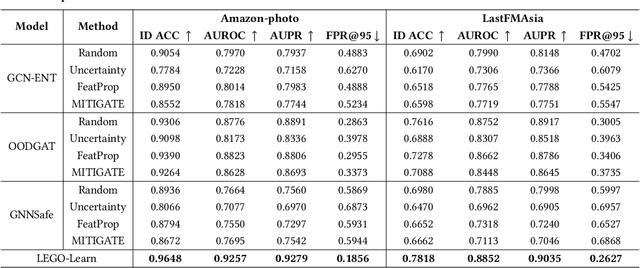
How can we train graph-based models to recognize unseen classes while keeping labeling costs low? Graph open-set learning (GOL) and out-of-distribution (OOD) detection aim to address this challenge by training models that can accurately classify known, in-distribution (ID) classes while identifying and handling previously unseen classes during inference. It is critical for high-stakes, real-world applications where models frequently encounter unexpected data, including finance, security, and healthcare. However, current GOL methods assume access to many labeled ID samples, which is unrealistic for large-scale graphs due to high annotation costs. In this paper, we propose LEGO-Learn (Label-Efficient Graph Open-set Learning), a novel framework that tackles open-set node classification on graphs within a given label budget by selecting the most informative ID nodes. LEGO-Learn employs a GNN-based filter to identify and exclude potential OOD nodes and then select highly informative ID nodes for labeling using the K-Medoids algorithm. To prevent the filter from discarding valuable ID examples, we introduce a classifier that differentiates between the C known ID classes and an additional class representing OOD nodes (hence, a C+1 classifier). This classifier uses a weighted cross-entropy loss to balance the removal of OOD nodes while retaining informative ID nodes. Experimental results on four real-world datasets demonstrate that LEGO-Learn significantly outperforms leading methods, with up to a 6.62% improvement in ID classification accuracy and a 7.49% increase in AUROC for OOD detection.
BANGS: Game-Theoretic Node Selection for Graph Self-Training
Oct 12, 2024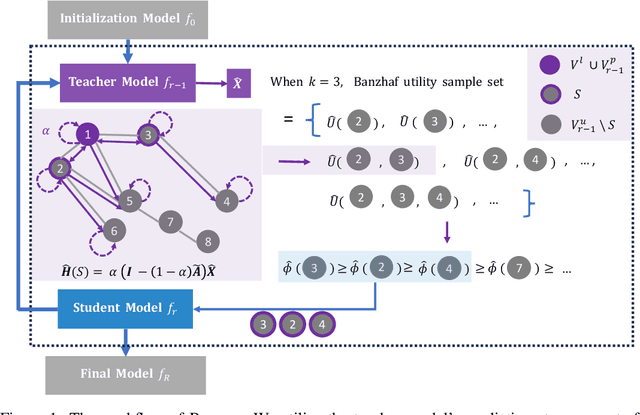
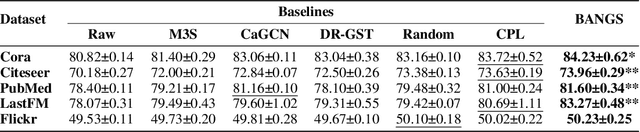

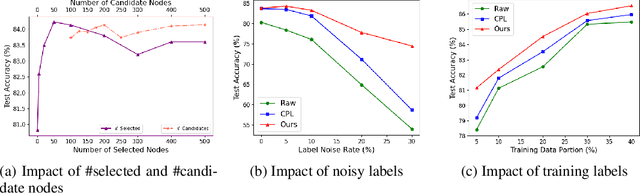
Graph self-training is a semi-supervised learning method that iteratively selects a set of unlabeled data to retrain the underlying graph neural network (GNN) model and improve its prediction performance. While selecting highly confident nodes has proven effective for self-training, this pseudo-labeling strategy ignores the combinatorial dependencies between nodes and suffers from a local view of the distribution. To overcome these issues, we propose BANGS, a novel framework that unifies the labeling strategy with conditional mutual information as the objective of node selection. Our approach -- grounded in game theory -- selects nodes in a combinatorial fashion and provides theoretical guarantees for robustness under noisy objective. More specifically, unlike traditional methods that rank and select nodes independently, BANGS considers nodes as a collective set in the self-training process. Our method demonstrates superior performance and robustness across various datasets, base models, and hyperparameter settings, outperforming existing techniques. The codebase is available on https://github.com/fangxin-wang/BANGS .
