 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use
Jan 31, 2026As Large Language Models (LLMs) are increasingly applied in high-stakes domains, their ability to reason strategically under uncertainty becomes critical. Poker provides a rigorous testbed, requiring not only strong actions but also principled, game-theoretic reasoning. In this paper, we conduct a systematic study of LLMs in multiple realistic poker tasks, evaluating both gameplay outcomes and reasoning traces. Our analysis reveals LLMs fail to compete against traditional algorithms and identifies three recurring flaws: reliance on heuristics, factual misunderstandings, and a "knowing-doing" gap where actions diverge from reasoning. An initial attempt with behavior cloning and step-level reinforcement learning improves reasoning style but remains insufficient for accurate game-theoretic play. Motivated by these limitations, we propose ToolPoker, a tool-integrated reasoning framework that combines external solvers for GTO-consistent actions with more precise professional-style explanations. Experiments demonstrate that ToolPoker achieves state-of-the-art gameplay while producing reasoning traces that closely reflect game-theoretic principles.
QuantLRM: Quantization of Large Reasoning Models via Fine-Tuning Signals
Jan 31, 2026Weight-only quantization is important for compressing Large Language Models (LLMs). Inspired by the spirit of classical magnitude pruning, we study whether the magnitude of weight updates during reasoning-incentivized fine-tuning can provide valuable signals for quantizing Large Reasoning Models (LRMs). We hypothesize that the smallest and largest weight updates during fine-tuning are more important than those of intermediate magnitude, a phenomenon we term "protecting both ends". Upon hypothesis validation, we introduce QuantLRM, which stands for weight quantization of LRMs via fine-tuning signals. We fit simple restricted quadratic functions on weight updates to protect both ends. By multiplying the average quadratic values with the count of zero weight updates of channels, we compute channel importance that is more effective than using activation or second-order information. We run QuantLRM to quantize various fine-tuned models (including supervised, direct preference optimization, and reinforcement learning fine-tuning) over four reasoning benchmarks (AIME-120, FOLIO, temporal sequences, and GPQA-Diamond) and empirically find that QuantLRM delivers a consistent improvement for LRMs quantization, with an average improvement of 6.55% on a reinforcement learning fine-tuned model. Also supporting non-fine-tuned LRMs, QuantLRM gathers effective signals via pseudo-fine-tuning, which greatly enhances its applicability.
Position: Agentic Evolution is the Path to Evolving LLMs
Jan 30, 2026As Large Language Models (LLMs) move from curated training sets into open-ended real-world environments, a fundamental limitation emerges: static training cannot keep pace with continual deployment environment change. Scaling training-time and inference-time compute improves static capability but does not close this train-deploy gap. We argue that addressing this limitation requires a new scaling axis-evolution. Existing deployment-time adaptation methods, whether parametric fine-tuning or heuristic memory accumulation, lack the strategic agency needed to diagnose failures and produce durable improvements. Our position is that agentic evolution represents the inevitable future of LLM adaptation, elevating evolution itself from a fixed pipeline to an autonomous evolver agent. We instantiate this vision in a general framework, A-Evolve, which treats deployment-time improvement as a deliberate, goal-directed optimization process over persistent system state. We further propose the evolution-scaling hypothesis: the capacity for adaptation scales with the compute allocated to evolution, positioning agentic evolution as a scalable path toward sustained, open-ended adaptation in the real world.
A Systemic Evaluation of Multimodal RAG Privacy
Jan 27, 2026The growing adoption of multimodal Retrieval-Augmented Generation (mRAG) pipelines for vision-centric tasks (e.g. visual QA) introduces important privacy challenges. In particular, while mRAG provides a practical capability to connect private datasets to improve model performance, it risks the leakage of private information from these datasets during inference. In this paper, we perform an empirical study to analyze the privacy risks inherent in the mRAG pipeline observed through standard model prompting. Specifically, we implement a case study that attempts to infer the inclusion of a visual asset, e.g. image, in the mRAG, and if present leak the metadata, e.g. caption, related to it. Our findings highlight the need for privacy-preserving mechanisms and motivate future research on mRAG privacy.
