 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiFSQ: Improving FSQ for Image Generation with 1 Line of Code
Jan 27, 2026The field of image generation is currently bifurcated into autoregressive (AR) models operating on discrete tokens and diffusion models utilizing continuous latents. This divide, rooted in the distinction between VQ-VAEs and VAEs, hinders unified modeling and fair benchmarking. Finite Scalar Quantization (FSQ) offers a theoretical bridge, yet vanilla FSQ suffers from a critical flaw: its equal-interval quantization can cause activation collapse. This mismatch forces a trade-off between reconstruction fidelity and information efficiency. In this work, we resolve this dilemma by simply replacing the activation function in original FSQ with a distribution-matching mapping to enforce a uniform prior. Termed iFSQ, this simple strategy requires just one line of code yet mathematically guarantees both optimal bin utilization and reconstruction precision. Leveraging iFSQ as a controlled benchmark, we uncover two key insights: (1) The optimal equilibrium between discrete and continuous representations lies at approximately 4 bits per dimension. (2) Under identical reconstruction constraints, AR models exhibit rapid initial convergence, whereas diffusion models achieve a superior performance ceiling, suggesting that strict sequential ordering may limit the upper bounds of generation quality. Finally, we extend our analysis by adapting Representation Alignment (REPA) to AR models, yielding LlamaGen-REPA. Codes is available at https://github.com/Tencent-Hunyuan/iFSQ
Memory in the Age of AI Agents
Dec 15, 2025Memory has emerged, and will continue to remain, a core capability of foundation model-based agents. As research on agent memory rapidly expands and attracts unprecedented attention, the field has also become increasingly fragmented. Existing works that fall under the umbrella of agent memory often differ substantially in their motivations, implementations, and evaluation protocols, while the proliferation of loosely defined memory terminologies has further obscured conceptual clarity. Traditional taxonomies such as long/short-term memory have proven insufficient to capture the diversity of contemporary agent memory systems. This work aims to provide an up-to-date landscape of current agent memory research. We begin by clearly delineating the scope of agent memory and distinguishing it from related concepts such as LLM memory, retrieval augmented generation (RAG), and context engineering. We then examine agent memory through the unified lenses of forms, functions, and dynamics. From the perspective of forms, we identify three dominant realizations of agent memory, namely token-level, parametric, and latent memory. From the perspective of functions, we propose a finer-grained taxonomy that distinguishes factual, experiential, and working memory. From the perspective of dynamics, we analyze how memory is formed, evolved, and retrieved over time. To support practical development, we compile a comprehensive summary of memory benchmarks and open-source frameworks. Beyond consolidation, we articulate a forward-looking perspective on emerging research frontiers, including memory automation, reinforcement learning integration, multimodal memory, multi-agent memory, and trustworthiness issues. We hope this survey serves not only as a reference for existing work, but also as a conceptual foundation for rethinking memory as a first-class primitive in the design of future agentic intelligence.
SRUM: Fine-Grained Self-Rewarding for Unified Multimodal Models
Oct 14, 2025Recently, remarkable progress has been made in Unified Multimodal Models (UMMs), which integrate vision-language generation and understanding capabilities within a single framework. However, a significant gap exists where a model's strong visual understanding often fails to transfer to its visual generation. A model might correctly understand an image based on user instructions, yet be unable to generate a faithful image from text prompts. This phenomenon directly raises a compelling question: Can a model achieve self-improvement by using its understanding module to reward its generation module? To bridge this gap and achieve self-improvement, we introduce SRUM, a self-rewarding post-training framework that can be directly applied to existing UMMs of various designs. SRUM creates a feedback loop where the model's own understanding module acts as an internal ``evaluator'', providing corrective signals to improve its generation module, without requiring additional human-labeled data. To ensure this feedback is comprehensive, we designed a global-local dual reward system. To tackle the inherent structural complexity of images, this system offers multi-scale guidance: a \textbf{global reward} ensures the correctness of the overall visual semantics and layout, while a \textbf{local reward} refines fine-grained, object-level fidelity. SRUM leads to powerful capabilities and shows strong generalization, boosting performance on T2I-CompBench from 82.18 to \textbf{88.37} and on T2I-ReasonBench from 43.82 to \textbf{46.75}. Overall, our work establishes a powerful new paradigm for enabling a UMMs' understanding module to guide and enhance its own generation via self-rewarding.