FedGraph: A Research Library and Benchmark for Federated Graph Learning
Oct 08, 2024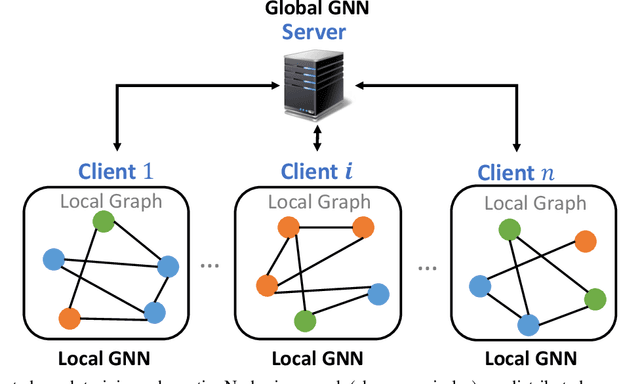
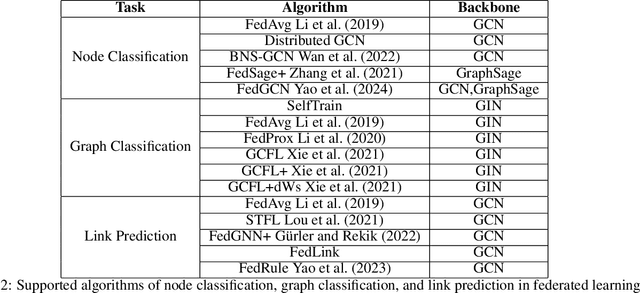
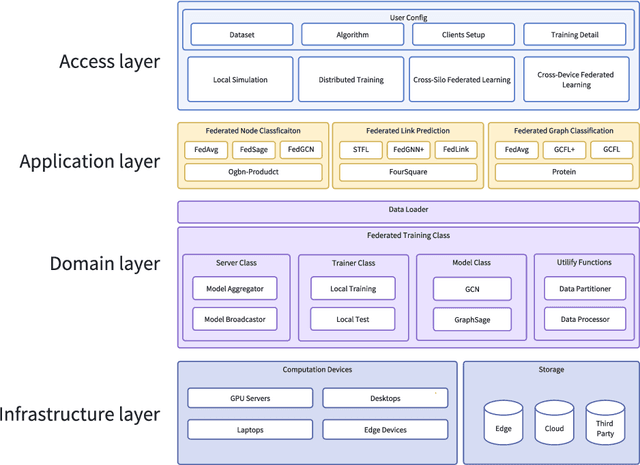
Federated graph learning is an emerging field with significant practical challenges. While many algorithms have been proposed to enhance model accuracy, their system performance, crucial for real-world deployment, is often overlooked. To address this gap, we present FedGraph, a research library designed for practical distributed deployment and benchmarking in federated graph learning. FedGraph supports a range of state-of-the-art methods and includes profiling tools for system performance evaluation, focusing on communication and computation costs during training. FedGraph can then facilitate the development of practical applications and guide the design of future algorithms.
Enhancing Fairness in Unsupervised Graph Anomaly Detection through Disentanglement
Jun 03, 2024



Graph anomaly detection (GAD) is increasingly crucial in various applications, ranging from financial fraud detection to fake news detection. However, current GAD methods largely overlook the fairness problem, which might result in discriminatory decisions skewed toward certain demographic groups defined on sensitive attributes (e.g., gender, religion, ethnicity, etc.). This greatly limits the applicability of these methods in real-world scenarios in light of societal and ethical restrictions. To address this critical gap, we make the first attempt to integrate fairness with utility in GAD decision-making. Specifically, we devise a novel DisEntangle-based FairnEss-aware aNomaly Detection framework on the attributed graph, named DEFEND. DEFEND first introduces disentanglement in GNNs to capture informative yet sensitive-irrelevant node representations, effectively reducing societal bias inherent in graph representation learning. Besides, to alleviate discriminatory bias in evaluating anomalous nodes, DEFEND adopts a reconstruction-based anomaly detection, which concentrates solely on node attributes without incorporating any graph structure. Additionally, given the inherent association between input and sensitive attributes, DEFEND constrains the correlation between the reconstruction error and the predicted sensitive attributes. Our empirical evaluations on real-world datasets reveal that DEFEND performs effectively in GAD and significantly enhances fairness compared to state-of-the-art baselines. To foster reproducibility, our code is available at https://github.com/AhaChang/DEFEND.
Uncertainty in Graph Neural Networks: A Survey
Mar 11, 2024



Graph Neural Networks (GNNs) have been extensively used in various real-world applications. However, the predictive uncertainty of GNNs stemming from diverse sources such as inherent randomness in data and model training errors can lead to unstable and erroneous predictions. Therefore, identifying, quantifying, and utilizing uncertainty are essential to enhance the performance of the model for the downstream tasks as well as the reliability of the GNN predictions. This survey aims to provide a comprehensive overview of the GNNs from the perspective of uncertainty with an emphasis on its integration in graph learning. We compare and summarize existing graph uncertainty theory and methods, alongside the corresponding downstream tasks. Thereby, we bridge the gap between theory and practice, meanwhile connecting different GNN communities. Moreover, our work provides valuable insights into promising directions in this field.
