 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Context Probing for Membership Inference in Fine-Tuned Language Models
Dec 21, 2025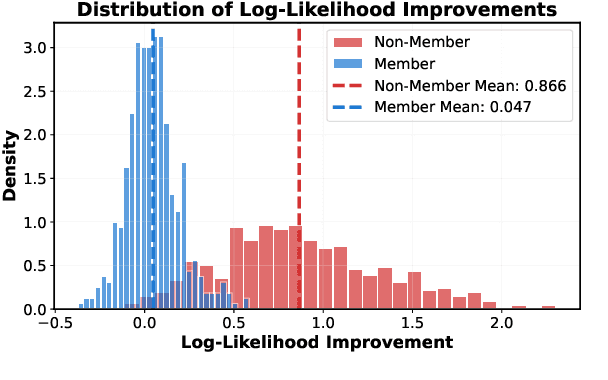
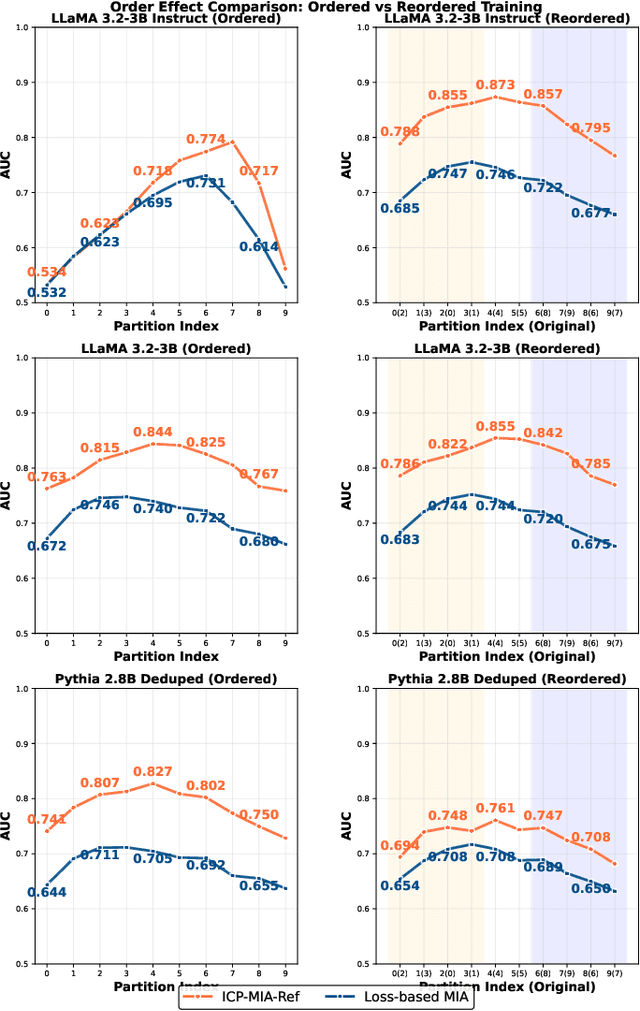
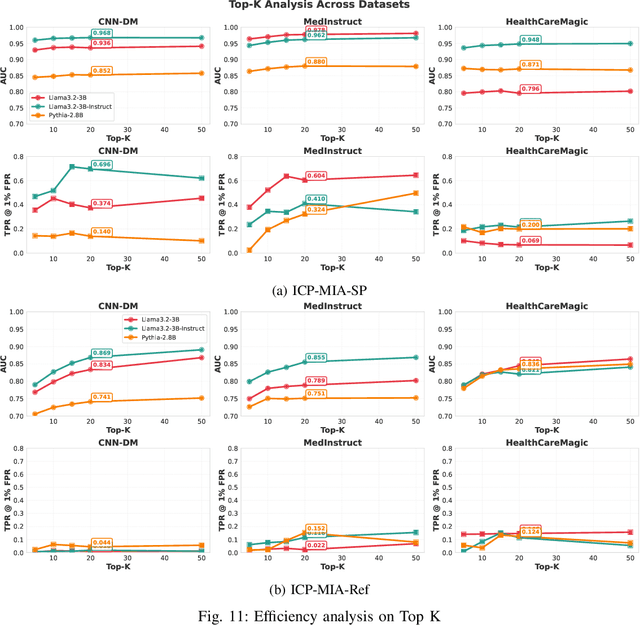
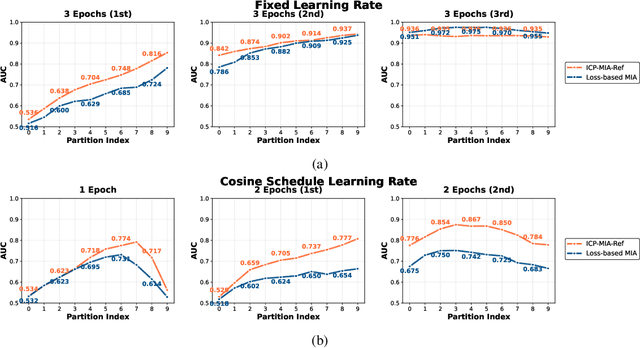
Membership inference attacks (MIAs) pose a critical privacy threat to fine-tuned large language models (LLMs), especially when models are adapted to domain-specific tasks using sensitive data. While prior black-box MIA techniques rely on confidence scores or token likelihoods, these signals are often entangled with a sample's intrinsic properties - such as content difficulty or rarity - leading to poor generalization and low signal-to-noise ratios. In this paper, we propose ICP-MIA, a novel MIA framework grounded in the theory of training dynamics, particularly the phenomenon of diminishing returns during optimization. We introduce the Optimization Gap as a fundamental signal of membership: at convergence, member samples exhibit minimal remaining loss-reduction potential, while non-members retain significant potential for further optimization. To estimate this gap in a black-box setting, we propose In-Context Probing (ICP), a training-free method that simulates fine-tuning-like behavior via strategically constructed input contexts. We propose two probing strategies: reference-data-based (using semantically similar public samples) and self-perturbation (via masking or generation). Experiments on three tasks and multiple LLMs show that ICP-MIA significantly outperforms