 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkin-R1: Toward Trustworthy Clinical Reasoning for Dermatological Diagnosis
Nov 18, 2025The emergence of vision-language models (VLMs) has opened new possibilities for clinical reasoning and has shown promising performance in dermatological diagnosis. However, their trustworthiness and clinical utility are often limited by three major factors: (1) Data heterogeneity, where diverse datasets lack consistent diagnostic labels and clinical concept annotations; (2) Absence of grounded diagnostic rationales, leading to a scarcity of reliable reasoning supervision; and (3) Limited scalability and generalization, as models trained on small, densely annotated datasets struggle to transfer nuanced reasoning to large, sparsely-annotated ones. To address these limitations, we propose SkinR1, a novel dermatological VLM that combines deep, textbook-based reasoning with the broad generalization capabilities of reinforcement learning (RL). SkinR1 systematically resolves the key challenges through a unified, end-to-end framework. First, we design a textbook-based reasoning generator that synthesizes high-fidelity, hierarchy-aware, and differential-diagnosis (DDx)-informed trajectories, providing reliable expert-level supervision. Second, we leverage the constructed trajectories for supervised fine-tuning (SFT) empowering the model with grounded reasoning ability. Third, we develop a novel RL paradigm that, by incorporating the hierarchical structure of diseases, effectively transfers these grounded reasoning patterns to large-scale, sparse data. Extensive experiments on multiple dermatology datasets demonstrate that SkinR1 achieves superior diagnostic accuracy. The ablation study demonstrates the importance of the reasoning foundation instilled by SFT.
Bridging Source and Target Domains via Link Prediction for Unsupervised Domain Adaptation on Graphs
May 29, 2025Graph neural networks (GNNs) have shown great ability for node classification on graphs. However, the success of GNNs relies on abundant labeled data, while obtaining high-quality labels is costly and challenging, especially for newly emerging domains. Hence, unsupervised domain adaptation (UDA), which trains a classifier on the labeled source graph and adapts it to the unlabeled target graph, is attracting increasing attention. Various approaches have been proposed to alleviate the distribution shift between the source and target graphs to facilitate the classifier adaptation. However, most of them simply adopt existing UDA techniques developed for independent and identically distributed data to gain domain-invariant node embeddings for graphs, which do not fully consider the graph structure and message-passing mechanism of GNNs during the adaptation and will fail when label distribution shift exists among domains. In this paper, we proposed a novel framework that adopts link prediction to connect nodes between source and target graphs, which can facilitate message-passing between the source and target graphs and augment the target nodes to have ``in-distribution'' neighborhoods with the source domain. This strategy modified the target graph on the input level to reduce its deviation from the source domain in the embedding space and is insensitive to disproportional label distributions across domains. To prevent the loss of discriminative information in the target graph, we further design a novel identity-preserving learning objective, which guides the learning of the edge insertion module together with reconstruction and adaptation losses. Experimental results on real-world datasets demonstrate the effectiveness of our framework.
Deep Learning within Tabular Data: Foundations, Challenges, Advances and Future Directions
Jan 07, 2025Tabular data remains one of the most prevalent data types across a wide range of real-world applications, yet effective representation learning for this domain poses unique challenges due to its irregular patterns, heterogeneous feature distributions, and complex inter-column dependencies. This survey provides a comprehensive review of state-of-the-art techniques in tabular data representation learning, structured around three foundational design elements: training data, neural architectures, and learning objectives. Unlike prior surveys that focus primarily on either architecture design or learning strategies, we adopt a holistic perspective that emphasizes the universality and robustness of representation learning methods across diverse downstream tasks. We examine recent advances in data augmentation and generation, specialized neural network architectures tailored to tabular data, and innovative learning objectives that enhance representation quality. Additionally, we highlight the growing influence of self-supervised learning and the adaptation of transformer-based foundation models for tabular data. Our review is based on a systematic literature search using rigorous inclusion criteria, encompassing 127 papers published since 2020 in top-tier conferences and journals. Through detailed analysis and comparison, we identify emerging trends, critical gaps, and promising directions for future research, aiming to guide the development of more generalizable and effective tabular data representation methods.
