 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoute to Rome Attack: Directing LLM Routers to Expensive Models via Adversarial Suffix Optimization
Apr 16, 2026Cost-aware routing dynamically dispatches user queries to models of varying capability to balance performance and inference cost. However, the routing strategy introduces a new security concern that adversaries may manipulate the router to consistently select expensive high-capability models. Existing routing attacks depend on either white-box access or heuristic prompts, rendering them ineffective in real-world black-box scenarios. In this work, we propose R$^2$A, which aims to mislead black-box LLM routers to expensive models via adversarial suffix optimization. Specifically, R$^2$A deploys a hybrid ensemble surrogate router to mimic the black-box router. A suffix optimization algorithm is further adapted for the ensemble-based surrogate. Extensive experiments on multiple open-source and commercial routing systems demonstrate that {R$^2$A} significantly increases the routing rate to expensive models on queries of different distributions. Code and examples: https://github.com/thcxiker/R2A-Attack.
CAGenMol: Condition-Aware Diffusion Language Model for Goal-Directed Molecular Generation
Apr 13, 2026Goal-directed molecular generation requires satisfying heterogeneous constraints such as protein--ligand compatibility and multi-objective drug-like properties, yet existing methods often optimize these constraints in isolation, failing to reconcile conflicting objectives (e.g., affinity vs. safety), and struggle to navigate the non-differentiable chemical space without compromising structural validity. To address these challenges, we propose CAGenMol, a condition-aware discrete diffusion framework over molecular sequences that formulates molecular design as conditional denoising guided by heterogeneous structural and property signals. By coupling discrete diffusion with reinforcement learning, the model aligns the generation trajectory with non-differentiable objectives while preserving chemical validity and diversity. The non-autoregressive nature of diffusion language model further enables iterative refinement of molecular fragments at inference time. Experiments on structure-conditioned, property-conditioned, and dual-conditioned benchmarks demonstrate consistent improvements over state-of-the-art methods in binding affinity, drug-likeness, and success rate, highlighting the effectiveness of our framework.
SCL-GNN: Towards Generalizable Graph Neural Networks via Spurious Correlation Learning
Mar 09, 2026Graph Neural Networks (GNNs) have demonstrated remarkable success across diverse tasks. However, their generalization capability is often hindered by spurious correlations between node features and labels in the graph. Our analysis reveals that GNNs tend to exploit imperceptible statistical correlations in training data, even when such correlations are unreliable for prediction. To address this challenge, we propose the Spurious Correlation Learning Graph Neural Network (SCL-GNN), a novel framework designed to enhance generalization on both Independent and Identically Distributed (IID) and Out-of-Distribution (OOD) graphs. SCL-GNN incorporates a principled spurious correlation learning mechanism, leveraging the Hilbert-Schmidt Independence Criterion (HSIC) to quantify correlations between node representations and class scores. This enables the model to identify and mitigate irrelevant but influential spurious correlations effectively. Additionally, we introduce an efficient bi-level optimization strategy to jointly optimize modules and GNN parameters, preventing overfitting. Extensive experiments on real-world and synthetic datasets demonstrate that SCL-GNN consistently outperforms state-of-the-art baselines under various distribution shifts, highlighting its robustness and generalization capabilities.
