 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use
Jan 31, 2026As Large Language Models (LLMs) are increasingly applied in high-stakes domains, their ability to reason strategically under uncertainty becomes critical. Poker provides a rigorous testbed, requiring not only strong actions but also principled, game-theoretic reasoning. In this paper, we conduct a systematic study of LLMs in multiple realistic poker tasks, evaluating both gameplay outcomes and reasoning traces. Our analysis reveals LLMs fail to compete against traditional algorithms and identifies three recurring flaws: reliance on heuristics, factual misunderstandings, and a "knowing-doing" gap where actions diverge from reasoning. An initial attempt with behavior cloning and step-level reinforcement learning improves reasoning style but remains insufficient for accurate game-theoretic play. Motivated by these limitations, we propose ToolPoker, a tool-integrated reasoning framework that combines external solvers for GTO-consistent actions with more precise professional-style explanations. Experiments demonstrate that ToolPoker achieves state-of-the-art gameplay while producing reasoning traces that closely reflect game-theoretic principles.
Position: Agentic Evolution is the Path to Evolving LLMs
Jan 30, 2026As Large Language Models (LLMs) move from curated training sets into open-ended real-world environments, a fundamental limitation emerges: static training cannot keep pace with continual deployment environment change. Scaling training-time and inference-time compute improves static capability but does not close this train-deploy gap. We argue that addressing this limitation requires a new scaling axis-evolution. Existing deployment-time adaptation methods, whether parametric fine-tuning or heuristic memory accumulation, lack the strategic agency needed to diagnose failures and produce durable improvements. Our position is that agentic evolution represents the inevitable future of LLM adaptation, elevating evolution itself from a fixed pipeline to an autonomous evolver agent. We instantiate this vision in a general framework, A-Evolve, which treats deployment-time improvement as a deliberate, goal-directed optimization process over persistent system state. We further propose the evolution-scaling hypothesis: the capacity for adaptation scales with the compute allocated to evolution, positioning agentic evolution as a scalable path toward sustained, open-ended adaptation in the real world.
xTime: Extreme Event Prediction with Hierarchical Knowledge Distillation and Expert Fusion
Oct 23, 2025Extreme events frequently occur in real-world time series and often carry significant practical implications. In domains such as climate and healthcare, these events, such as floods, heatwaves, or acute medical episodes, can lead to serious consequences. Accurate forecasting of such events is therefore of substantial importance. Most existing time series forecasting models are optimized for overall performance within the prediction window, but often struggle to accurately predict extreme events, such as high temperatures or heart rate spikes. The main challenges are data imbalance and the neglect of valuable information contained in intermediate events that precede extreme events. In this paper, we propose xTime, a novel framework for extreme event forecasting in time series. xTime leverages knowledge distillation to transfer information from models trained on lower-rarity events, thereby improving prediction performance on rarer ones. In addition, we introduce a mixture of experts (MoE) mechanism that dynamically selects and fuses outputs from expert models across different rarity levels, which further improves the forecasting performance for extreme events. Experiments on multiple datasets show that xTime achieves consistent improvements, with forecasting accuracy on extreme events improving from 3% to 78%.
Bradley-Terry and Multi-Objective Reward Modeling Are Complementary
Jul 10, 2025Reward models trained on human preference data have demonstrated strong effectiveness in aligning Large Language Models (LLMs) with human intent under the framework of Reinforcement Learning from Human Feedback (RLHF). However, RLHF remains vulnerable to reward hacking, where the policy exploits imperfections in the reward function rather than genuinely learning the intended behavior. Although significant efforts have been made to mitigate reward hacking, they predominantly focus on and evaluate in-distribution scenarios, where the training and testing data for the reward model share the same distribution. In this paper, we empirically show that state-of-the-art methods struggle in more challenging out-of-distribution (OOD) settings. We further demonstrate that incorporating fine-grained multi-attribute scores helps address this challenge. However, the limited availability of high-quality data often leads to weak performance of multi-objective reward functions, which can negatively impact overall performance and become the bottleneck. To address this issue, we propose a unified reward modeling framework that jointly trains Bradley--Terry (BT) single-objective and multi-objective regression-based reward functions using a shared embedding space. We theoretically establish a connection between the BT loss and the regression objective and highlight their complementary benefits. Specifically, the regression task enhances the single-objective reward function's ability to mitigate reward hacking in challenging OOD settings, while BT-based training improves the scoring capability of the multi-objective reward function, enabling a 7B model to outperform a 70B baseline. Extensive experimental results demonstrate that our framework significantly improves both the robustness and the scoring performance of reward models.
