 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttack by Unlearning: Unlearning-Induced Adversarial Attacks on Graph Neural Networks
Mar 19, 2026Graph neural networks (GNNs) are widely used for learning from graph-structured data in domains such as social networks, recommender systems, and financial platforms. To comply with privacy regulations like the GDPR, CCPA, and PIPEDA, approximate graph unlearning, which aims to remove the influence of specific data points from trained models without full retraining, has become an increasingly important component of trustworthy graph learning. However, approximate unlearning often incurs subtle performance degradation, which may incur negative and unintended side effects. In this work, we show that such degradations can be amplified into adversarial attacks. We introduce the notion of \textbf{unlearning corruption attacks}, where an adversary injects carefully chosen nodes into the training graph and later requests their deletion. Because deletion requests are legally mandated and cannot be denied, this attack surface is both unavoidable and stealthy: the model performs normally during training, but accuracy collapses only after unlearning is applied. Technically, we formulate this attack as a bi-level optimization problem: to overcome the challenges of black-box unlearning and label scarcity, we approximate the unlearning process via gradient-based updates and employ a surrogate model to generate pseudo-labels for the optimization. Extensive experiments across benchmarks and unlearning algorithms demonstrate that small, carefully designed unlearning requests can induce significant accuracy degradation, raising urgent concerns about the robustness of GNN unlearning under real-world regulatory demands. The source code will be released upon paper acceptance.
Query-Efficient Agentic Graph Extraction Attacks on GraphRAG Systems
Jan 21, 2026Graph-based retrieval-augmented generation (GraphRAG) systems construct knowledge graphs over document collections to support multi-hop reasoning. While prior work shows that GraphRAG responses may leak retrieved subgraphs, the feasibility of query-efficient reconstruction of the hidden graph structure remains unexplored under realistic query budgets. We study a budget-constrained black-box setting where an adversary adaptively queries the system to steal its latent entity-relation graph. We propose AGEA (Agentic Graph Extraction Attack), a framework that leverages a novelty-guided exploration-exploitation strategy, external graph memory modules, and a two-stage graph extraction pipeline combining lightweight discovery with LLM-based filtering. We evaluate AGEA on medical, agriculture, and literary datasets across Microsoft-GraphRAG and LightRAG systems. Under identical query budgets, AGEA significantly outperforms prior attack baselines, recovering up to 90% of entities and relationships while maintaining high precision. These results demonstrate that modern GraphRAG systems are highly vulnerable to structured, agentic extraction attacks, even under strict query limits.
iFlip: Iterative Feedback-driven Counterfactual Example Refinement
Jan 04, 2026Counterfactual examples are minimal edits to an input that alter a model's prediction. They are widely employed in explainable AI to probe model behavior and in natural language processing (NLP) to augment training data. However, generating valid counterfactuals with large language models (LLMs) remains challenging, as existing single-pass methods often fail to induce reliable label changes, neglecting LLMs' self-correction capabilities. To explore this untapped potential, we propose iFlip, an iterative refinement approach that leverages three types of feedback, including model confidence, feature attribution, and natural language. Our results show that iFlip achieves an average 57.8% higher validity than the five state-of-the-art baselines, as measured by the label flipping rate. The user study further corroborates that iFlip outperforms baselines in completeness, overall satisfaction, and feasibility. In addition, ablation studies demonstrate that three components are paramount for iFlip to generate valid counterfactuals: leveraging an appropriate number of iterations, pointing to highly attributed words, and early stopping. Finally, counterfactuals generated by iFlip enable effective counterfactual data augmentation, substantially improving model performance and robustness.