Overcoming Pitfalls in Graph Contrastive Learning Evaluation: Toward Comprehensive Benchmarks
Feb 24, 2024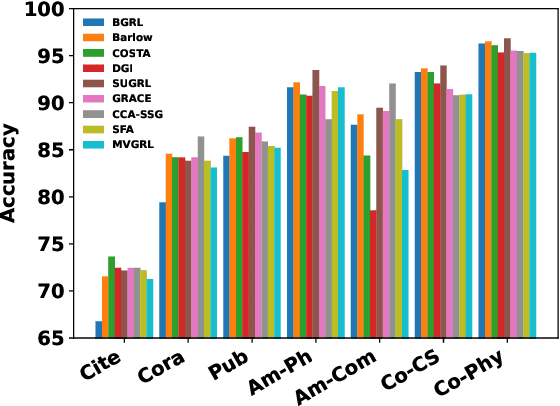
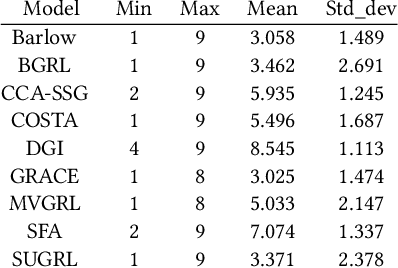
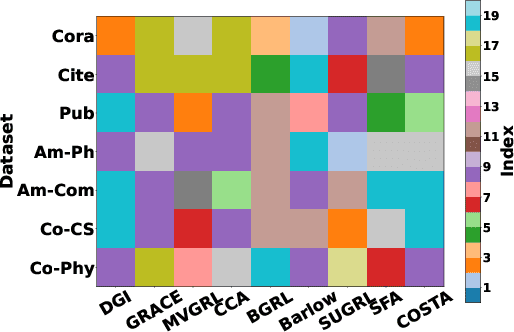
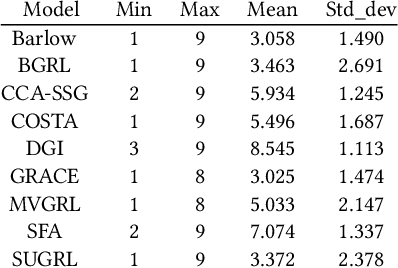
The rise of self-supervised learning, which operates without the need for labeled data, has garnered significant interest within the graph learning community. This enthusiasm has led to the development of numerous Graph Contrastive Learning (GCL) techniques, all aiming to create a versatile graph encoder that leverages the wealth of unlabeled data for various downstream tasks. However, the current evaluation standards for GCL approaches are flawed due to the need for extensive hyper-parameter tuning during pre-training and the reliance on a single downstream task for assessment. These flaws can skew the evaluation away from the intended goals, potentially leading to misleading conclusions. In our paper, we thoroughly examine these shortcomings and offer fresh perspectives on how GCL methods are affected by hyper-parameter choices and the choice of downstream tasks for their evaluation. Additionally, we introduce an enhanced evaluation framework designed to more accurately gauge the effectiveness, consistency, and overall capability of GCL methods.
Confidence-aware Fine-tuning of Sequential Recommendation Systems via Conformal Prediction
Feb 14, 2024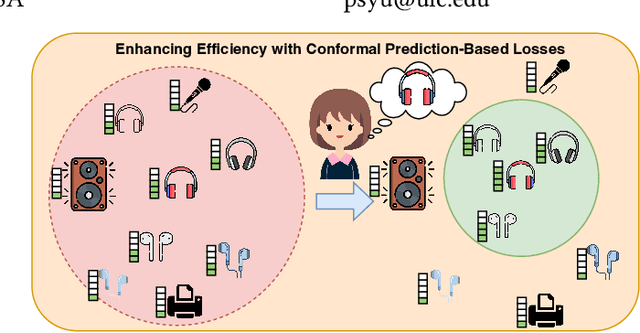
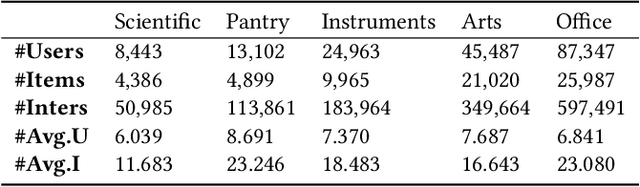
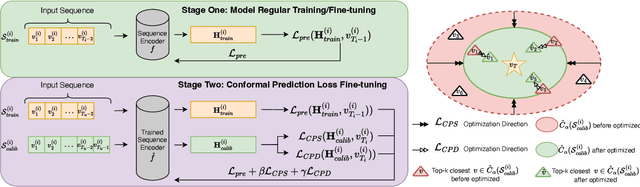

In Sequential Recommendation Systems, Cross-Entropy (CE) loss is commonly used but fails to harness item confidence scores during training. Recognizing the critical role of confidence in aligning training objectives with evaluation metrics, we propose CPFT, a versatile framework that enhances recommendation confidence by integrating Conformal Prediction (CP)-based losses with CE loss during fine-tuning. CPFT dynamically generates a set of items with a high probability of containing the ground truth, enriching the training process by incorporating validation data without compromising its role in model selection. This innovative approach, coupled with CP-based losses, sharpens the focus on refining recommendation sets, thereby elevating the confidence in potential item predictions. By fine-tuning item confidence through CP-based losses, CPFT significantly enhances model performance, leading to more precise and trustworthy recommendations that increase user trust and satisfaction. Our extensive evaluation across five diverse datasets and four distinct sequential models confirms CPFT's substantial impact on improving recommendation quality through strategic confidence optimization. Access to the framework's code will be provided following the acceptance of the paper.