Image Corruption-Inspired Membership Inference Attacks against Large Vision-Language Models
Jun 14, 2025Large vision-language models (LVLMs) have demonstrated outstanding performance in many downstream tasks. However, LVLMs are trained on large-scale datasets, which can pose privacy risks if training images contain sensitive information. Therefore, it is important to detect whether an image is used to train the LVLM. Recent studies have investigated membership inference attacks (MIAs) against LVLMs, including detecting image-text pairs and single-modality content. In this work, we focus on detecting whether a target image is used to train the target LVLM. We design simple yet effective Image Corruption-Inspired Membership Inference Attacks (ICIMIA) against LLVLMs, which are inspired by LVLM's different sensitivity to image corruption for member and non-member images. We first perform an MIA method under the white-box setting, where we can obtain the embeddings of the image through the vision part of the target LVLM. The attacks are based on the embedding similarity between the image and its corrupted version. We further explore a more practical scenario where we have no knowledge about target LVLMs and we can only query the target LVLMs with an image and a question. We then conduct the attack by utilizing the output text embeddings' similarity. Experiments on existing datasets validate the effectiveness of our proposed attack methods under those two different settings.
How Far are LLMs from Real Search? A Comprehensive Study on Efficiency, Completeness, and Inherent Capabilities
Feb 26, 2025Search plays a fundamental role in problem-solving across various domains, with most real-world decision-making problems being solvable through systematic search. Drawing inspiration from recent discussions on search and learning, we systematically explore the complementary relationship between search and Large Language Models (LLMs) from three perspectives. First, we analyze how learning can enhance search efficiency and propose Search via Learning (SeaL), a framework that leverages LLMs for effective and efficient search. Second, we further extend SeaL to SeaL-C to ensure rigorous completeness during search. Our evaluation across three real-world planning tasks demonstrates that SeaL achieves near-perfect accuracy while reducing search spaces by up to 99.1% compared to traditional approaches. Finally, we explore how far LLMs are from real search by investigating whether they can develop search capabilities independently. Our analysis reveals that while current LLMs struggle with efficient search in complex problems, incorporating systematic search strategies significantly enhances their problem-solving capabilities. These findings not only validate the effectiveness of our approach but also highlight the need for improving LLMs' search abilities for real-world applications.
LanP: Rethinking the Impact of Language Priors in Large Vision-Language Models
Feb 17, 2025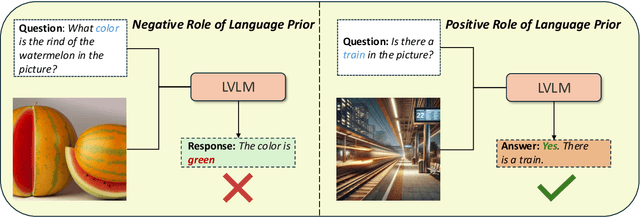
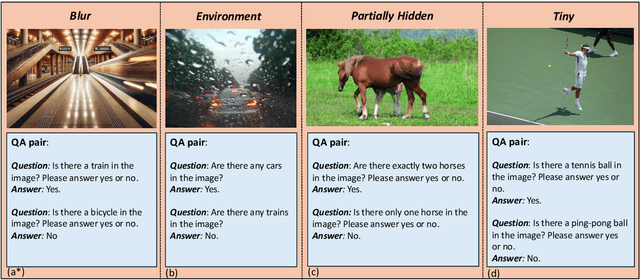
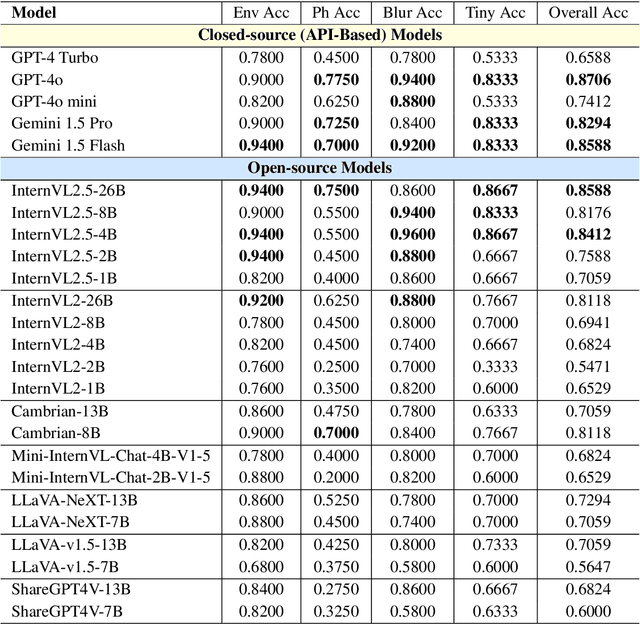
Large Vision-Language Models (LVLMs) have shown impressive performance in various tasks. However, LVLMs suffer from hallucination, which hinders their adoption in the real world. Existing studies emphasized that the strong language priors of LVLMs can overpower visual information, causing hallucinations. However, the positive role of language priors is the key to a powerful LVLM. If the language priors are too weak, LVLMs will struggle to leverage rich parameter knowledge and instruction understanding abilities to complete tasks in challenging visual scenarios where visual information alone is insufficient. Therefore, we propose a benchmark called LanP to rethink the impact of Language Priors in LVLMs. It is designed to investigate how strong language priors are in current LVLMs. LanP consists of 170 images and 340 corresponding well-designed questions. Extensive experiments on 25 popular LVLMs reveal that many LVLMs' language priors are not strong enough to effectively aid question answering when objects are partially hidden. Many models, including GPT-4 Turbo, exhibit an accuracy below 0.5 in such a scenario.