Every Step Evolves: Scaling Reinforcement Learning for Trillion-Scale Thinking Model
Oct 21, 2025



We present Ring-1T, the first open-source, state-of-the-art thinking model with a trillion-scale parameter. It features 1 trillion total parameters and activates approximately 50 billion per token. Training such models at a trillion-parameter scale introduces unprecedented challenges, including train-inference misalignment, inefficiencies in rollout processing, and bottlenecks in the RL system. To address these, we pioneer three interconnected innovations: (1) IcePop stabilizes RL training via token-level discrepancy masking and clipping, resolving instability from training-inference mismatches; (2) C3PO++ improves resource utilization for long rollouts under a token budget by dynamically partitioning them, thereby obtaining high time efficiency; and (3) ASystem, a high-performance RL framework designed to overcome the systemic bottlenecks that impede trillion-parameter model training. Ring-1T delivers breakthrough results across critical benchmarks: 93.4 on AIME-2025, 86.72 on HMMT-2025, 2088 on CodeForces, and 55.94 on ARC-AGI-v1. Notably, it attains a silver medal-level result on the IMO-2025, underscoring its exceptional reasoning capabilities. By releasing the complete 1T parameter MoE model to the community, we provide the research community with direct access to cutting-edge reasoning capabilities. This contribution marks a significant milestone in democratizing large-scale reasoning intelligence and establishes a new baseline for open-source model performance.
Bridging Source and Target Domains via Link Prediction for Unsupervised Domain Adaptation on Graphs
May 29, 2025Graph neural networks (GNNs) have shown great ability for node classification on graphs. However, the success of GNNs relies on abundant labeled data, while obtaining high-quality labels is costly and challenging, especially for newly emerging domains. Hence, unsupervised domain adaptation (UDA), which trains a classifier on the labeled source graph and adapts it to the unlabeled target graph, is attracting increasing attention. Various approaches have been proposed to alleviate the distribution shift between the source and target graphs to facilitate the classifier adaptation. However, most of them simply adopt existing UDA techniques developed for independent and identically distributed data to gain domain-invariant node embeddings for graphs, which do not fully consider the graph structure and message-passing mechanism of GNNs during the adaptation and will fail when label distribution shift exists among domains. In this paper, we proposed a novel framework that adopts link prediction to connect nodes between source and target graphs, which can facilitate message-passing between the source and target graphs and augment the target nodes to have ``in-distribution'' neighborhoods with the source domain. This strategy modified the target graph on the input level to reduce its deviation from the source domain in the embedding space and is insensitive to disproportional label distributions across domains. To prevent the loss of discriminative information in the target graph, we further design a novel identity-preserving learning objective, which guides the learning of the edge insertion module together with reconstruction and adaptation losses. Experimental results on real-world datasets demonstrate the effectiveness of our framework.
One-Shot Dual-Arm Imitation Learning
Mar 10, 2025
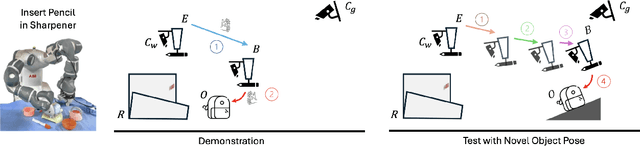
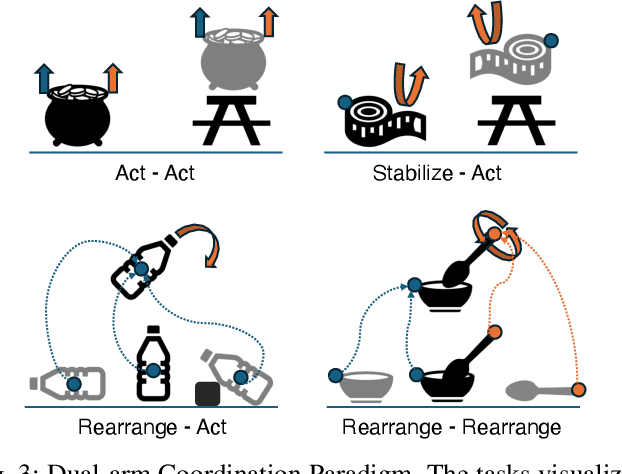

We introduce One-Shot Dual-Arm Imitation Learning (ODIL), which enables dual-arm robots to learn precise and coordinated everyday tasks from just a single demonstration of the task. ODIL uses a new three-stage visual servoing (3-VS) method for precise alignment between the end-effector and target object, after which replay of the demonstration trajectory is sufficient to perform the task. This is achieved without requiring prior task or object knowledge, or additional data collection and training following the single demonstration. Furthermore, we propose a new dual-arm coordination paradigm for learning dual-arm tasks from a single demonstration. ODIL was tested on a real-world dual-arm robot, demonstrating state-of-the-art performance across six precise and coordinated tasks in both 4-DoF and 6-DoF settings, and showing robustness in the presence of distractor objects and partial occlusions. Videos are available at: https://www.robot-learning.uk/one-shot-dual-arm.