Poisoning the Inner Prediction Logic of Graph Neural Networks for Clean-Label Backdoor Attacks
Mar 05, 2026Graph Neural Networks (GNNs) have achieved remarkable results in various tasks. Recent studies reveal that graph backdoor attacks can poison the GNN model to predict test nodes with triggers attached as the target class. However, apart from injecting triggers to training nodes, these graph backdoor attacks generally require altering the labels of trigger-attached training nodes into the target class, which is impractical in real-world scenarios. In this work, we focus on the clean-label graph backdoor attack, a realistic but understudied topic where training labels are not modifiable. According to our preliminary analysis, existing graph backdoor attacks generally fail under the clean-label setting. Our further analysis identifies that the core failure of existing methods lies in their inability to poison the prediction logic of GNN models, leading to the triggers being deemed unimportant for prediction. Therefore, we study a novel problem of effective clean-label graph backdoor attacks by poisoning the inner prediction logic of GNN models. We propose BA-Logic to solve the problem by coordinating a poisoned node selector and a logic-poisoning trigger generator. Extensive experiments on real-world datasets demonstrate that our method effectively enhances the attack success rate and surpasses state-of-the-art graph backdoor attack competitors under clean-label settings. Our code is available at https://anonymous.4open.science/r/BA-Logic
How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use
Jan 31, 2026As Large Language Models (LLMs) are increasingly applied in high-stakes domains, their ability to reason strategically under uncertainty becomes critical. Poker provides a rigorous testbed, requiring not only strong actions but also principled, game-theoretic reasoning. In this paper, we conduct a systematic study of LLMs in multiple realistic poker tasks, evaluating both gameplay outcomes and reasoning traces. Our analysis reveals LLMs fail to compete against traditional algorithms and identifies three recurring flaws: reliance on heuristics, factual misunderstandings, and a "knowing-doing" gap where actions diverge from reasoning. An initial attempt with behavior cloning and step-level reinforcement learning improves reasoning style but remains insufficient for accurate game-theoretic play. Motivated by these limitations, we propose ToolPoker, a tool-integrated reasoning framework that combines external solvers for GTO-consistent actions with more precise professional-style explanations. Experiments demonstrate that ToolPoker achieves state-of-the-art gameplay while producing reasoning traces that closely reflect game-theoretic principles.
FairGE: Fairness-Aware Graph Encoding in Incomplete Social Networks
Jan 14, 2026Graph Transformers (GTs) are increasingly applied to social network analysis, yet their deployment is often constrained by fairness concerns. This issue is particularly critical in incomplete social networks, where sensitive attributes are frequently missing due to privacy and ethical restrictions. Existing solutions commonly generate these incomplete attributes, which may introduce additional biases and further compromise user privacy. To address this challenge, FairGE (Fair Graph Encoding) is introduced as a fairness-aware framework for GTs in incomplete social networks. Instead of generating sensitive attributes, FairGE encodes fairness directly through spectral graph theory. By leveraging the principal eigenvector to represent structural information and padding incomplete sensitive attributes with zeros to maintain independence, FairGE ensures fairness without data reconstruction. Theoretical analysis demonstrates that the method suppresses the influence of non-principal spectral components, thereby enhancing fairness. Extensive experiments on seven real-world social network datasets confirm that FairGE achieves at least a 16% improvement in both statistical parity and equality of opportunity compared with state-of-the-art baselines. The source code is shown in https://github.com/LuoRenqiang/FairGE.
DuFFin: A Dual-Level Fingerprinting Framework for LLMs IP Protection
May 22, 2025Large language models (LLMs) are considered valuable Intellectual Properties (IP) for legitimate owners due to the enormous computational cost of training. It is crucial to protect the IP of LLMs from malicious stealing or unauthorized deployment. Despite existing efforts in watermarking and fingerprinting LLMs, these methods either impact the text generation process or are limited in white-box access to the suspect model, making them impractical. Hence, we propose DuFFin, a novel $\textbf{Du}$al-Level $\textbf{Fin}$gerprinting $\textbf{F}$ramework for black-box setting ownership verification. DuFFin extracts the trigger pattern and the knowledge-level fingerprints to identify the source of a suspect model. We conduct experiments on a variety of models collected from the open-source website, including four popular base models as protected LLMs and their fine-tuning, quantization, and safety alignment versions, which are released by large companies, start-ups, and individual users. Results show that our method can accurately verify the copyright of the base protected LLM on their model variants, achieving the IP-ROC metric greater than 0.95. Our code is available at https://github.com/yuliangyan0807/llm-fingerprint.
Fairness in Graph Learning Augmented with Machine Learning: A Survey
Apr 30, 2025Augmenting specialised machine learning techniques into traditional graph learning models has achieved notable success across various domains, including federated graph learning, dynamic graph learning, and graph transformers. However, the intricate mechanisms of these specialised techniques introduce significant challenges in maintaining model fairness, potentially resulting in discriminatory outcomes in high-stakes applications such as recommendation systems, disaster response, criminal justice, and loan approval. This paper systematically examines the unique fairness challenges posed by Graph Learning augmented with Machine Learning (GL-ML). It highlights the complex interplay between graph learning mechanisms and machine learning techniques, emphasising how the augmentation of machine learning both enhances and complicates fairness. Additionally, we explore four critical techniques frequently employed to improve fairness in GL-ML methods. By thoroughly investigating the root causes and broader implications of fairness challenges in this rapidly evolving field, this work establishes a robust foundation for future research and innovation in GL-ML fairness.