Enhance Graph Alignment for Large Language Models
Oct 15, 2024



Graph-structured data is prevalent in the real world. Recently, due to the powerful emergent capabilities, Large Language Models (LLMs) have shown promising performance in modeling graphs. The key to effectively applying LLMs on graphs is converting graph data into a format LLMs can comprehend. Graph-to-token approaches are popular in enabling LLMs to process graph information. They transform graphs into sequences of tokens and align them with text tokens through instruction tuning, where self-supervised instruction tuning helps LLMs acquire general knowledge about graphs, and supervised fine-tuning specializes LLMs for the downstream tasks on graphs. Despite their initial success, we find that existing methods have a misalignment between self-supervised tasks and supervised downstream tasks, resulting in negative transfer from self-supervised fine-tuning to downstream tasks. To address these issues, we propose Graph Alignment Large Language Models (GALLM) to benefit from aligned task templates. In the self-supervised tuning stage, we introduce a novel text matching task using templates aligned with downstream tasks. In the task-specific tuning stage, we propose two category prompt methods that learn supervision information from additional explanation with further aligned templates. Experimental evaluations on four datasets demonstrate substantial improvements in supervised learning, multi-dataset generalizability, and particularly in zero-shot capability, highlighting the model's potential as a graph foundation model.
HC-GST: Heterophily-aware Distribution Consistency based Graph Self-training
Jul 25, 2024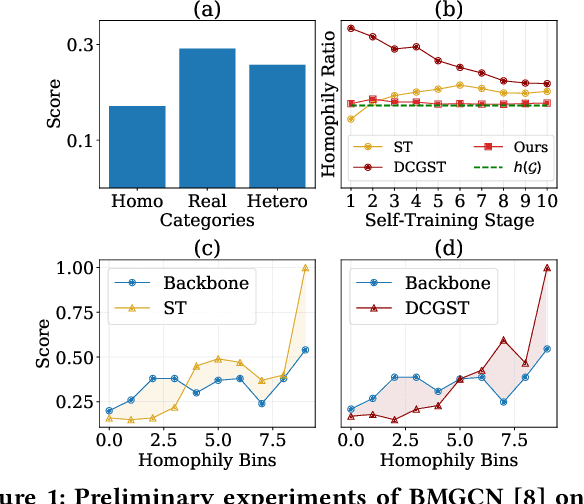
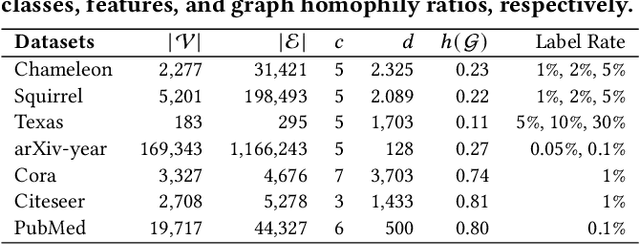
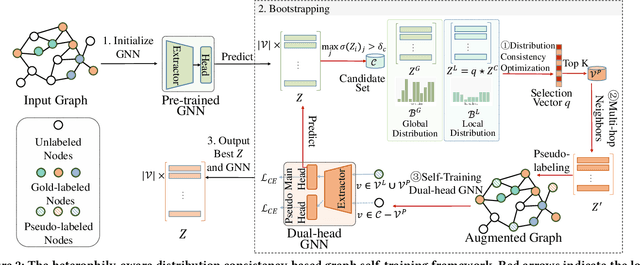
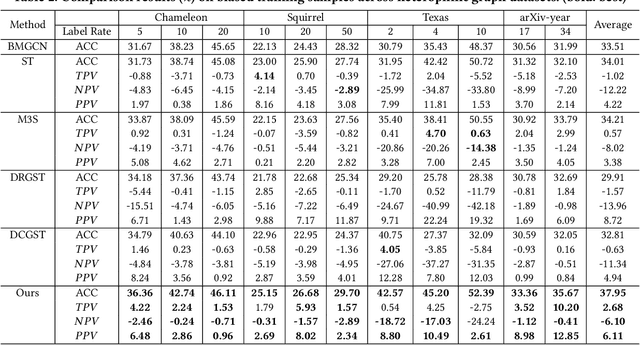
Graph self-training (GST), which selects and assigns pseudo-labels to unlabeled nodes, is popular for tackling label sparsity in graphs. However, recent study on homophily graphs show that GST methods could introduce and amplify distribution shift between training and test nodes as they tend to assign pseudo-labels to nodes they are good at. As GNNs typically perform better on homophilic nodes, there could be potential shifts towards homophilic pseudo-nodes, which is underexplored. Our preliminary experiments on heterophilic graphs verify that these methods can cause shifts in homophily ratio distributions, leading to \textit{training bias} that improves performance on homophilic nodes while degrading it on heterophilic ones. Therefore, we study a novel problem of reducing homophily ratio distribution shifts during self-training on heterophilic graphs. A key challenge is the accurate calculation of homophily ratios and their distributions without extensive labeled data. To tackle them, we propose a novel Heterophily-aware Distribution Consistency-based Graph Self-Training (HC-GST) framework, which estimates homophily ratios using soft labels and optimizes a selection vector to align pseudo-nodes with the global homophily ratio distribution. Extensive experiments on both homophilic and heterophilic graphs show that HC-GST effectively reduces training bias and enhances self-training performance.