Query-Efficient Agentic Graph Extraction Attacks on GraphRAG Systems
Jan 21, 2026Graph-based retrieval-augmented generation (GraphRAG) systems construct knowledge graphs over document collections to support multi-hop reasoning. While prior work shows that GraphRAG responses may leak retrieved subgraphs, the feasibility of query-efficient reconstruction of the hidden graph structure remains unexplored under realistic query budgets. We study a budget-constrained black-box setting where an adversary adaptively queries the system to steal its latent entity-relation graph. We propose AGEA (Agentic Graph Extraction Attack), a framework that leverages a novelty-guided exploration-exploitation strategy, external graph memory modules, and a two-stage graph extraction pipeline combining lightweight discovery with LLM-based filtering. We evaluate AGEA on medical, agriculture, and literary datasets across Microsoft-GraphRAG and LightRAG systems. Under identical query budgets, AGEA significantly outperforms prior attack baselines, recovering up to 90% of entities and relationships while maintaining high precision. These results demonstrate that modern GraphRAG systems are highly vulnerable to structured, agentic extraction attacks, even under strict query limits.
xTime: Extreme Event Prediction with Hierarchical Knowledge Distillation and Expert Fusion
Oct 23, 2025Extreme events frequently occur in real-world time series and often carry significant practical implications. In domains such as climate and healthcare, these events, such as floods, heatwaves, or acute medical episodes, can lead to serious consequences. Accurate forecasting of such events is therefore of substantial importance. Most existing time series forecasting models are optimized for overall performance within the prediction window, but often struggle to accurately predict extreme events, such as high temperatures or heart rate spikes. The main challenges are data imbalance and the neglect of valuable information contained in intermediate events that precede extreme events. In this paper, we propose xTime, a novel framework for extreme event forecasting in time series. xTime leverages knowledge distillation to transfer information from models trained on lower-rarity events, thereby improving prediction performance on rarer ones. In addition, we introduce a mixture of experts (MoE) mechanism that dynamically selects and fuses outputs from expert models across different rarity levels, which further improves the forecasting performance for extreme events. Experiments on multiple datasets show that xTime achieves consistent improvements, with forecasting accuracy on extreme events improving from 3% to 78%.
TRAJECT-Bench:A Trajectory-Aware Benchmark for Evaluating Agentic Tool Use
Oct 06, 2025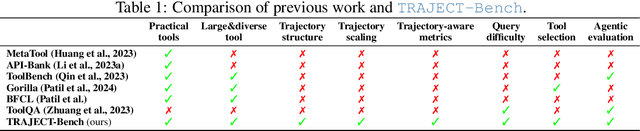

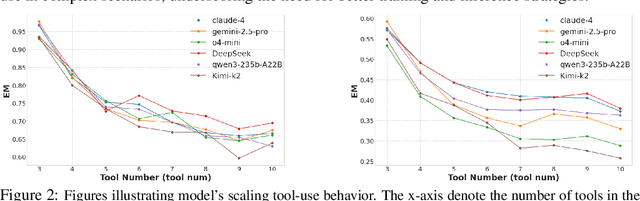
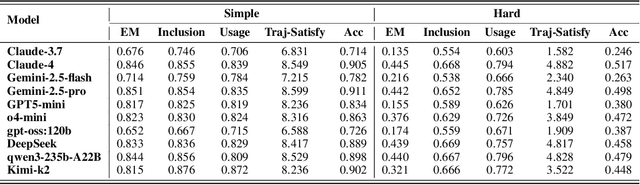
Large language model (LLM)-based agents increasingly rely on tool use to complete real-world tasks. While existing works evaluate the LLMs' tool use capability, they largely focus on the final answers yet overlook the detailed tool usage trajectory, i.e., whether tools are selected, parameterized, and ordered correctly. We introduce TRAJECT-Bench, a trajectory-aware benchmark to comprehensively evaluate LLMs' tool use capability through diverse tasks with fine-grained evaluation metrics. TRAJECT-Bench pairs high-fidelity, executable tools across practical domains with tasks grounded in production-style APIs, and synthesizes trajectories that vary in breadth (parallel calls) and depth (interdependent chains). Besides final accuracy, TRAJECT-Bench also reports trajectory-level diagnostics, including tool selection and argument correctness, and dependency/order satisfaction. Analyses reveal failure modes such as similar tool confusion and parameter-blind selection, and scaling behavior with tool diversity and trajectory length where the bottleneck of transiting from short to mid-length trajectories is revealed, offering actionable guidance for LLMs' tool use.