Stealing Training Graphs from Graph Neural Networks
Nov 17, 2024


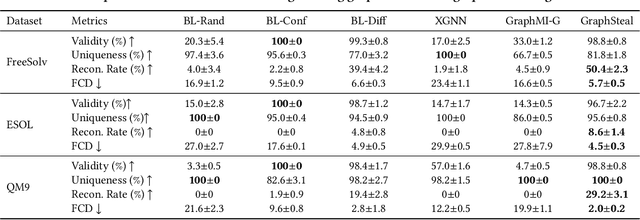
Graph Neural Networks (GNNs) have shown promising results in modeling graphs in various tasks. The training of GNNs, especially on specialized tasks such as bioinformatics, demands extensive expert annotations, which are expensive and usually contain sensitive information of data providers. The trained GNN models are often shared for deployment in the real world. As neural networks can memorize the training samples, the model parameters of GNNs have a high risk of leaking private training data. Our theoretical analysis shows the strong connections between trained GNN parameters and the training graphs used, confirming the training graph leakage issue. However, explorations into training data leakage from trained GNNs are rather limited. Therefore, we investigate a novel problem of stealing graphs from trained GNNs. To obtain high-quality graphs that resemble the target training set, a graph diffusion model with diffusion noise optimization is deployed as a graph generator. Furthermore, we propose a selection method that effectively leverages GNN model parameters to identify training graphs from samples generated by the graph diffusion model. Extensive experiments on real-world datasets demonstrate the effectiveness of the proposed framework in stealing training graphs from the trained GNN.
Decoding Time Series with LLMs: A Multi-Agent Framework for Cross-Domain Annotation
Oct 22, 2024



Time series data is ubiquitous across various domains, including manufacturing, finance, and healthcare. High-quality annotations are essential for effectively understanding time series and facilitating downstream tasks; however, obtaining such annotations is challenging, particularly in mission-critical domains. In this paper, we propose TESSA, a multi-agent system designed to automatically generate both general and domain-specific annotations for time series data. TESSA introduces two agents: a general annotation agent and a domain-specific annotation agent. The general agent captures common patterns and knowledge across multiple source domains, leveraging both time-series-wise and text-wise features to generate general annotations. Meanwhile, the domain-specific agent utilizes limited annotations from the target domain to learn domain-specific terminology and generate targeted annotations. Extensive experiments on multiple synthetic and real-world datasets demonstrate that TESSA effectively generates high-quality annotations, outperforming existing methods.
Trojan Prompt Attacks on Graph Neural Networks
Oct 17, 2024



Graph Prompt Learning (GPL) has been introduced as a promising approach that uses prompts to adapt pre-trained GNN models to specific downstream tasks without requiring fine-tuning of the entire model. Despite the advantages of GPL, little attention has been given to its vulnerability to backdoor attacks, where an adversary can manipulate the model's behavior by embedding hidden triggers. Existing graph backdoor attacks rely on modifying model parameters during training, but this approach is impractical in GPL as GNN encoder parameters are frozen after pre-training. Moreover, downstream users may fine-tune their own task models on clean datasets, further complicating the attack. In this paper, we propose TGPA, a backdoor attack framework designed specifically for GPL. TGPA injects backdoors into graph prompts without modifying pre-trained GNN encoders and ensures high attack success rates and clean accuracy. To address the challenge of model fine-tuning by users, we introduce a finetuning-resistant poisoning approach that maintains the effectiveness of the backdoor even after downstream model adjustments. Extensive experiments on multiple datasets under various settings demonstrate the effectiveness of TGPA in compromising GPL models with fixed GNN encoders.