Enhancing Data-Limited Graph Neural Networks by Actively Distilling Knowledge from Large Language Models
Jul 19, 2024Graphs have emerged as critical data structures for content analysis in various domains, such as social network analysis, bioinformatics, and recommendation systems. Node classification, a fundamental task in this context, is typically tackled using graph neural networks (GNNs). Unfortunately, conventional GNNs still face challenges in scenarios with few labeled nodes, despite the prevalence of few-shot node classification tasks in real-world applications. To address this challenge, various approaches have been proposed, including graph meta-learning, transfer learning, and methods based on Large Language Models (LLMs). However, traditional meta-learning and transfer learning methods often require prior knowledge from base classes or fail to exploit the potential advantages of unlabeled nodes. Meanwhile, LLM-based methods may overlook the zero-shot capabilities of LLMs and rely heavily on the quality of generated contexts. In this paper, we propose a novel approach that integrates LLMs and GNNs, leveraging the zero-shot inference and reasoning capabilities of LLMs and employing a Graph-LLM-based active learning paradigm to enhance GNNs' performance. Extensive experiments demonstrate the effectiveness of our model in improving node classification accuracy with considerably limited labeled data, surpassing state-of-the-art baselines by significant margins.
Analyzing and Reducing Catastrophic Forgetting in Parameter Efficient Tuning
Feb 29, 2024Existing research has shown that large language models (LLMs) exhibit remarkable performance in language understanding and generation. However, when LLMs are continuously fine-tuned on complex and diverse domain-specific downstream tasks, the inference performance on historical tasks decreases dramatically, which is known as a catastrophic forgetting problem. A trade-off needs to be kept between learning plasticity and memory stability. Plenty of existing works have explored strategies like memory replay, regularization and parameter isolation, but little is known about the geometric connection of various adjacent minima in the continual LLMs fine-tuning scenarios. In this work, we investigate the geometric connections of different minima through the lens of mode connectivity, which means different minima can be connected by a low-loss valley. Through extensive experiments, we uncover the mode connectivity phenomenon in the LLMs continual learning scenario and find that it can strike a balance between plasticity and stability. Building upon these findings, we propose a simple yet effective method called Interpolation-based LoRA (I-LoRA), which constructs a dual-memory experience replay framework based on LoRA parameter interpolations. Extensive experiments and analysis on eight domain-specific CL benchmarks demonstrate that I-LoRA consistently show significant improvement over the previous state-of-the-art approaches with up to $11\%$ performance gains, providing a strong baseline and insights for future research on the large language model continual learning problem. Our code is available at \url{https://github.com/which47/LLMCL}.