prior black-box MIAs, particularly at low false positive rates. We further analyze how reference data alignment, model type, PEFT configurations, and training schedules affect attack effectiveness. Our findings establish ICP-MIA as a practical and theoretically grounded framework for auditing privacy risks in deployed LLMs.
Diagnosing and Addressing Pitfalls in KG-RAG Datasets: Toward More Reliable Benchmarking
May 29, 2025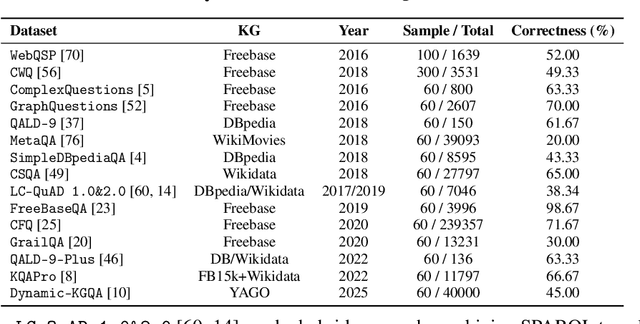
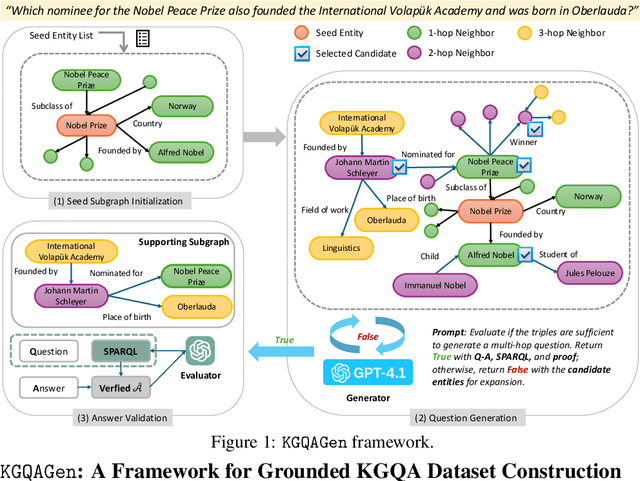

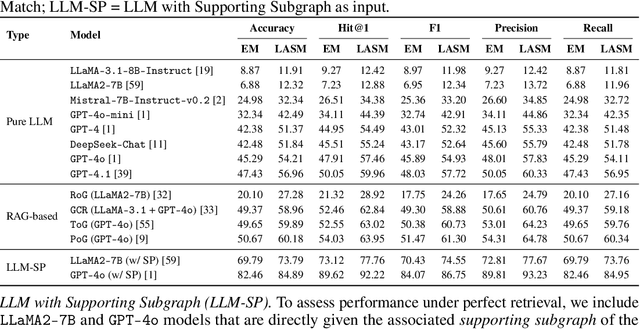
Knowledge Graph Question Answering (KGQA) systems rely on high-quality benchmarks to evaluate complex multi-hop reasoning. However, despite their widespread use, popular datasets such as WebQSP and CWQ suffer from critical quality issues, including inaccurate or incomplete ground-truth annotations, poorly constructed questions that are ambiguous, trivial, or unanswerable, and outdated or inconsistent knowledge. Through a manual audit of 16 popular KGQA datasets, including WebQSP and CWQ, we find that the average factual correctness rate is only 57 %. To address these issues, we introduce KGQAGen, an LLM-in-the-loop framework that systematically resolves these pitfalls. KGQAGen combines structured knowledge grounding, LLM-guided generation, and symbolic verification to produce challenging and verifiable QA instances. Using KGQAGen, we construct KGQAGen-10k, a ten-thousand scale benchmark grounded in Wikidata, and evaluate a diverse set of KG-RAG models. Experimental results demonstrate that even state-of-the-art systems struggle on this benchmark, highlighting its ability to expose limitations of existing models. Our findings advocate for more rigorous benchmark construction and position KGQAGen as a scalable framework for advancing KGQA evaluation.
Unifying and Optimizing Data Values for Selection via Sequential-Decision-Making
Feb 06, 2025



Data selection has emerged as a crucial downstream application of data valuation. While existing data valuation methods have shown promise in selection tasks, the theoretical foundations and full potential of using data values for selection remain largely unexplored. In this work, we first demonstrate that data values applied for selection can be naturally reformulated as a sequential-decision-making problem, where the optimal data value can be derived through dynamic programming. We show this framework unifies and reinterprets existing methods like Data Shapley through the lens of approximate dynamic programming, specifically as myopic reward function approximations to this sequential problem. Furthermore, we analyze how sequential data selection optimality is affected when the ground-truth utility function exhibits monotonic submodularity with curvature. To address the computational challenges in obtaining optimal data values, we propose an efficient approximation scheme using learned bipartite graphs as surrogate utility models, ensuring greedy selection is still optimal when the surrogate utility is correctly specified and learned. Extensive experiments demonstrate the effectiveness of our approach across diverse datasets.