Every FLOP Counts: Scaling a 300B Mixture-of-Experts LING LLM without Premium GPUs
Mar 07, 2025



In this technical report, we tackle the challenges of training large-scale Mixture of Experts (MoE) models, focusing on overcoming cost inefficiency and resource limitations prevalent in such systems. To address these issues, we present two differently sized MoE large language models (LLMs), namely Ling-Lite and Ling-Plus (referred to as "Bailing" in Chinese, spelled B\v{a}il\'ing in Pinyin). Ling-Lite contains 16.8 billion parameters with 2.75 billion activated parameters, while Ling-Plus boasts 290 billion parameters with 28.8 billion activated parameters. Both models exhibit comparable performance to leading industry benchmarks. This report offers actionable insights to improve the efficiency and accessibility of AI development in resource-constrained settings, promoting more scalable and sustainable technologies. Specifically, to reduce training costs for large-scale MoE models, we propose innovative methods for (1) optimization of model architecture and training processes, (2) refinement of training anomaly handling, and (3) enhancement of model evaluation efficiency. Additionally, leveraging high-quality data generated from knowledge graphs, our models demonstrate superior capabilities in tool use compared to other models. Ultimately, our experimental findings demonstrate that a 300B MoE LLM can be effectively trained on lower-performance devices while achieving comparable performance to models of a similar scale, including dense and MoE models. Compared to high-performance devices, utilizing a lower-specification hardware system during the pre-training phase demonstrates significant cost savings, reducing computing costs by approximately 20%. The models can be accessed at https://huggingface.co/inclusionAI.
LanP: Rethinking the Impact of Language Priors in Large Vision-Language Models
Feb 17, 2025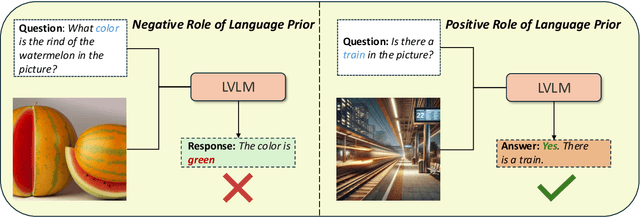
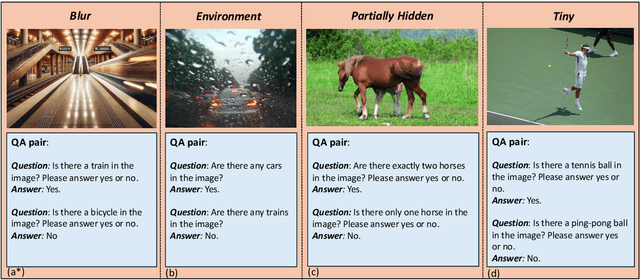
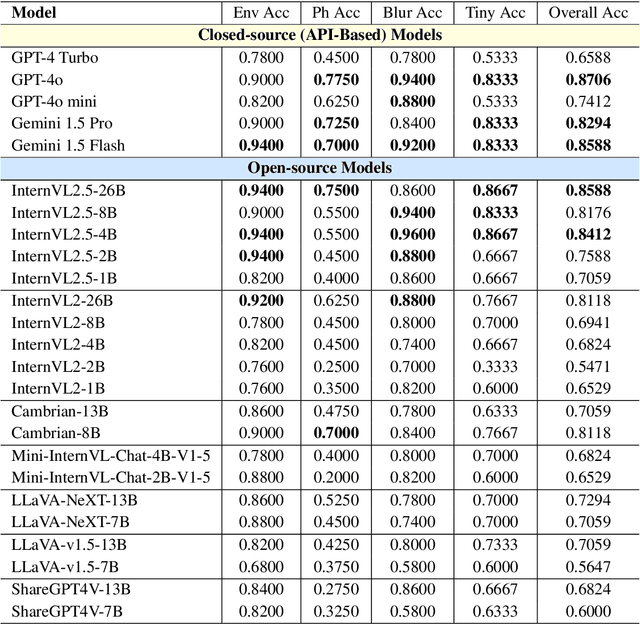
Large Vision-Language Models (LVLMs) have shown impressive performance in various tasks. However, LVLMs suffer from hallucination, which hinders their adoption in the real world. Existing studies emphasized that the strong language priors of LVLMs can overpower visual information, causing hallucinations. However, the positive role of language priors is the key to a powerful LVLM. If the language priors are too weak, LVLMs will struggle to leverage rich parameter knowledge and instruction understanding abilities to complete tasks in challenging visual scenarios where visual information alone is insufficient. Therefore, we propose a benchmark called LanP to rethink the impact of Language Priors in LVLMs. It is designed to investigate how strong language priors are in current LVLMs. LanP consists of 170 images and 340 corresponding well-designed questions. Extensive experiments on 25 popular LVLMs reveal that many LVLMs' language priors are not strong enough to effectively aid question answering when objects are partially hidden. Many models, including GPT-4 Turbo, exhibit an accuracy below 0.5 in such a scenario.
TAMT: Temporal-Aware Model Tuning for Cross-Domain Few-Shot Action Recognition