LangBridge: Interpreting Image as a Combination of Language Embeddings
Mar 26, 2025



Recent years have witnessed remarkable advances in Large Vision-Language Models (LVLMs), which have achieved human-level performance across various complex vision-language tasks. Following LLaVA's paradigm, mainstream LVLMs typically employ a shallow MLP for visual-language alignment through a two-stage training process: pretraining for cross-modal alignment followed by instruction tuning. While this approach has proven effective, the underlying mechanisms of how MLPs bridge the modality gap remain poorly understood. Although some research has explored how LLMs process transformed visual tokens, few studies have investigated the fundamental alignment mechanism. Furthermore, the MLP adapter requires retraining whenever switching LLM backbones. To address these limitations, we first investigate the working principles of MLP adapters and discover that they learn to project visual embeddings into subspaces spanned by corresponding text embeddings progressively. Based on this insight, we propose LangBridge, a novel adapter that explicitly maps visual tokens to linear combinations of LLM vocabulary embeddings. This innovative design enables pretraining-free adapter transfer across different LLMs while maintaining performance. Our experimental results demonstrate that a LangBridge adapter pre-trained on Qwen2-0.5B can be directly applied to larger models such as LLaMA3-8B or Qwen2.5-14B while maintaining competitive performance. Overall, LangBridge enables interpretable vision-language alignment by grounding visual representations in LLM vocab embedding, while its plug-and-play design ensures efficient reuse across multiple LLMs with nearly no performance degradation. See our project page at https://jiaqiliao77.github.io/LangBridge.github.io/
WISE: A World Knowledge-Informed Semantic Evaluation for Text-to-Image Generation
Mar 10, 2025Text-to-Image (T2I) models are capable of generating high-quality artistic creations and visual content. However, existing research and evaluation standards predominantly focus on image realism and shallow text-image alignment, lacking a comprehensive assessment of complex semantic understanding and world knowledge integration in text to image generation. To address this challenge, we propose $\textbf{WISE}$, the first benchmark specifically designed for $\textbf{W}$orld Knowledge-$\textbf{I}$nformed $\textbf{S}$emantic $\textbf{E}$valuation. WISE moves beyond simple word-pixel mapping by challenging models with 1000 meticulously crafted prompts across 25 sub-domains in cultural common sense, spatio-temporal reasoning, and natural science. To overcome the limitations of traditional CLIP metric, we introduce $\textbf{WiScore}$, a novel quantitative metric for assessing knowledge-image alignment. Through comprehensive testing of 20 models (10 dedicated T2I models and 10 unified multimodal models) using 1,000 structured prompts spanning 25 subdomains, our findings reveal significant limitations in their ability to effectively integrate and apply world knowledge during image generation, highlighting critical pathways for enhancing knowledge incorporation and application in next-generation T2I models. Code and data are available at https://github.com/PKU-YuanGroup/WISE.