Overcoming Pitfalls in Graph Contrastive Learning Evaluation: Toward Comprehensive Benchmarks
Feb 24, 2024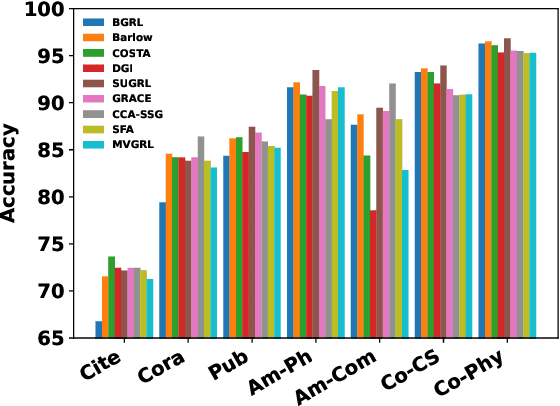
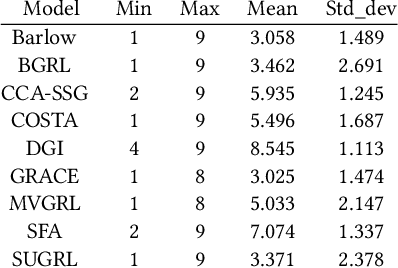
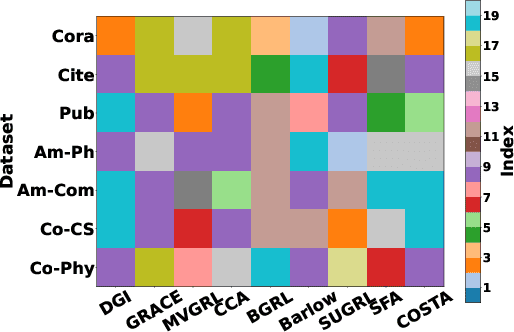
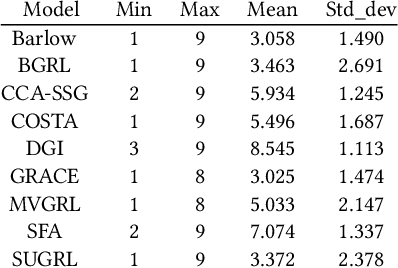
The rise of self-supervised learning, which operates without the need for labeled data, has garnered significant interest within the graph learning community. This enthusiasm has led to the development of numerous Graph Contrastive Learning (GCL) techniques, all aiming to create a versatile graph encoder that leverages the wealth of unlabeled data for various downstream tasks. However, the current evaluation standards for GCL approaches are flawed due to the need for extensive hyper-parameter tuning during pre-training and the reliance on a single downstream task for assessment. These flaws can skew the evaluation away from the intended goals, potentially leading to misleading conclusions. In our paper, we thoroughly examine these shortcomings and offer fresh perspectives on how GCL methods are affected by hyper-parameter choices and the choice of downstream tasks for their evaluation. Additionally, we introduce an enhanced evaluation framework designed to more accurately gauge the effectiveness, consistency, and overall capability of GCL methods.
Active Learning for Graphs with Noisy Structures
Feb 04, 2024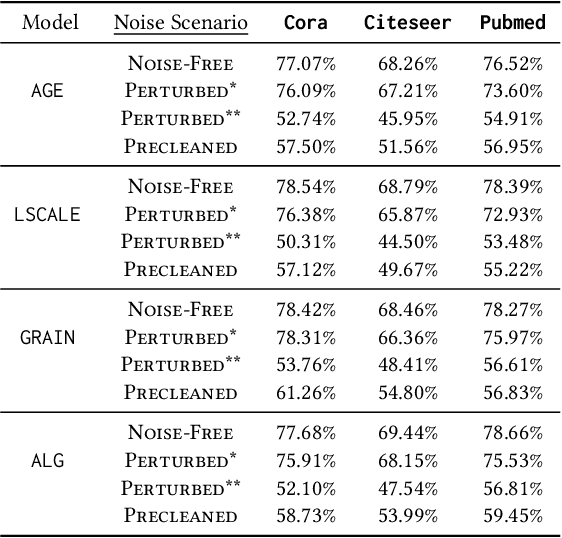



Graph Neural Networks (GNNs) have seen significant success in tasks such as node classification, largely contingent upon the availability of sufficient labeled nodes. Yet, the excessive cost of labeling large-scale graphs led to a focus on active learning on graphs, which aims for effective data selection to maximize downstream model performance. Notably, most existing methods assume reliable graph topology, while real-world scenarios often present noisy graphs. Given this, designing a successful active learning framework for noisy graphs is highly needed but challenging, as selecting data for labeling and obtaining a clean graph are two tasks naturally interdependent: selecting high-quality data requires clean graph structure while cleaning noisy graph structure requires sufficient labeled data. Considering the complexity mentioned above, we propose an active learning framework, GALClean, which has been specifically designed to adopt an iterative approach for conducting both data selection and graph purification simultaneously with best information learned from the prior iteration. Importantly, we summarize GALClean as an instance of the Expectation-Maximization algorithm, which provides a theoretical understanding of its design and mechanisms. This theory naturally leads to an enhanced version, GALClean+. Extensive experiments have demonstrated the effectiveness and robustness of our proposed method across various types and levels of noisy graphs.