Nov 28, 2024



Going beyond few-shot action recognition (FSAR), cross-domain FSAR (CDFSAR) has attracted recent research interests by solving the domain gap lying in source-to-target transfer learning. Existing CDFSAR methods mainly focus on joint training of source and target data to mitigate the side effect of domain gap. However, such kind of methods suffer from two limitations: First, pair-wise joint training requires retraining deep models in case of one source data and multiple target ones, which incurs heavy computation cost, especially for large source and small target data. Second, pre-trained models after joint training are adopted to target domain in a straightforward manner, hardly taking full potential of pre-trained models and then limiting recognition performance. To overcome above limitations, this paper proposes a simple yet effective baseline, namely Temporal-Aware Model Tuning (TAMT) for CDFSAR. Specifically, our TAMT involves a decoupled paradigm by performing pre-training on source data and fine-tuning target data, which avoids retraining for multiple target data with single source. To effectively and efficiently explore the potential of pre-trained models in transferring to target domain, our TAMT proposes a Hierarchical Temporal Tuning Network (HTTN), whose core involves local temporal-aware adapters (TAA) and a global temporal-aware moment tuning (GTMT). Particularly, TAA learns few parameters to recalibrate the intermediate features of frozen pre-trained models, enabling efficient adaptation to target domains. Furthermore, GTMT helps to generate powerful video representations, improving match performance on the target domain. Experiments on several widely used video benchmarks show our TAMT outperforms the recently proposed counterparts by 13%$\sim$31%, achieving new state-of-the-art CDFSAR results.
Trojan Prompt Attacks on Graph Neural Networks
Oct 17, 2024



Graph Prompt Learning (GPL) has been introduced as a promising approach that uses prompts to adapt pre-trained GNN models to specific downstream tasks without requiring fine-tuning of the entire model. Despite the advantages of GPL, little attention has been given to its vulnerability to backdoor attacks, where an adversary can manipulate the model's behavior by embedding hidden triggers. Existing graph backdoor attacks rely on modifying model parameters during training, but this approach is impractical in GPL as GNN encoder parameters are frozen after pre-training. Moreover, downstream users may fine-tune their own task models on clean datasets, further complicating the attack. In this paper, we propose TGPA, a backdoor attack framework designed specifically for GPL. TGPA injects backdoors into graph prompts without modifying pre-trained GNN encoders and ensures high attack success rates and clean accuracy. To address the challenge of model fine-tuning by users, we introduce a finetuning-resistant poisoning approach that maintains the effectiveness of the backdoor even after downstream model adjustments. Extensive experiments on multiple datasets under various settings demonstrate the effectiveness of TGPA in compromising GPL models with fixed GNN encoders.