Exposing Privacy Risks in Graph Retrieval-Augmented Generation
Aug 24, 2025Retrieval-Augmented Generation (RAG) is a powerful technique for enhancing Large Language Models (LLMs) with external, up-to-date knowledge. Graph RAG has emerged as an advanced paradigm that leverages graph-based knowledge structures to provide more coherent and contextually rich answers. However, the move from plain document retrieval to structured graph traversal introduces new, under-explored privacy risks. This paper investigates the data extraction vulnerabilities of the Graph RAG systems. We design and execute tailored data extraction attacks to probe their susceptibility to leaking both raw text and structured data, such as entities and their relationships. Our findings reveal a critical trade-off: while Graph RAG systems may reduce raw text leakage, they are significantly more vulnerable to the extraction of structured entity and relationship information. We also explore potential defense mechanisms to mitigate these novel attack surfaces. This work provides a foundational analysis of the unique privacy challenges in Graph RAG and offers insights for building more secure systems.
Bradley-Terry and Multi-Objective Reward Modeling Are Complementary
Jul 10, 2025Reward models trained on human preference data have demonstrated strong effectiveness in aligning Large Language Models (LLMs) with human intent under the framework of Reinforcement Learning from Human Feedback (RLHF). However, RLHF remains vulnerable to reward hacking, where the policy exploits imperfections in the reward function rather than genuinely learning the intended behavior. Although significant efforts have been made to mitigate reward hacking, they predominantly focus on and evaluate in-distribution scenarios, where the training and testing data for the reward model share the same distribution. In this paper, we empirically show that state-of-the-art methods struggle in more challenging out-of-distribution (OOD) settings. We further demonstrate that incorporating fine-grained multi-attribute scores helps address this challenge. However, the limited availability of high-quality data often leads to weak performance of multi-objective reward functions, which can negatively impact overall performance and become the bottleneck. To address this issue, we propose a unified reward modeling framework that jointly trains Bradley--Terry (BT) single-objective and multi-objective regression-based reward functions using a shared embedding space. We theoretically establish a connection between the BT loss and the regression objective and highlight their complementary benefits. Specifically, the regression task enhances the single-objective reward function's ability to mitigate reward hacking in challenging OOD settings, while BT-based training improves the scoring capability of the multi-objective reward function, enabling a 7B model to outperform a 70B baseline. Extensive experimental results demonstrate that our framework significantly improves both the robustness and the scoring performance of reward models.
Image Corruption-Inspired Membership Inference Attacks against Large Vision-Language Models
Jun 14, 2025Large vision-language models (LVLMs) have demonstrated outstanding performance in many downstream tasks. However, LVLMs are trained on large-scale datasets, which can pose privacy risks if training images contain sensitive information. Therefore, it is important to detect whether an image is used to train the LVLM. Recent studies have investigated membership inference attacks (MIAs) against LVLMs, including detecting image-text pairs and single-modality content. In this work, we focus on detecting whether a target image is used to train the target LVLM. We design simple yet effective Image Corruption-Inspired Membership Inference Attacks (ICIMIA) against LLVLMs, which are inspired by LVLM's different sensitivity to image corruption for member and non-member images. We first perform an MIA method under the white-box setting, where we can obtain the embeddings of the image through the vision part of the target LVLM. The attacks are based on the embedding similarity between the image and its corrupted version. We further explore a more practical scenario where we have no knowledge about target LVLMs and we can only query the target LVLMs with an image and a question. We then conduct the attack by utilizing the output text embeddings' similarity. Experiments on existing datasets validate the effectiveness of our proposed attack methods under those two different settings.