Precedence-Constrained Winter Value for Effective Graph Data Valuation
Feb 02, 2024



Data valuation is essential for quantifying data's worth, aiding in assessing data quality and determining fair compensation. While existing data valuation methods have proven effective in evaluating the value of Euclidean data, they face limitations when applied to the increasingly popular graph-structured data. Particularly, graph data valuation introduces unique challenges, primarily stemming from the intricate dependencies among nodes and the exponential growth in value estimation costs. To address the challenging problem of graph data valuation, we put forth an innovative solution, Precedence-Constrained Winter (PC-Winter) Value, to account for the complex graph structure. Furthermore, we develop a variety of strategies to address the computational challenges and enable efficient approximation of PC-Winter. Extensive experiments demonstrate the effectiveness of PC-Winter across diverse datasets and tasks.
Enhancing Graph Contrastive Learning with Node Similarity
Aug 13, 2022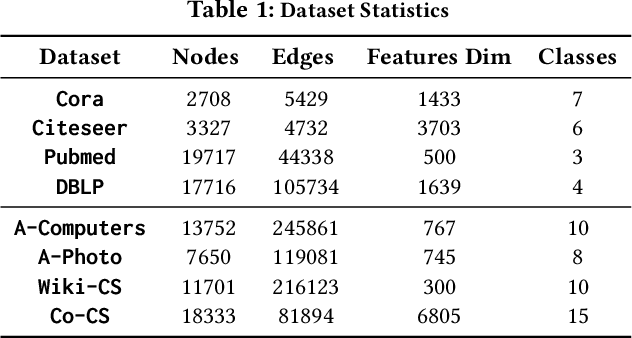
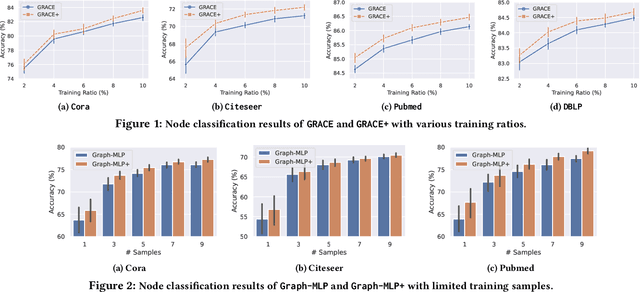
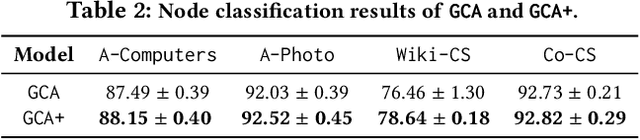

Graph Neural Networks (GNNs) have achieved great success in learning graph representations and thus facilitating various graph-related tasks. However, most GNN methods adopt a supervised learning setting, which is not always feasible in real-world applications due to the difficulty to obtain labeled data. Hence, graph self-supervised learning has been attracting increasing attention. Graph contrastive learning (GCL) is a representative framework for self-supervised learning. In general, GCL learns node representations by contrasting semantically similar nodes (positive samples) and dissimilar nodes (negative samples) with anchor nodes. Without access to labels, positive samples are typically generated by data augmentation, and negative samples are uniformly sampled from the entire graph, which leads to a sub-optimal objective. Specifically, data augmentation naturally limits the number of positive samples that involve in the process (typically only one positive sample is adopted). On the other hand, the random sampling process would inevitably select false-negative samples (samples sharing the same semantics with the anchor). These issues limit the learning capability of GCL. In this work, we propose an enhanced objective that addresses the aforementioned issues. We first introduce an unachievable ideal objective that contains all positive samples and no false-negative samples. This ideal objective is then transformed into a probabilistic form based on the distributions for sampling positive and negative samples. We then model these distributions with node similarity and derive the enhanced objective. Comprehensive experiments on various datasets demonstrate the effectiveness of the proposed enhanced objective under different settings.