Disambiguated Node Classification with Graph Neural Networks
Feb 13, 2024Graph Neural Networks (GNNs) have demonstrated significant success in learning from graph-structured data across various domains. Despite their great successful, one critical challenge is often overlooked by existing works, i.e., the learning of message propagation that can generalize effectively to underrepresented graph regions. These minority regions often exhibit irregular homophily/heterophily patterns and diverse neighborhood class distributions, resulting in ambiguity. In this work, we investigate the ambiguity problem within GNNs, its impact on representation learning, and the development of richer supervision signals to fight against this problem. We conduct a fine-grained evaluation of GNN, analyzing the existence of ambiguity in different graph regions and its relation with node positions. To disambiguate node embeddings, we propose a novel method, {\method}, which exploits additional optimization guidance to enhance representation learning, particularly for nodes in ambiguous regions. {\method} identifies ambiguous nodes based on temporal inconsistency of predictions and introduces a disambiguation regularization by employing contrastive learning in a topology-aware manner. {\method} promotes discriminativity of node representations and can alleviating semantic mixing caused by message propagation, effectively addressing the ambiguity problem. Empirical results validate the efficiency of {\method} and highlight its potential to improve GNN performance in underrepresented graph regions.
Distribution Consistency based Self-Training for Graph Neural Networks with Sparse Labels
Jan 18, 2024



Few-shot node classification poses a significant challenge for Graph Neural Networks (GNNs) due to insufficient supervision and potential distribution shifts between labeled and unlabeled nodes. Self-training has emerged as a widely popular framework to leverage the abundance of unlabeled data, which expands the training set by assigning pseudo-labels to selected unlabeled nodes. Efforts have been made to develop various selection strategies based on confidence, information gain, etc. However, none of these methods takes into account the distribution shift between the training and testing node sets. The pseudo-labeling step may amplify this shift and even introduce new ones, hindering the effectiveness of self-training. Therefore, in this work, we explore the potential of explicitly bridging the distribution shift between the expanded training set and test set during self-training. To this end, we propose a novel Distribution-Consistent Graph Self-Training (DC-GST) framework to identify pseudo-labeled nodes that are both informative and capable of redeeming the distribution discrepancy and formulate it as a differentiable optimization task. A distribution-shift-aware edge predictor is further adopted to augment the graph and increase the model's generalizability in assigning pseudo labels. We evaluate our proposed method on four publicly available benchmark datasets and extensive experiments demonstrate that our framework consistently outperforms state-of-the-art baselines.
T-SaS: Toward Shift-aware Dynamic Adaptation for Streaming Data
Sep 05, 2023



In many real-world scenarios, distribution shifts exist in the streaming data across time steps. Many complex sequential data can be effectively divided into distinct regimes that exhibit persistent dynamics. Discovering the shifted behaviors and the evolving patterns underlying the streaming data are important to understand the dynamic system. Existing methods typically train one robust model to work for the evolving data of distinct distributions or sequentially adapt the model utilizing explicitly given regime boundaries. However, there are two challenges: (1) shifts in data streams could happen drastically and abruptly without precursors. Boundaries of distribution shifts are usually unavailable, and (2) training a shared model for all domains could fail to capture varying patterns. This paper aims to solve the problem of sequential data modeling in the presence of sudden distribution shifts that occur without any precursors. Specifically, we design a Bayesian framework, dubbed as T-SaS, with a discrete distribution-modeling variable to capture abrupt shifts of data. Then, we design a model that enable adaptation with dynamic network selection conditioned on that discrete variable. The proposed method learns specific model parameters for each distribution by learning which neurons should be activated in the full network. A dynamic masking strategy is adopted here to support inter-distribution transfer through the overlapping of a set of sparse networks. Extensive experiments show that our proposed method is superior in both accurately detecting shift boundaries to get segments of varying distributions and effectively adapting to downstream forecast or classification tasks.