LanP: Rethinking the Impact of Language Priors in Large Vision-Language Models
Feb 17, 2025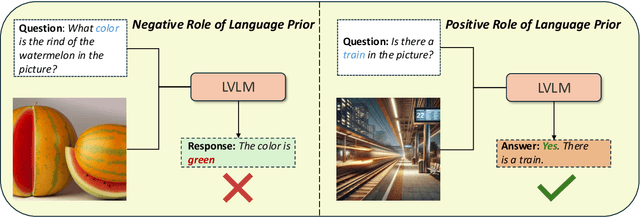
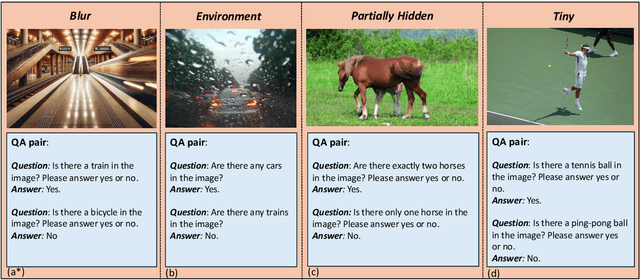
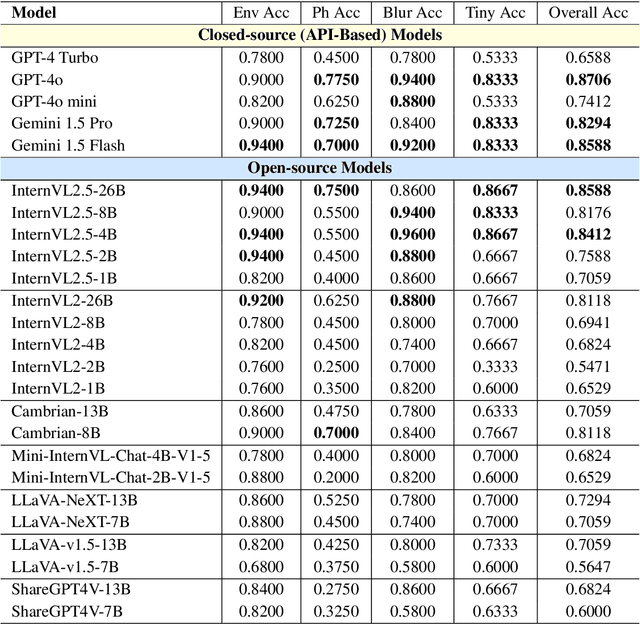
Large Vision-Language Models (LVLMs) have shown impressive performance in various tasks. However, LVLMs suffer from hallucination, which hinders their adoption in the real world. Existing studies emphasized that the strong language priors of LVLMs can overpower visual information, causing hallucinations. However, the positive role of language priors is the key to a powerful LVLM. If the language priors are too weak, LVLMs will struggle to leverage rich parameter knowledge and instruction understanding abilities to complete tasks in challenging visual scenarios where visual information alone is insufficient. Therefore, we propose a benchmark called LanP to rethink the impact of Language Priors in LVLMs. It is designed to investigate how strong language priors are in current LVLMs. LanP consists of 170 images and 340 corresponding well-designed questions. Extensive experiments on 25 popular LVLMs reveal that many LVLMs' language priors are not strong enough to effectively aid question answering when objects are partially hidden. Many models, including GPT-4 Turbo, exhibit an accuracy below 0.5 in such a scenario.
LiSA: Leveraging Link Recommender to Attack Graph Neural Networks via Subgraph Injection
Feb 13, 2025Graph Neural Networks (GNNs) have demonstrated remarkable proficiency in modeling data with graph structures, yet recent research reveals their susceptibility to adversarial attacks. Traditional attack methodologies, which rely on manipulating the original graph or adding links to artificially created nodes, often prove impractical in real-world settings. This paper introduces a novel adversarial scenario involving the injection of an isolated subgraph to deceive both the link recommender and the node classifier within a GNN system. Specifically, the link recommender is mislead to propose links between targeted victim nodes and the subgraph, encouraging users to unintentionally establish connections and that would degrade the node classification accuracy, thereby facilitating a successful attack. To address this, we present the LiSA framework, which employs a dual surrogate model and bi-level optimization to simultaneously meet two adversarial objectives. Extensive experiments on real-world datasets demonstrate the effectiveness of our method.