LanP: Rethinking the Impact of Language Priors in Large Vision-Language Models
Feb 17, 2025
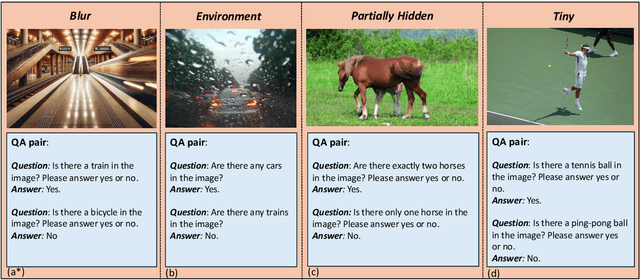
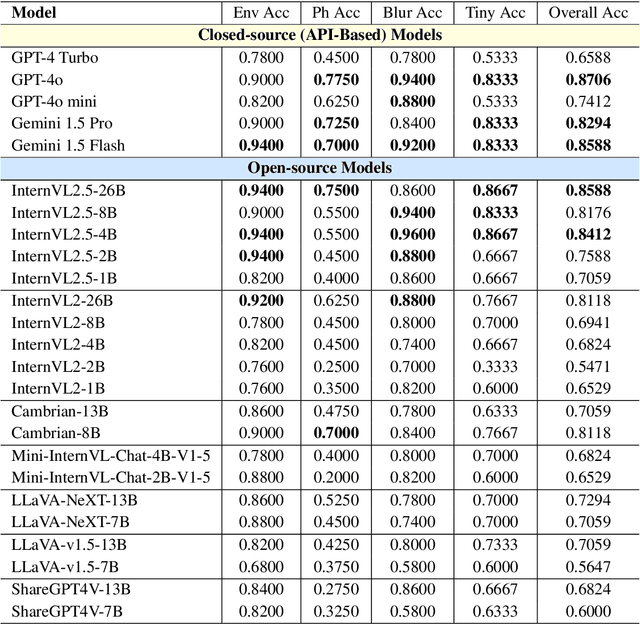
Large Vision-Language Models (LVLMs) have shown impressive performance in various tasks. However, LVLMs suffer from hallucination, which hinders their adoption in the real world. Existing studies emphasized that the strong language priors of LVLMs can overpower visual information, causing hallucinations. However, the positive role of language priors is the key to a powerful LVLM. If the language priors are too weak, LVLMs will struggle to leverage rich parameter knowledge and instruction understanding abilities to complete tasks in challenging visual scenarios where visual information alone is insufficient. Therefore, we propose a benchmark called LanP to rethink the impact of Language Priors in LVLMs. It is designed to investigate how strong language priors are in current LVLMs. LanP consists of 170 images and 340 corresponding well-designed questions. Extensive experiments on 25 popular LVLMs reveal that many LVLMs' language priors are not strong enough to effectively aid question answering when objects are partially hidden. Many models, including GPT-4 Turbo, exhibit an accuracy below 0.5 in such a scenario.
ICT: Image-Object Cross-Level Trusted Intervention for Mitigating Object Hallucination in Large Vision-Language Models
Nov 22, 2024Despite the recent breakthroughs achieved by Large Vision Language Models (LVLMs) in understanding and responding to complex visual-textual contexts, their inherent hallucination tendencies limit their practical application in real-world scenarios that demand high levels of precision. Existing methods typically either fine-tune the LVLMs using additional data, which incurs extra costs in manual annotation and computational resources or perform comparisons at the decoding stage, which may eliminate useful language priors for reasoning while introducing inference time overhead. Therefore, we propose ICT, a lightweight, training-free method that calculates an intervention direction to shift the model's focus towards different levels of visual information, enhancing its attention to high-level and fine-grained visual details. During the forward pass stage, the intervention is applied to the attention heads that encode the overall image information and the fine-grained object details, effectively mitigating the phenomenon of overly language priors, and thereby alleviating hallucinations. Extensive experiments demonstrate that ICT achieves strong performance with a small amount of data and generalizes well across different datasets and models. Our code will be public.
BDetCLIP: Multimodal Prompting Contrastive Test-Time Backdoor Detection
May 24, 2024Multimodal contrastive learning methods (e.g., CLIP) have shown impressive zero-shot classification performance due to their strong ability to joint representation learning for visual and textual modalities. However, recent research revealed that multimodal contrastive learning on poisoned pre-training data with a small proportion of maliciously backdoored data can induce backdoored CLIP that could be attacked by inserted triggers in downstream tasks with a high success rate. To defend against backdoor attacks on CLIP, existing defense methods focus on either the pre-training stage or the fine-tuning stage, which would unfortunately cause high computational costs due to numerous parameter updates. In this paper, we provide the first attempt at a computationally efficient backdoor detection method to defend against backdoored CLIP in the inference stage. We empirically find that the visual representations of backdoored images are insensitive to both benign and malignant changes in class description texts. Motivated by this observation, we propose BDetCLIP, a novel test-time backdoor detection method based on contrastive prompting. Specifically, we first prompt the language model (e.g., GPT-4) to produce class-related description texts (benign) and class-perturbed random texts (malignant) by specially designed instructions. Then, the distribution difference in cosine similarity between images and the two types of class description texts can be used as the criterion to detect backdoor samples. Extensive experiments validate that our proposed BDetCLIP is superior to state-of-the-art backdoor detection methods, in terms of both effectiveness and efficiency.